一 介绍
1、memcached & redis是什么?
NoSQl数据库,数据存到内存,读取速度快应用场景:页面缓存,好处如下1、减少数据库压力,提升访问速度2、在数据挂掉的情况下,仍能保证业务正常运行一段时间,提升安全性
2、memcached与redis区别
#1、类型:memcached:类型单一,只能存字符串"key为字符串"="value也为字符串"redis:支持五大类型string(字符串)list(链表)set(集合)zset(sorted set --有序集合)hash(哈希类型)#2、持久化:memcached:断电数据丢失redis:支持持久化,单独开一个进程完成持久化,要保持性能就需要关闭持久化,很多公司并不使用持久化功能
3、memcached并未过时
文档:https://www.oschina.net/news/26691/memcached-timeout
二 安装与基本操作
1、Redis安装
#1、官网:https://redis.io/#2、redis默认不正式支持windows,到这里下载windows版本https://github.com/MicrosoftArchive/redis/releases
2、命令行基本操作
#1、命令行链接redis-cliredis-cli -h host -p port -a password#2、基本操作默认有16个数据库,编号从0-15select 1 #切换到1号库keys * #查看所有的keykeys n* #查看所有n开头的keyflushdb #清空redisset key value #添加key=valuerandomkey #随机取出一个keytype key #查看key的类型
3、在Python中的两种链接方式
方式一:
#redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。import redisclient=redis.Redis(host='127.0.0.1',port=6379)client.set('name','egon')v= client.get('name')print(v,type(v)) #b'egon' <class 'bytes'>
方式二:
#redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。import redispool=redis.ConnectionPool(host='127.0.0.1',port=6379,max_connections=100)client=redis.Redis(connection_pool=pool)client.set('name','egon')v= client.get('name')print(v,type(v)) #b'egon' <class 'bytes'>
4、选择数据库
import redispool=redis.ConnectionPool(host='127.0.0.1',port=6379,max_connections=100)client=redis.Redis(connection_pool=pool)client.execute_command('select 1') #选择数据库
三 常用操作
1、String 操作

#1、set(name, value, ex=None, px=None, nx=False, xx=False)在Redis中设置值,默认,不存在则创建,存在则修改参数:ex,过期时间(秒)px,过期时间(毫秒)nx,如果设置为True,则只有name不存在时,当前set操作才执行xx,如果设置为True,则只有name存在时,岗前set操作才执行#2、setnx(name, value)设置值,只有name不存在时,执行设置操作(添加)#3、setex(name, value, time)设置值参数:time,过期时间(数字秒 或 timedelta对象)#4、psetex(name, time_ms, value)设置值参数:time_ms,过期时间(数字毫秒 或 timedelta对象)#5、mset(*args, **kwargs)批量设置值如:mset(k1='v1', k2='v2')或mset({'k1': 'v1', 'k2': 'v2'})#6、get(name)获取值#7、mget(keys, *args)批量获取如:mget('k1', 'k2')或r.mget(['k1', 'k2'])#8、getset(name, value)设置新值并获取原来的值#9、getrange(key, start, end)获取子序列(根据字节获取,非字符)参数:name,Redis 的 namestart,起始位置(字节)end,结束位置(字节)如: "林海峰" ,0-2表示 "林"#10、setrange(name, offset, value)修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)参数:offset,字符串的索引,字节(一个汉字三个字节)value,要设置的值
client.set(‘name’,’林海峰’) client.setrange(‘name’,3,’大海’) print(client.get(‘name’).decode(‘utf-8’)) #林大海
#11、strlen(name)返回name对应值的字节长度(一个汉字3个字节)#12、incr(self, name, amount=1)自增 name="1" 对应的值,当name不存在时,则创建name=amount,否则,则自增。参数:name,Redis的nameamount,自增数(必须是整数)注:同incrby#13、incrbyfloat(self, name, amount=1.0)自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。参数:name,Redis的nameamount,自增数(浮点型)#14、decr(self, name, amount=1)自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。参数:name,Redis的nameamount,自减数(整数)#15、append(key, value)在redis name对应的值后面追加内容参数:key, redis的namevalue, 要追加的字符串
2、Hash 操作
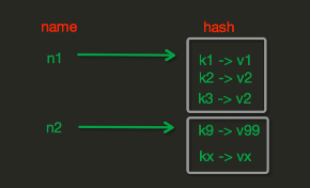
#1、hset(name, key, value)name对应的hash中设置一个键值对(不存在,则创建;否则,修改)参数:name,redis的namekey,name对应的hash中的keyvalue,name对应的hash中的value注:hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)#2、hmset(name, mapping)在name对应的hash中批量设置键值对参数:name,redis的namemapping,字典,如:{'k1':'v1', 'k2': 'v2'}如:r.hmset('xx', {'k1':'v1', 'k2': 'v2'})#3、hget(name,key)在name对应的hash中获取根据key获取value#4、hmget(name, keys, *args)在name对应的hash中获取多个key的值参数:name,reids对应的namekeys,要获取key集合,如:['k1', 'k2', 'k3']*args,要获取的key,如:k1,k2,k3如:r.mget('xx', ['k1', 'k2'])或print r.hmget('xx', 'k1', 'k2')#5、hgetall(name)获取name对应hash的所有键值#6、hlen(name)获取name对应的hash中键值对的个数#7、hkeys(name)获取name对应的hash中所有的key的值#8、hvals(name)获取name对应的hash中所有的value的值#9、hexists(name, key)# 检查name对应的hash是否存在当前传入的key#10、hdel(name,*keys)将name对应的hash中指定key的键值对删除#11、hincrby(name, key, amount=1)自增name对应的hash中的指定key的值,不存在则创建key=amount参数:name,redis中的namekey, hash对应的keyamount,自增数(整数)#12、hincrbyfloat(name, key, amount=1.0)自增name对应的hash中的指定key的值,不存在则创建key=amount参数:name,redis中的namekey, hash对应的keyamount,自增数(浮点数)自增name对应的hash中的指定key的值,不存在则创建key=amount#13、hscan(name, cursor=0, match=None, count=None)增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆参数:name,redis的namecursor,游标(基于游标分批取获取数据)match,匹配指定key,默认None 表示所有的keycount,每次分片最少获取个数,默认None表示采用Redis的默认分片个数如:第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)...直到返回值cursor的值为0时,表示数据已经通过分片获取完毕#14、hscan_iter(name, match=None, count=None)利用yield封装hscan创建生成器,实现分批去redis中获取数据参数:match,匹配指定key,默认None 表示所有的keycount,每次分片最少获取个数,默认None表示采用Redis的默认分片个数如:for item in r.hscan_iter('xx'):print item#15、补充scan(match=None, count=None)一点一点查出当前库下的所有的keys,详细请看如下文档http://redisdoc.com/key/scan.html#scan
3、List 操作
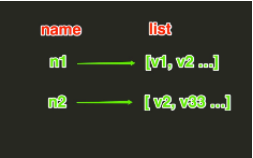
#1、lpush(name,values)在name对应的list中添加元素,每个新的元素都添加到列表的最左边如:r.lpush('oo', 11,22,33)保存顺序为: 33,22,11扩展:rpush(name, values) 表示从右向左操作#2、lpushx(name,value)在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边更多:rpushx(name, value) 表示从右向左操作#3、llen(name)name对应的list元素的个数#4、linsert(name, where, refvalue, value))在name对应的列表的某一个值前或后插入一个新值参数:name,redis的namewhere,BEFORE或AFTERrefvalue,标杆值,即:在它前后插入数据value,要插入的数据#5、r.lset(name, index, value)对name对应的list中的某一个索引位置重新赋值参数:name,redis的nameindex,list的索引位置value,要设置的值#6、r.lrem(name, value, num)在name对应的list中删除指定的值参数:name,redis的namevalue,要删除的值num, num=0,删除列表中所有的指定值;num=2,从前到后,删除2个;num=-2,从后向前,删除2个#7、lpop(name)在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素更多:rpop(name) 表示从右向左操作#8、lindex(name, index)在name对应的列表中根据索引获取列表元素#9、lrange(name, start, end)在name对应的列表分片获取数据参数:name,redis的namestart,索引的起始位置end,索引结束位置#10、ltrim(name, start, end)在name对应的列表中移除没有在start-end索引之间的值参数:name,redis的namestart,索引的起始位置end,索引结束位置#11、rpoplpush(src, dst)从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边参数:src,要取数据的列表的namedst,要添加数据的列表的name#12、blpop(keys, timeout)keys=["k1","k2"],按照从左到右去pop对应列表的元素参数:keys,redis的name的集合timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞举例:client.flushdb()client.lpush('list1',11,22,33) #33,22,11client.lpush('list2','a','b','c') #c b a
print(client.blpop([“list1”,”list2”])) #先从左侧取干净list1,再从左侧取干净list2,…,阻塞 print(client.blpop([“list1”,”list2”])) print(client.blpop([“list1”,”list2”])) print(client.blpop([“list1”,”list2”])) print(client.blpop([“list1”,”list2”])) print(client.blpop([“list1”,”list2”])) print(client.blpop([“list1”,”list2”],timeout=3)) #阻塞3秒,返回None
更多:r.brpop(keys, timeout),从右向左获取数据#13、brpoplpush(src, dst, timeout=0)从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧参数:src,取出并要移除元素的列表对应的namedst,要插入元素的列表对应的nametimeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞#14、自定义增量迭代由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:1、获取name对应的所有列表2、循环列表但是,如果列表非常大,那么就有可能在第一步时就将程序的内存撑爆,所有有必要自定义一个增量迭代的功能:def list_iter(name):"""自定义redis列表增量迭代:param name: redis中的name,即:迭代name对应的列表:return: yield 返回 列表元素"""list_count = r.llen(name)for index in range(list_count):yield r.lindex(name, index)# 使用for item in list_iter('list1'):print(item)
4、Set 操作
Set操作,Set集合就是不允许重复的列表#1、sadd(name,values)name对应的集合中添加元素#2、scard(name)获取name对应的集合中元素个数#3、sdiff(keys, *args)在第一个name对应的集合中且不在其他name对应的集合的元素集合#4、sdiffstore(dest, keys, *args)获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中#5、sinter(keys, *args)获取多一个name对应集合的并集#6、sinterstore(dest, keys, *args)获取多一个name对应集合的并集,再讲其加入到dest对应的集合中#7、sismember(name, value)检查value是否是name对应的集合的成员#8、smembers(name)获取name对应的集合的所有成员#9、smove(src, dst, value)将某个成员从一个集合中移动到另外一个集合#10、spop(name)从集合的右侧(尾部)移除一个成员,并将其返回#11、srandmember(name, numbers)从name对应的集合中随机获取 numbers 个元素#12、srem(name, values)在name对应的集合中删除某些值#13、sunion(keys, *args)获取多一个name对应的集合的并集#14、sunionstore(dest,keys, *args)获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中#15、sscan(name, cursor=0, match=None, count=None)#16、sscan_iter(name, match=None, count=None)同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
5、Sort Set 操作
#1、zadd(name, *args, **kwargs)在name对应的有序集合中添加元素如:zadd('score', 'alex', 50, 'wxx', 60,'yxx', 70)或zadd('score', alex=50, wxx=60, yxx=70)#2、zcard(name)获取name对应的有序集合元素的数量#3、zcount(name, min, max)获取name对应的有序集合中分数在 [min,max] 之间的个数#4、zincrby(name, value, amount)自增name对应的有序集合的 name 对应的分数#5、r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)按照索引范围获取name对应的有序集合的元素参数:name,redis的namestart,有序集合索引起始位置(非负数)end,有序集合索引结束位置(非负数)desc,排序规则,默认按照分数从小到大排序withscores,是否获取元素的分数,默认只获取元素的值score_cast_func,对分数进行数据转换的函数例如:client.zrange('score', 0, 2, desc=True, withscores=True, score_cast_func=int)结果:[(b'yxx', 70), (b'wxx', 60), (b'alex', 50)]更多:从大到小排序zrevrange(name, start, end, withscores=False, score_cast_func=float)
按照分数范围获取name对应的有序集合的元素 zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) 从大到小排序 zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
#6、zrank(name, value)获取某个值在 name对应的有序集合中的排行(从 0 开始)更多:zrevrank(name, value),从大到小排序#7、zrangebylex(name, min, max, start=None, num=None)当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大参数:name,redis的namemin,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间min,右区间(值)start,对结果进行分片处理,索引位置num,对结果进行分片处理,索引后面的num个元素如:ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 gar.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca']更多:从大到小排序zrevrangebylex(name, max, min, start=None, num=None)#8、zrem(name, values)删除name对应的有序集合中值是values的成员如:zrem('zz', ['s1', 's2'])#9、zremrangebyrank(name, min, max)根据排行范围删除#10、zremrangebyscore(name, min, max)根据分数范围删除#11、zremrangebylex(name, min, max)根据值返回删除#12、zscore(name, value)获取name对应有序集合中 value 对应的分数#13、zinterstore(dest, keys, aggregate=None)获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作aggregate的值为: SUM MIN MAX例如:client.flushdb()client.zadd('score1', 'alex', 50, 'wxx', 60,'yxx', 70)client.zadd('score2', 'alex', 60, 'wxx', 60,)#先求名字的交集,再对同一名字对应的值进行SUM聚合操作client.zinterstore('score_sum',keys=['score1','score2'],aggregate="SUM")print(client.zscore('score_sum','alex')) #110.0print(client.zscore('score_sum','wxx')) #120.0print(client.zscore('score_sum','yxx')) #None#14、zunionstore(dest, keys, aggregate=None)获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作aggregate的值为: SUM MIN MAX#15、zscan(name, cursor=0, match=None, count=None, score_cast_func=float)#16、zscan_iter(name, match=None, count=None,score_cast_func=float)同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
6、其他常用操作
#1、delete(*names)根据name删除redis中的任意数据类型#2、exists(name)检测redis的name是否存在#3、keys(pattern='*')根据模型获取redis的name更多:KEYS * 匹配数据库中所有 key 。KEYS h?llo 匹配 hello , hallo 和 hxllo 等。KEYS h*llo 匹配 hllo 和 heeeeello 等。KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo#4、expire(name ,time)为某个redis的某个name设置超时时间#5、rename(src, dst)对redis的name重命名为#6、move(name, db))将redis的某个值移动到指定的db下#7、randomkey()随机获取一个redis的name(不删除)#8、type(name)获取name对应值的类型#9、scan(cursor=0, match=None, count=None)#10、scan_iter(match=None, count=None)同字符串操作,用于增量迭代获取key
7、管道
#1、默认情况下是执行一个操作就向服务端提交一次
#2、可以将一系列操作放入一个管道内,然后一次性提交给服务端,这样做有效地减少开销
#3、transaction=True代表多个操作构成一个事务(原子性操作)
import redis
pool=redis.ConnectionPool(host='127.0.0.1',port=6379,max_connections=100)
client=redis.Redis(connection_pool=pool)
pipe=client.pipeline(transaction=True)
pipe.set('name','alex')
pipe.set('role','sb')
pipe.execute()
8、发布订阅
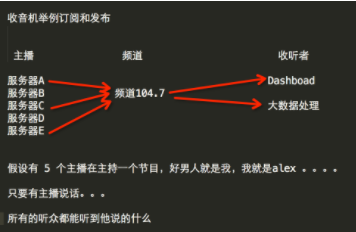
# monitor.py
import redis
class RedisHelper:
def init(self): self.__conn = redis.Redis(host=’127.0.0.1’,port=6379) self.chan_pub = ‘fm97.8’ #发布信息的频道名 self.chan_sub = ‘fm97.8’ #订阅信息的频道名
def public(self, msg): self.__conn.publish(self.chan_pub, msg) #向发布频道发布消息 return True
def subscribe(self): pub = self.__conn.pubsub() #拿到pub对象 pub.subscribe(self.chan_sub) #向订阅频道请求消息 pub.parse_response() #解析响应的信息 return pub
订阅者们
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from monitor import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg = redis_sub.parse_response()
print(msg)
发布者们
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from monitor import RedisHelper
import time
obj = RedisHelper()
while True:
obj.public('hello1')
time.sleep(5)

若有收获,就点个赞吧
0 人点赞
