一、 Kafka原理:
- 关于kafka分区与parititon
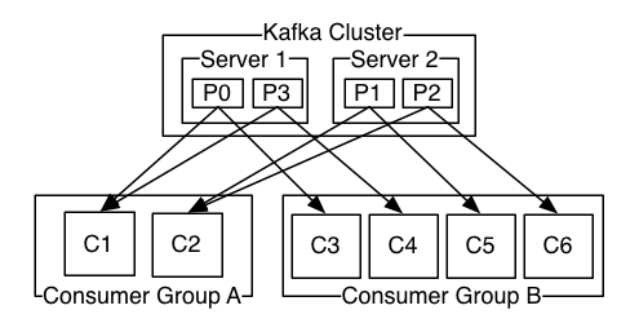
如上图:一个topic 可以配置几个partition(集群时每台机器上都存储了一些Partition,也就存放了Topic的一部分数据,这样就实现了Topic的数据分布式存储在一个Broker集群上),produce发送的消息分发到不同的partition中,consumer接受数据的时候是按照group来接受,kafka确保每个partition只能同一个group中的同一个consumer消费,如果想要重复消费,那么需要其他的组来消费。Zookeerper中保存这每个topic下的每个partition在每个group中消费的offset ;
因此
如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。如果想多个不同的业务都需要这个topic的数据,起多个consumer group就好了,大家都是顺序的读取message,offsite的值互不影响。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。
如果要一个group用几个consumer来同时读取的话,需要多线程来读取,一个线程相当于一个consumer实例。当consumer的数量大于分区的数量的时候,有的consumer线程会读取不到数据
示例:
@KafkaListener(topics={“my-test-topic”},groupId=”group-1”)
publicvoidlisten(ConsumerRecord<?,?>record){
@KafkaListener(topics={“my-test-topic”},groupId=”group-2”)
publicvoidlisten2(ConsumerRecord<?,?>record){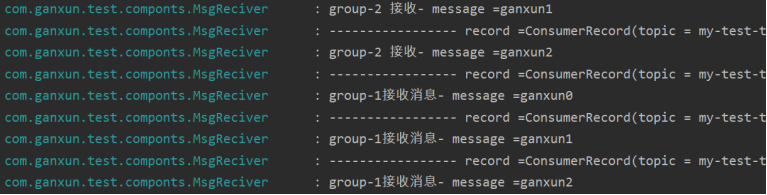
2. 分区与副本同步:
假设一个Topic拆分为了3个Partition,分别是Partition0,Partiton1,Partition2,此时每个Partition都有2个副本;其实任何一个Partition,只有Leader是对外提供读写服务的,也就是说,如果有一个客户端往一个Partition写入数据,此时一般就是写入这个Partition的Leader副本。
然后Leader副本接收到数据之后,Follower副本会不停的给他发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中
在kafka官方文档中有如下一句话
http://kafka.apache.org/24/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html:
The acks config controls the criteria under which requests are considered complete. The “all” setting we have specified will result in blocking on the full commit of the record, the slowest but most durable setting
说的是如下的设置:
props.put(“acks”, “all”);
为什么设置成all是最慢但是最稳妥的方式乃?
acks参数有三种选择:0、1 和 all,主要是KafkaProducer设置副本同步,与kafka内部副本机制、同步机制有关。
a. acks参数设置为0,意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了;
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了
b. 第二种选择是设置 acks = 1,意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了;
这种设置其实是kafka默认的设置,大家请注意。也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。
c. 最后一种情况,就是设置acks=all,这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR(In-Sync Replicas”,也就是保持同步的副本)列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了;
3. 组内分区:
a) 什么是rebalance?
rebalance本质上是一种协议,规定了一个consumer group下的所有consumer如何达成一致来分配订阅topic的每个分区。比如某个group下有20个consumer,它订阅了一个具有100个分区的topic。正常情况下,Kafka平均会为每个consumer分配5个分区。这个分配的过程就叫rebalance。
b) 什么时候rebalance?
官方文档:
Membership in a consumer group is maintained dynamically: if a process fails, the partitions assigned to it will be reassigned to other consumers in the same group. Similarly, if a new consumer joins the group, partitions will be moved from existing consumers to the new one. This is known as rebalancing the group and is discussed in more detail below. Group rebalancing is also used when new partitions are added to one of the subscribed topics or when a new topic matching a subscribed regex is created. The group will automatically detect the new partitions through periodic metadata refreshes and assign them to members of the group.
意思是rebalance的触发条件有三种:
1) 组成员发生变更(新consumer加入组、已有consumer主动离开组或已有consumer崩溃了——这两者的区别后面会谈到)
2) 订阅主题数发生变更——这当然是可能的,如果你使用了正则表达式的方式进行订阅,那么新建匹配正则表达式的topic就会触发rebalance
3) 订阅主题的分区数发生变更
c) 如何进行组内分区分配?
之前提到了group下的所有consumer都会协调在一起共同参与分配,这是如何完成的?Kafka新版本consumer默认提供了两种分配策略:range和round-robin。当然Kafka采用了可插拔式的分配策略,你可以创建自己的分配器以实现不同的分配策略。实际上,由于目前range和round-robin两种分配器都有一些弊端,Kafka社区已经提出第三种分配器来实现更加公平的分配策略,只是目前还在开发中。我们这里只需要知道consumer group默认已经帮我们把订阅topic的分区分配工作做好了就行了。
简单举个例子,假设目前某个consumer group下有两个consumer: A和B,当第三个成员加入时,kafka会触发rebalance并根据默认的分配策略重新为A、B和C分配分区,如下图所示: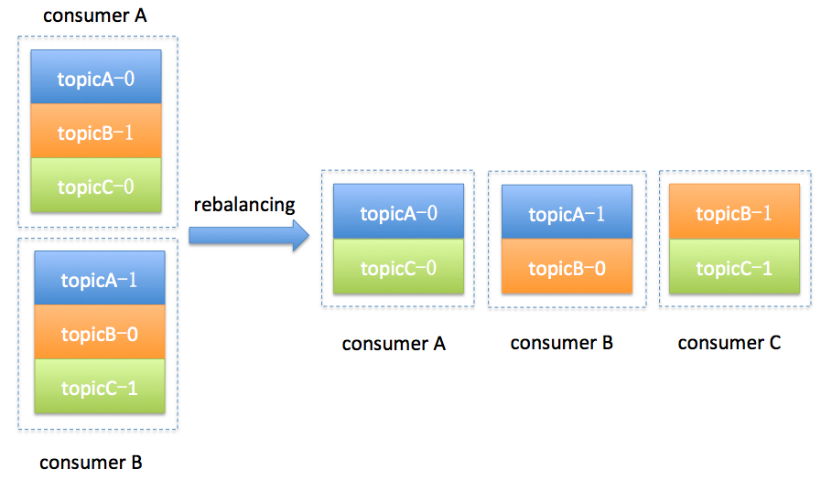
d) 关于consumer 分组与reblance这篇博客写得很好,但是这部分内容在官网也有描述,结合看会比较好:
https://www.cnblogs.com/huxi2b/p/6223228.html
4. Consume手动提交和自动提交注意的一个点:
Using automatic offset commits can also give you “at-least-once” delivery, but the requirement is that you must consume all data returned from each call to poll(Duration) before any subsequent calls, or before closing the consumer. If you fail to do either of these, it is possible for the committed offset to get ahead of the consumed position, which results in missing records. The advantage of using manual offset control is that you have direct control over when a record is considered “consumed.”
大概意思是,当因为当我们在每次拉取数据后,还有后续操作时(如操作数据库),这种情况如果操作发生失败,自动提交有可能导致offset超前,这是因为自动提交是在kafka拉取到数据之后就直接提交,这样很容易丢失数据,尤其是在需要事物控制的时候。
重点:手动提交在大部分应用场景都不是很合适
5. 手动分区(Manual Partition Assignment)
自动分区时:assign a fair share of the partitions for those topics based on the active consumers in the group(公平的分区)
但是有时候我们需要某个consumer只监听一个分区的消息,比如:
If the process is maintaining some kind of local state associated with that partition (like a local on-disk key-value store), then it should only get records for the partition it is maintaining on disk.
If the process itself is highly available and will be restarted if it fails (perhaps using a cluster management framework like YARN, Mesos, or AWS facilities, or as part of a stream processing framework). In this case there is no need for Kafka to detect the failure and reassign the partition since the consuming process will be restarted on another machine.
通过asign可以完成手动分区设置(详细见官网):
String topic = “foo”;
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
spring-boot中使用如下方式手动指定分区:<br />@KafkaListener(topicPartitions = {@TopicPartition(topic = "my-test-topic", partitions = { "2", "3" })})<br />只能指定静态的分区组;<br />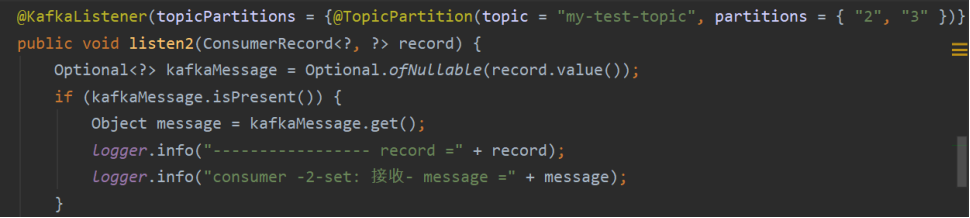
二、 应用搭建:
| 配置文件 关于springboot-kafka的配置可以参考如下文档: https://docs.spring.io/spring-boot/docs/current/reference/html/appendix-application-properties.html#common-application-properties 章节:8. Integration properties,里面有解释,不懂在百度; kafka指令大全: https://www.orchome.com/454 不懂的指令可以用指令 —describe进行查看 如下文章。Springboot-kafka异步发送 https://github.com/Snailclimb/springboot-kafka/blob/master/docs/3-10%E5%88%86%E9%92%9F%E5%AD%A6%E4%BC%9A%E5%A6%82%E4%BD%95%E5%9C%A8SpringBoot%E7%A8%8B%E5%BA%8F%E4%B8%AD%E4%BD%BF%E7%94%A8Kafka%E4%BD%9C%E4%B8%BA%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97.md @kafkaListener作用于class上时,需要配置需要注意的是需要StringJsonMessageConverter(可以在config配置类中); 问题汇总: EBUG [org.apache.kafka.clients.NetworkClient] - Error connecting to node 2 at kafka-cluster-64bit:9094 在java配置 bootstrap-servers: 192.168.153.128:9092 ,这个IP要和服务器上kafka的listener配置要相同 listeners=PLAINTEXT://192.168.153.128:9092 如果在liunx中配置了host的名字,192.168.153.128 ganxun-centos,则如果在bootstrap-servers配置时如果配置成了对应的hostname,则需要修改本地客户端的(windows)的host的文件做IP映射,在测试环境或者生产建议用IP; |
|---|
| 简单消息发送: java消费消息 @Component public class MsgReciver { private static Logger logger = LoggerFactory.getLogger(MsgReciver.class); @KafkaListener(topics = {“my-test-topic”}) public void listen(ConsumerRecord<?, ?> record) { Optional<?> kafkaMessage = Optional.ofNullable(record.value()); if (kafkaMessage.isPresent()) { Object message = kafkaMessage.get(); logger.info(“————————- record =” + record); logger.info(“————————— message =” + message); } } java生产消息 @Component public class MsgProducer { private static Logger logger = LoggerFactory.getLogger(MsgProducer.class); @Autowired private KafkaTemplate //发送消息方法 public void send() { for(int i=0;i<5;i++){ kafkaTemplate.send(“my-test-topic”, gson.toJson(“msg”)); } } 对象消息: @RequestMapping(“message/sendObject”) public String sendObject(){ for(int i=0;i<5;i++){ Message message = new Message(“9992999”,”ganxun”); kafkaTemplate.send(“my-test-topic”, gson.toJson(message)); } return “success”; } 主要需要了解@KafkaListener、kafkaTemplate就可以搭建一个应用 从KafkaTemplate 的定义可以看到,采用key,value形式,理论上可以发送各种对象 public class KafkaTemplate 另外: spring-kafka提供了两种发送操作类:KafkaTemplate及ReplyingKafkaTemplate。前者为普通发送者,后者可以同步接收消费者的回复消息。(这一个没写demo程序了,看如果以后需要再深入研究一下) 同一consumer多个分组消费消息(可以 消费pruducer发布到consumer中的消息): 在注解中增加分组信息: @KafkaListener(topics={“my-test-topic”},groupId=”group-1”) 多个Consumer 消费消息(写个demo): @KafkaListener用于class,可以根据对象类型进入不同的KafkaHander; 详细例子见github: https://github.com/spring-projects/spring-kafka/tree/master/samples; |
| @KafkaListener(id = “multi”, topics = “myTopic”) static class MultiListenerBean { @KafkaHandler public void listen(String foo) { } @KafkaHandler public void listen(Integer bar) { } @KafkaHandler(isDefault = true) public void listenDefault(Object object) { } } |
@Bean public RecordMessageConverter converter() { StringJsonMessageConverter converter = new StringJsonMessageConverter(); DefaultJackson2JavaTypeMapper typeMapper = new DefaultJackson2JavaTypeMapper(); typeMapper.setTypePrecedence(TypePrecedence.TYPE_ID); typeMapper.addTrustedPackages(“com.common”); Map mappings.put(“foo”, Foo2.class); mappings.put(“bar”, Bar2.class); typeMapper.setIdClassMapping(mappings); converter.setTypeMapper(typeMapper); return converter; } |
关于配置springboot-kafka的配置一些其他说明:
1. kafka的auto.offset.reset允许我们设置kafka中没有初始offset或当前offset没有存储在服务器时的初始消费方式,一般我们设置为earliest:当分区中存在已消费的offset时,从当前位置开始消费;不存在时,从头拉取,此种方式防止我们晚于生产者进入消费,从而导致丢失消息。
关于offset,在官方文档中描述的意思是,每次消费者消费了partiton里面的一条消息后,offset会自动加1,记录下一次在partiton里面需要取的record。
2. Listener于adviser listener:
listeners: 学名叫监听器,其实就是告诉外部连接者要通过什么协议访问指定主机名和端口开放的 Kafka 服务。
advertised.listeners:和 listeners 相比多了个 advertised。Advertised 的含义表示宣称的、公布的,就是说这组监听器是 Broker 用于对外发布的
在内网部署及访问kafka时,只需要配置listeners参数即可
listeners=PLAINTEXT://192.168.133.11:9092 意思是通过这个ip端口获取kafka服务
在内网部署kafka服务,并且生产者或者消费者在外网环境时,需要添加额外的配置,比如
advertised.listeners=INTERNAL://192.168.133.11:9092,EXTERNAL://<公网ip>:<端口>
内外Ip做个映射;
三、 Topic
- 手动创建topic(可以在配置类中注册)
@Bean
public NewTopic foos() {
return new NewTopic(“foos”, 1, (short) 1); // 分区为1,副本数为1的topic
}
2. NewTopic 同样可以用于修改分区设置;
3. 死信主题(Dead Letter topic):
i. Spring-kafka内部封装了可重试消费消息的语义,也就是可以设置为当消费数据出现异常时,重试这个消息。而且可以设置重试达到多少次后,让消息进入预定好的Topic;
ii. 默认情况下,错误处理程序会跟踪失败的记录,在10次传递尝试后放弃并记录失败的记录。但是,我们也可以将失败的消息发送到另一个主题。我们称之为死信主题
iii. 配置死信主题需要重载spring-kafka默认配置的配置容器工厂:
在配置类中:
| @Bean public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory( ConcurrentKafkaListenerContainerFactoryConfigurer configurer, ConsumerFactory KafkaTemplate ConcurrentKafkaListenerContainerFactory configurer.configure(factory, kafkaConsumerFactory); factory.setErrorHandler(new SeekToCurrentErrorHandler( new DeadLetterPublishingRecoverer(template), 3)); return factory; } |
|---|
监听死信主题:
@KafkaListener(id = “dltGroup”, topics = “testTopic.DLT”)
public void dltListen(String input) {
logger.info(“Received from DLT: “ + input);
}
死信主题规则:
监听testTopic主题的监听器在处理业务逻辑时如果触发运行时异常,监听器会重新尝试三次调用,当到达最大的重试次数后。消息就会被丢掉重试死信队列里面去。死信队列的Topic的规则是,业务Topic名字+“.DLT”。如上面业务Topic的name为“testTopic”,那么对应的死信队列的Topic就是“testTopic.DLT”
四、 关于生产者Producer
- 生成这客户端架构:
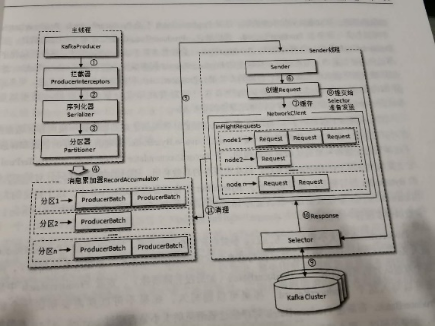
2.
3. 关于batch.size:
4. 消息发送有三种模式:
a) 发送即忘(fire-and-forget)
直接调用send函数发送,不处理回调即为发送即忘
producer.send(record);
b) 同步
Producer.send().get(),虽然send是异步,但是会被get函数阻塞
Futurefuture = producer.send(record);
future.get()
c) 异步:
producer.send(record, new Callback(){});
一般kafka不是单条发送消息,而是一次发送多条消息,发送完成后需要通过close函数来释放资源(producer.close())
5. 异常:
a) 可重试异常(可设置重试次数,retries_config):NetWorkException/leaderNotAvailableException…
b) 不可重试异常:
6. 可自定义producer的分区器(指定消息根据什么算法发送到分区)、拦截器(拦截不符合要求的消息,修改消息内容)等
五、 Consumer 多线程
- Consumer是非线程安全的(The Kafka consumer is NOT thread-safe):
我们需要保证多线程访问的同步性,否则会抛ConcurrentModificationException异常
2. Springboot 可以参考如下博客:
https://blog.csdn.net/allensandy/article/details/89636444;
实践了一下,上面链接这篇文章的实现有问题,它文章中的思想其实都是要几个consumer就建立几个线程,只是在消费record的时候第二种方式再建立线程进行消费;
文章中还有一个问题就是没有解决kafka consumer不允许多线程访问的问题,
使用ThreadLocal可以解决这个问题(相当于每个线程独用一个consumer),使用ThreadLocal要注意线程退出或结束时调用remove方法避免内存泄漏:
| // by ganxun KafkaConsumer if (null == consumer){ consumer = new KafkaConsumer consumer.subscribe(Arrays.asList(“test-topic”)); thradLocal.set(consumer); } |
|---|
- 同步提交与异步提交:
l 同步提交:commitSync()方法会提交由poll()方法返回的最新偏移量,提交成功后马上返回,否则跑出异常。
我们处理消息的逻辑可以变成这样:
while (true) {
ConsumerRecords
for (ConsumerRecord
System.out.printf(“offset = %d, key = %s, value = %s%n”, record.offset(), record.key(), record.value());
try {
consumer.commitSync();
} catch (Exception e) {
System.out.println(“commit failed”);
}
}
}
l 异步提交:
while (true) {
ConsumerRecords
for (ConsumerRecord
System.out.printf(“offset = %d, key = %s, value = %s%n”, record.offset(), record.key(), record.value());
}
consumer.commitAsync();
}
六、 关于kafka分区:
每个主题的默认日志分区数。更多分区允许更大并行处理消息,但这也会导致更多的文件
num.partitions = 1
在启动时用于日志恢复和在关闭时刷新的每个数据目录文件夹需要的线程数。
#对于数据目录文件夹位于RAID阵列中的情况,建议增加此线程数值。
num.recovery.threads.per.data.dir = 1
如下一篇文章总结得很好:
越多的分区可以提供更高的吞吐量
越多的分区需要打开更多地文件句柄
更多地分区会导致更高的不可用性
越多的分区可能增加端对端的延迟
越多的partition意味着需要客户端需要更多的内存
文章地址:
https://blog.csdn.net/WuLex/article/details/80934437
Demo
调整已经创建的topic的分区,我创建的my-test-topic只有一个分区,创建指令如下:
./kafka-topics.sh —create —zookeeper 192.168.153.128:2181 —replication-factor 1 —partitions 1 —topic my-test-topic
修改partition:
./kafka-topics.sh —alter —zookeeper 192.168.153.128:2181 —topic my-test-topic—partitions 4
指令执行成功后,java应用再创建一个consumer(同一个group组中可以放多个consumer):
启动应用,查看执行效果:
执行效果:
七、 关于日志(消息载体):
- Kafka日志存储:
l Kafka日志实现的压缩方式是将多条消息一起进行压缩,这样做是为了保证压缩效果(数据量越大压缩效果越好).
l 一般情况下,生产者发送的消息数据是在broker中也是保持压缩状态的
l 消费者从服务端拉取的消息也是压缩的消息,消费者在处理消息之前才会解压消息,保证了端到端的压缩;
l 通过compression.type 可以设置日志压缩方式;
2. Kafka提供了两种日志清理策略:
(1) 日志删除:按照一定的保留策略直接删除不符合条件的日志分段;
在kafka的日志管理器中会有一个专门的日志删除任务来周期性的检测和删除不符合条件的日志分段文件,这个周期可以通过log.retention.checki.interval.ms来设置(默认是5分钟)。
1. 基于时间
日志删除任务会检查当前日志文件中是否有保留时间超过设定的阈值retentionMs来寻找可删除的的日志分段文件集合deletableSegments,参考下图所示。retentionMs可以通过broker端参数log.retention.hours、log.retention.minutes以及log.retention.ms来配置,其中log.retention.ms的优先级最高,log.retention.minutes次之,log.retention.hours最低。默认情况下只配置了log.retention.hours参数,其值为168,故默认情况下日志分段文件的保留时间为7天
(2) 日志压缩:针对每个消息key进行整合,对于有相同的key的不同value。只保留一个版本;
我们可以通过设置broker端参数log.cleanup.policy 来设置日志清理策略,此参数默认是delete(compact对应压缩策略)
日志删除任务会检查当前日志的大小是否超过设定的阈值retentionSize来寻找可删除的日志分段的文件集合deletableSegments,参考下图所示。retentionSize可以通过broker端参数log.retention.bytes来配置,默认值为-1,表示无穷大。注意log.retention.bytes配置的是日志文件的总大小,而不是单个的日志分段的大小,一个日志文件包含多个日志分段
(3) 日志清理策略参考:
https://blog.csdn.net/u013256816/article/details/80418297
3. Kafka日志刷新政策配置
Kafka消息立即写入文件系统,但默认情况下我们只有fsync()来缓慢延迟地同步操作系统缓存消息到磁盘上。 以下配置参数控制将消息数据刷新到磁盘过程。这里有一些重要的权衡:
1、持久性:如果Kafka不使用复制,则可能会丢失未刷新的数据。
2、延迟:当Kafka刷新确实发生时,非常大的刷新间隔可能会导致延迟峰值,因为会有大量数据需要刷新到磁盘,间隔太久缓冲消息越多。
3、吞吐量:Flush通常是最昂贵的操作,并且小的Flush间隔可能导致过多的磁盘IO操作搜索。
下面以下设置允许配置刷新策略以在一段时间后或每N条消息(或两者)刷新数据。这可以在全局范围内配置完成,也可以针对每个主题的单独配置。
#强制刷新数据到磁盘之前要接受的消息数,10000消息时批量刷盘
#log.flush.interval.messages = 10000
#强制刷新之前消息可以在日志中停留的最长时间 1000毫秒
#log.flush.interval.ms = 1000
八、 关于批量消息处理:
spring-kafka的官方文档介绍,可以知道自1.1版本之后,@KafkaListener开始支持批量消费,只需要设置batchListener参数为true;
配置文件中:
可以通过spring.kafka.listener.type=batch开启批量消费。
可以通过spring.kafka.consumer.max-poll-recrods来修改每次拉取的消息。默认为500。
可以通过spring.kafka.listener.concurrency来修改同时消费的监听器。
a. batch.size和linger.ms(linger:暂缓,增加发送延迟时间)是对kafka producer性能影响比较大的两个参数。batch.size是producer批量发送的基本单位,默认是16384Bytes,即16kB;lingger.ms是sender线程在检查batch是否ready时候,判断有没有过期的参数,默认大小是0ms;
关于linger.ms,官方文档写到:
however setting this to something larger than 0 can lead to fewer, more efficient requests when not under maximal load at the cost of a small amount of latency;
producer是按照batch.size大小批量发送消息呢,还是按照linger.ms的时间间隔批量发送消息呢?其实满足batch.size和ling.ms之一,producer便开始发送消息;
b. 幂等发送(the idempotent producer)和事务发送(transactional producer)
什么是幂等?
举个例子:比如用户对订单付款之后,生成了一个付款成功的消息,发送给了订单系统,订单系统接收到消息之后,将订单状态为已付款,后来,订单系统又收到了一个发货成功的消息,再将订单状态更新为已发货,但是由于网络或者是系统的原因,订单系统再次收到了之前的付款成功的消息,也就是消息重复了,这个在现象在实际应用中也经常出现。订单系统的处理是,查询数据库,发现这个订单状态为已发货,然后不再更改订单状态。这时候,我们可以说订单处理消息的接口是幂等的,如果订单再次将状态更新为已付款,接口就是非幂等的。
为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
PID:当每个新的Producer在初始化的时候,会分配一个唯一的PID,这个PID对用户是不可见的。
Sequence Numbler:(对于每个PID,该Producer发送数据的每个
Broker端在缓存中保存了这Sequence Numbler,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。这样就可以实现了消息重复提交了。但是,只能保证单个Producer对于同一个
九、 关于springboot中的kafka“事务”
springboot官网中关于kafka的描述有这么一段:
If the property spring.kafka.producer.transaction-id-prefix is defined, a KafkaTransactionManager is automatically configured. Also, if a RecordMessageConverter bean is defined, it is automatically associated to the auto-configured KafkaTemplate.<https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.html#boot-features-kafka-extra-props>
说明spring-kafka支持某种“事务”:
事务是Kafka 0.11开始引入的新特性。类似于数据库事务,只是这里的数据源是Kafka,kafka事务属性是指一系列的生产者生产消息和消费者提交offset的操作在一个事务,或者说是是一个原子操作),同时成功或者失败;
数据库事务的是针对于数据库的ACID属性。而消息系统的事务则是针对消息生产/消费的原则操作。两者为不同的数据源,不可混为一谈。
我们使用kafka消息事务的场景有以下两种:
· 在一次业务中,存在消费消息,又存在生产消息。此时如果消息生产失败,那么消费者需要回滚。这种情况称为consumer-transform-producer
· 在一次业务中,存在多次生产消息,其中后续生产的消息抛出异常,前置生产的消息需要回滚。
· .最简单的需求是producer发的多条消息组成一个事务这些消息需要对consumer同时可见或者同时不可见
· producer可能会给多个topic,多个partition发消息,这些消息也需要能放在一个事务里面,这就形成了一个典型的分布式事务
· kafka的应用场景经常是应用先消费一个topic,然后做处理再发到另一个topic,这个consume-transform-produce过程需要放到一个事务里面,比如在消息处理或者发送的过程中如果失败了,消费位点也不能提交
· producer或者producer所在的应用可能会挂掉,新的producer启动以后需要知道怎么处理之前未完成的事务
· 流式处理的拓扑可能会比较深,如果下游只有等上游消息事务提交以后才能读到,可能会导致rt非常长吞吐量也随之下降很多,所以需要实现read committed和read uncommitted两种事务隔离级别
· spring-kafka提供了一种同步链事务,可以允许kafka数据源事务与其他数据源结合,要么一起成功,要么一起失败。可以通过ChainedKafkaTransactionManager来实现。
spring-kafka提供了spring.kafka.producer.transaction-id-prefix属性开启事务,仅需要配置事务前缀,并且在所有涉及到kafka操作及监听的方法上增加@Transcational注解。
注意:spring-kafka的事务是针对单示例的,即每个@Transcational所标识的方法均会创建一个事务,并且生成一个事务id。
配置(yml):
spring:
kafka:
producer:
transaction-id-prefix: test-transacation
· isolatetion.level: kafka事务隔离级别:
read_committed 和read_uncommitted,与事务有着莫大的冠梁,这个参数的默认值是“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。
这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息;kafkComsumer 通过这个控制消息(contrlBatch)来判断对应的事务是中止还是提交,并结合isolatetion.level的配置决定是否将消息返回给消费端应用。
在spring-boot 中的配置文件或者配置类设置consumer时可以配置。
· 关于事务还可以参考这篇博客:
https://blog.csdn.net/lzufeng/article/details/81975501
demo:
配置文件中加入transaction-id-prefix: test-transacation ,代表使用事务
@RequestMapping(“message/send”)
@Transactional
publicvoidsend(){
Map
msg.put(“ge”,”gg”);
for(inti=0;i<10;i++){
kafkaTemplate.send(“my-test-topic”,”ganxun”+i);//使用kafka模板发送信息
if(i==5){
thrownewRuntimeException(“fail”);
}
}
}
从如下输出可以看到,消费者没有消费到任务消息,虽然异常是当i==5的时候产生的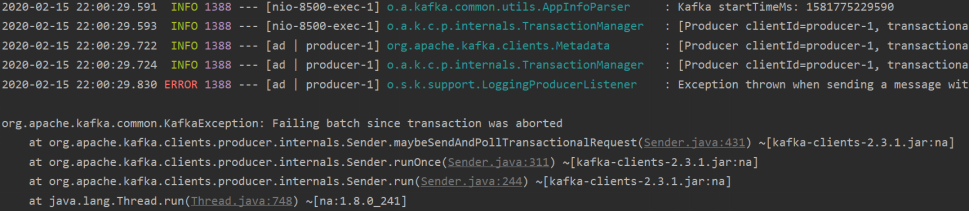
十、 关于kafka消息的运维
- Topic管理:
a) Topic配置:
kafka-config 相对于 kafka-topics 而言, 在配置修改方面做得更全面,用户可以指定 config 的 对象 : topic, client, user or broker.:
创建topic之后通过config.sh文件对其中的特定指标进行修改:
| /kafka-configs.sh —zookeeper localhost:2181 —entity-type topics —entity-name my-topic —alter —add-config max.message.bytes=128000 |
|---|
b) 修改主题:
kafka-configs.sh + alter实现:
./kafka-topics.sh —alter —zookeeper 192.168.153.128:2181 —topic my-test-topic—partitions 4
关于kafka-topics.sh可以查看官方文档:
http://kafka.apache.org/documentation/#topicconfigs
c) 优先副本选举:
优先副本的选举是指通过一定的方式促使优先副本选举为leader副本,以此来促进集群的负载均衡,这一行为也可以称为分区平衡
Kafka提供分区自动平衡的功能,与此对应的broker参数是auto.leader.rebalance.enable,此参数的默认值为true,默认情况下此功能是开启的。如果开启分区自动平衡的功能,则Kafka的控制器会启动一个定时任务,这个定时任务会轮询所有的broker节点,计算每个broker节点的分区不平衡率(broker中的不平衡率=非优先副本的leader个数/分区总数)是否超过leader.imbalance.per.broker.percentage参数配置的比值,默认值为10%,如果超过设定的比值则会自动执行优先副本的选举动作以求分区平衡。执行周期由参数leader.imbalance.check.interval.seconds控制,默认值为300秒,即5分钟
Kafka中kafka-preferred-replica-election.sh脚本提供了对分区leader副本进行重新平衡的功能。优先副本的选举过程是一个安全的过程,Kafka客户端可以自动感知分区leader副本的变更
[root@localhost bin]# ./kafka-preferred-replica-election.sh —zookeeper localhost:2181
[root@localhost bin]# ./kafka-topics.sh —zookeeper localhost:2181 —describe —topic topic-partitions
Topic:topic-partitions PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic-partitions Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 2,1,0
Topic: topic-partitions Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 2,1,0
Topic: topic-partitions Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
上面这种方式会将集群上所有的分区都执行一遍优先副本的选举操作,分区数越多打印出来的信息也就越多。leader副本的转移是一项高成本的工作,如果要执行的分区数很多,那么必然会对客户端造成一定的影响。在优先副本的选举过程中,具体的元数据信息会被存入ZooKeeper的/admin/preferred_replica_election节点,如果这些数据超过了ZooKeeper节点所允许的大小,那么选举就会失败。默认情况下ZooKeeper所允许的节点数据大小为1MB
kafka-preferred-replica-election.sh脚本还提供了path-to-json-file参数来小批量地对部分分区执行优先副本的选举操作。通过path-to-json-file参数来指定一个JSON文件,这个JSON文件里保存需要执行优先副本选举的分区清单
只想对主题topic-partitions执行优先副本的选举操作,先创建一个JSON文件,文件名为election.json,内容如下:
{
“partitions”: [{
“partition”: 0,
“topic”: “topic-partitions”
},
{
“partition”: 1,
“topic”: “topic-partitions”
},
{
“partition”: 2,
“topic”: “topic-partitions”
}
]
}
2. 手动维护分区:
新添加的Kafka节点并不会自动地分配数据,所以无法分担集群的负载,除非我们新建一个topic。但是现在我们想手动将部分分区移到新添加的Kafka节点上,Kafka内部提供了相关的工具来重新分布某个topic的分区:
kafka-reassign-partitions.sh;
a) 新建topics-to-move.json;
b) 然后使用kafka-reassign-partitions.sh工具生成reassign plan:
bin/kafka-reassign-partitions.sh —zookeeper www.iteblog.com:2181 —topics-to-move-json-file topics-to-move.json —broker-list “1,2,3,4,5” –generate
生成如下:
c) 将上一步生成的建议分区保存在一个json文件中,如result.json,并执行:
bin/kafka-reassign-partitions.sh —zookeeper www.iteblog.com:2181 —reassignment-json-file result.json –execute
d) 这样Kafka就在执行reassign plan,我们可以校验reassign plan是否执行完成:
bin/kafka-reassign-partitions.sh —zookeeper www.iteblog.com:2181 —reassignment-json-file result.json –verify
我实践了一下这个操作,成功后如下:
e) 使用kafka-reassign-partitions.sh工具生成的reassign plan只是一个建议,方便大家而已。其实我们自己完全可以编辑一个reassign plan
f) 参考:https://www.iteblog.com/archives/1611.html
3. 设置consumer分区策略:
Partion.assignment.strategy:
三种分区策略:
RangeAssignor(默认):按照消费者总数和分区总数进行整除运算得到一个跨度,然后按照这个跨度进行平均分配,以保证每个分区尽可能分配给所有的消费者;
RoundRobinAssignor: 将消费者组内的所有消费者及消费者订阅的所有主题分区按照字典进行排序,然后通过轮询的方式逐个将分区依次分配给每个消费者
StrickAssignor:尽可能分区均匀,分区尽可能与上次分配的保持一致,如果不能保持一致则尽量保持均匀;(比较好的一种策略,在实际工程汇中可以尝试)
4. Kafka可视化工具介绍:
l 下载地址:
http://www.kafkatool.com/download.html
l 使用(创建连接(IP端口),随便输入一个集群名称)
十一、 关于消息消费的准确性
- 如何保证消息不被重复消费
2. 如何保证消息不丢失
3. 这部分后面再研究

若有收获,就点个赞吧
0 人点赞
