2、go语言基础:context、mutex;如果context没有取消会怎么办?(消耗系统资源,可能造成协程泄露)
context:
- 传递共享的数据
- 取消goroutine
- 防止goroutine 泄露
多个 Goroutine 同时订阅 ctx.Done() 管道中的消息,一旦接收到取消信号就立刻停止当前正在执行的工作。
在Google 内部,我们开发了 Context 包,专门用来简化 对于处理单个请求的多个 goroutine 之间与请求域的数据、取消信号、截止时间等相关操作,这些操作可能涉及多个 API 调用。
https://zhuanlan.zhihu.com/p/68792989
- mutex: 正常模式,饥饿模式
- RWmutex: 可以并发读
- waitGroup:等待一组goroutine 的返回,比如批量发出的http请求
CAS
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-sync-primitives/
4、怎么学习go语言;go语言踩过的坑
看博客
8、协程、进程、线程;切换的具体内容,开销
- 进程是资源分配的基本单位,每个进程都有自己独立的内存空间,进程间的通信通过IPC完成,但是进程上下文切换比较大。
- 线程是进程的一个实体,是内核态的,是CPU调度分配的基本单位,它拥有的系统资源很少,但是它可以共享同一个进程中的资源。
- 协程是用户态的轻量级线程,协程调度完全由用户控制,拥有自己的寄存器,上下文和栈,基本没有内核切换的开销
协程通过在线程中实现调度,避免了陷入内核级别的上下文切换造成的性能损失,进而突破了线程在IO上的性能瓶颈。
协程本质上来说是一种用户态的线程,不需要系统来执行抢占式调度,而是在语言测个面实现线程的调度。
10、协程调度相关:协程会不会一直运行导致其他协程饥饿;什么情况下产生调度
使有协程阻塞,该线程的其他协程也可以被runtime调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
GMP
g 对应 goroutine 协程
M 对应 内核线程 物理核心数
P 对应逻辑核心数
12、docker用过吗
13、王者荣耀,10亿用户积分,取前十
14、原地反转byte数组,“i am on duty today” — > “today duty on am i”
15、linux查看进程CPU占用率,内存占用率,端口号占用,磁盘占用
16、最多创建文件描述符个数(1024,ulimit)Linux下ulimit最多可以设置多少
18、TCP,UDP区别
19、挥手过程
20、close_wait
21、1次1字节,1024次,会发生什么情况(结合tcp拥塞控制)
22、go语言UDP数据包用什么函数接收
23、抓过包吗
24、如果文件描述符的限制是4个字节,这种情况下最大连接数是多少
25、客户端怎么提高并发连接数
26、UDP发送1024字节,buffer只设置64,怎么处理(会显示数据包过大,接收失败)
27、io多路复用
28、epoll的ET和LT
总结:挺重视基础知识的,而且网络这块问了比较多的实际操作内容
https://gobea.cn/blog/detail/RoRgEO63.html
一面(后端 +区块链, 部分)
介绍一下项目
你有研究过区块链吗,研究过哪个方向?
微支付通道的概念,实现,缺点
Mysql 的内部数据结构?
什么是死锁?死锁产生的原因(四大条件)?举个例子?
手写一下二分排序
有写过 solidity?solidity 中遇到的技术问题?简单举例解释一下?
C++ 有学过吗?C++存储区有哪三种?程序执行中栈区的变化,具体一点,A function 调用 B function?
线程进程区别,通信
- 首先是自我介绍,有提到以后往云原生方向发展,差点打算问我了,但是话锋一转问项目了。
- 介绍项目,说到了调度器,问用到了什么调度,提到后面想用消息队列进行解耦,又问打算用什么消息队列,还有消息队列中,执行失败,如何回传消息。总之项目介绍的不好。
- 用go实现消息队列,用什么实现比较合适。说到channel,又问channel的底层实现是什么样的。
- golang的垃圾回收机制,三色回收的过程。
- go语言里的堆是怎么实现的。
- 介绍下GMP并发机制。
- 手撕代码,合并k个有序链表。(自己手写测试用例好麻烦)
- tcp怎么实现流量控制与拥塞控制
- 问redis了解吗,我说知道一些,但是对方可能以为我不会,没接着问。
- 场景题,怎么解决用户刷单的问题,风控措施怎么做,给出解决方案。
- 最后反问环节,我说感觉自己表现不好,问对自己的建议,对方说还行(可能因为代码写出来了),然后项目介绍和场景题说的不好,之后问了具体的部门,对方确认了下实习时间。
总得来说语言针对性比较强,问的几乎都是golang相关的,其他方面的不多,还要再好好准备下项目,许愿一切顺利
作者:二点三横
链接:https://www.nowcoder.com/discuss/705864?type=2&channel=-1&source_id=discuss_terminal_discuss_hot_nctrack
来源:牛客网
- 面试官介绍部门
- 自我介绍
- 聊项目
- 场景:两个并发操作一起扣减库存,如何保证库存的数据一致性
- 串行扣减库存效率不高,并发操作有没有什么好的解决方案
- MySQL事务隔离级别
- 在已提交读的隔离级别下,事务A、B同时读取数据,事务A修改数据提交后事务B再次读取,那么事务B两次读取的数据有变化吗
- 在可重复读的隔离级别下是什么样的情况
- MMVC实现的原理
- 什么时候使用快照读,什么时候使用当前读(这里回答错了,把当前读搞成快照读了回顾的时候简直流汗)
- RabbitMQ如何保证消息被消费
- 当消费者消费了消息,数据库已提交,消费发送的ACK还没到就挂了,如何解决
- 缓存一致性如何解决
- 当某一时刻有大量并发请求,如何避免系统的核心功能挂掉(复盘之后我猜是想问容灾方案?)
- 应用写日志到磁盘,从调用write到写入到磁盘上的过程中发生了什么
- java的io模型有哪些
- linux的IO多路复用有哪些技术手段
- URL输入到浏览器到获取页面的过程中发生了什么
- 访问一个网站首页,是如何把所有数据都请求过来的(比如说首页还有其他的图片等对其他URL的请求)
- DNS查询的过程
- 网站IP变更了,用户访问该网站会发生什么
- 电脑如何判断本机缓存的IP地址的错误的
- Java垃圾回收算法
- GC过程中对应用有什么影响
- Java的内存泄漏遇到过吗(ThreadLocal)
- 如何规避ThreadLocal的内存泄漏
- 进程间通信的方式
- 反问环节
总结:在项目上问了很多问题,层层深入。面试的时候还是比较紧张,有些知道的问题答错了(比如把当前读当成快照读了,面试官当场就愣了,然后引导我,结果我还是没反应过来)。然后IO方面的知识比较欠缺答得不好。
作者:我在认真听
链接:https://www.nowcoder.com/discuss/160232
来源:牛客网
作者:宾克斯的美酒_
链接:https://www.nowcoder.com/discuss/705128?channel=-1&source_id=discuss_terminal_discuss_sim_nctrack&ncTraceId=3d6d3f1262b44647beed70b73d6ae137.148.16288438807690332
来源:牛客网
算法就写了个反转链表;
其他都是最简单的八股,我回答完都是直接下一问,20分钟完事。
都没记录的价值。 🙄
随便写一下吧。
讲一下实习项目
java内存模型
如何保证线程安全
B+树索引说说
MySQL半同步复制过程(这是集群备份么,没复习过)
HTTPS握手过程(不会,是SSL的握手)
设计模式说说
大致就这些,一脸迷惑 😧
- kafka的应用场景?(项目中用到了kafka)
- 访问消峰?
- 异步的场景?
- 平时怎么调试代码?如果代码多了呢?
- tcp为什么是可靠的?
- 为什么需要time wait?
- 快重传?
- linux查看内存,cpu占用命令?
- 端口占用命令?
- java hashmap,红黑树的平均查找复杂度?
- 多线程交互方式?
- 线程池的核心数?
- mysql的引擎?
- redis的使用?
腾讯看来的确全部是 c++,面试官也是说基本上都是 c++,没有专门搞 java 的组,所以大家 java 投腾讯还是务必慎重,最开始问我的技术栈是什么,c++是否了解,用的比较多?得知我说基本没咋用过之后,就开始尝试问计算机网络方面的问题。
问的很深入,比如说三次握手四次挥手,客户端服务器端各自的状态是什么,对整个建立连接和关闭连接的具体流程是什么,深入到 OSI 模型去讲;
这个我在上面已经详细说过了…
然后主要问的是 Socket 编程,讲套接字编程的具体实现流程,代码如何写,如何实现类似于 Nginx 的多服务器的 Socket 编程;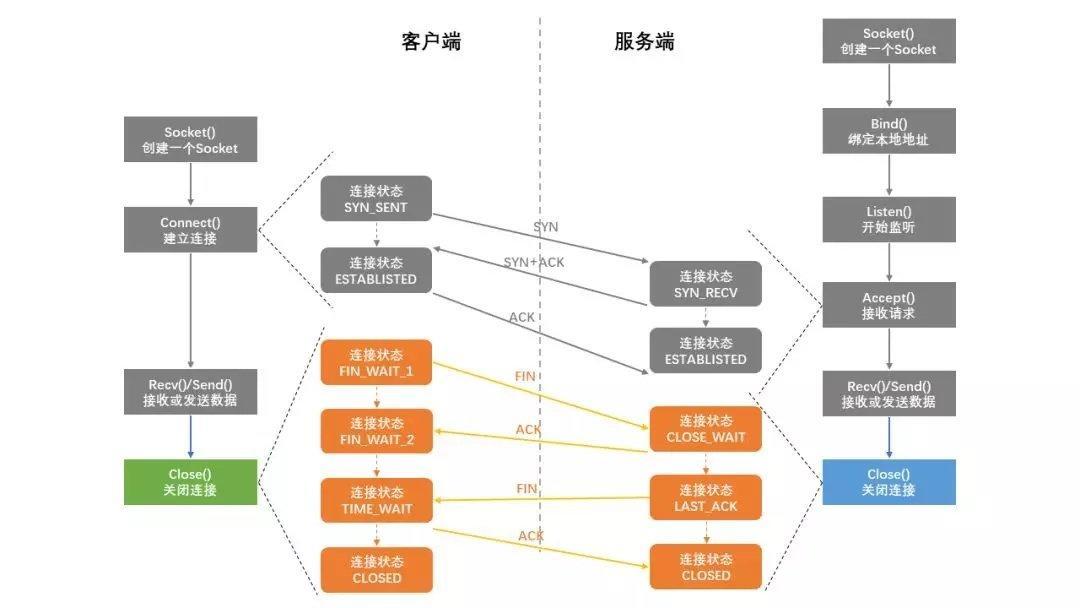 [1]
[1]
preview[2]
然后谈到 select、epoll等相关 c++ 的知识,我是在 java 层面去讲的如何实现的 「NIO」;
嘿嘿嘿,这个没问题了,可以看我的最新的文章 —《零拷贝及其周边》
再者就是聊到数据库,这个是必问的,问我索引如何建立、如何优化索引,然后是一些具体问题对索引的分析;
用 key or index 建立索引,优化索引的方法:尽量复用索引,利用好最左前缀和索引下推原则,尽量减少回表次数,利用覆盖索引。
然后谈到事务的四个特性,如何实现原子性、隔离性、一致性、持久性的,内部机制具体如何实现;
原子性:利用 undolog,回滚机制,完成要么全部成功,要么全部失败;
隔离性:主要是靠一致性视图+当前行的 row_id_transaction,来完成的。
一致性:主要靠加锁防止事务冲突,一致性是另外三个的顶层,只要他们三完成了他才有可能完成,还有mvcc的加持,以及 undolog、redolog。
持久性:redolog保证crash-safe,bin-log保证归档。
借此谈到 undolog、redolog、binlog,以及 mvcc 的实现;
略
Redolog 到底是保存在磁盘中的还是在内存中?
redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。
详细分析 Mysql 中的三个日志:redolog、undolog、binloghttps://juejin.im/entry/5ba0a254e51d450e735e4a1f
谈一谈 mysql 的运行机制,整个运行过程是怎样的,如何处理的;
这个简单,略
mysql的索引实现,B+的优点等等;
简单,略
全程谈 一致性问题 谈的很多,包括了 mysql 主从复制的一致性如何保证,我说不太清楚,但是借此讲了 kafka 中的高可用机制「ISR」,以及 kafka中的 ack 机制和 kafka 中的消息语义「如何保证数据的一致性」;
Mysql 保证主从一致性:
主库接收到客户端的更新请求后,执行内部事务的更新逻辑,同时写binlog。
备库B跟主库A之间维持了一个长连接。主库A内部有一个线程,专门用于服务备库B的这个长连接。一个事务日志同步的完整过程是这样的:
在备库B上通过change master命令,设置主库A的IP、端口、用户名、密码,以及要从哪个位置开始请求binlog,这个位置包含文件名和日志偏移量。
在备库B上执行start slave命令,这时候备库会启动两个线程,就是图中的io_thread和sql_thread。其中io_thread负责与主库建立连接。
主库A校验完用户名、密码后,开始按照备库B传过来的位置,从本地读取binlog,发给B。
备库B拿到binlog后,写到本地文件,称为中转日志(relay log)。
sql_thread读取中转日志,解析出日志里的命令,并执行。
这里需要说明,后来由于多线程复制方案的引入,sql_thread演化成为了多个线程。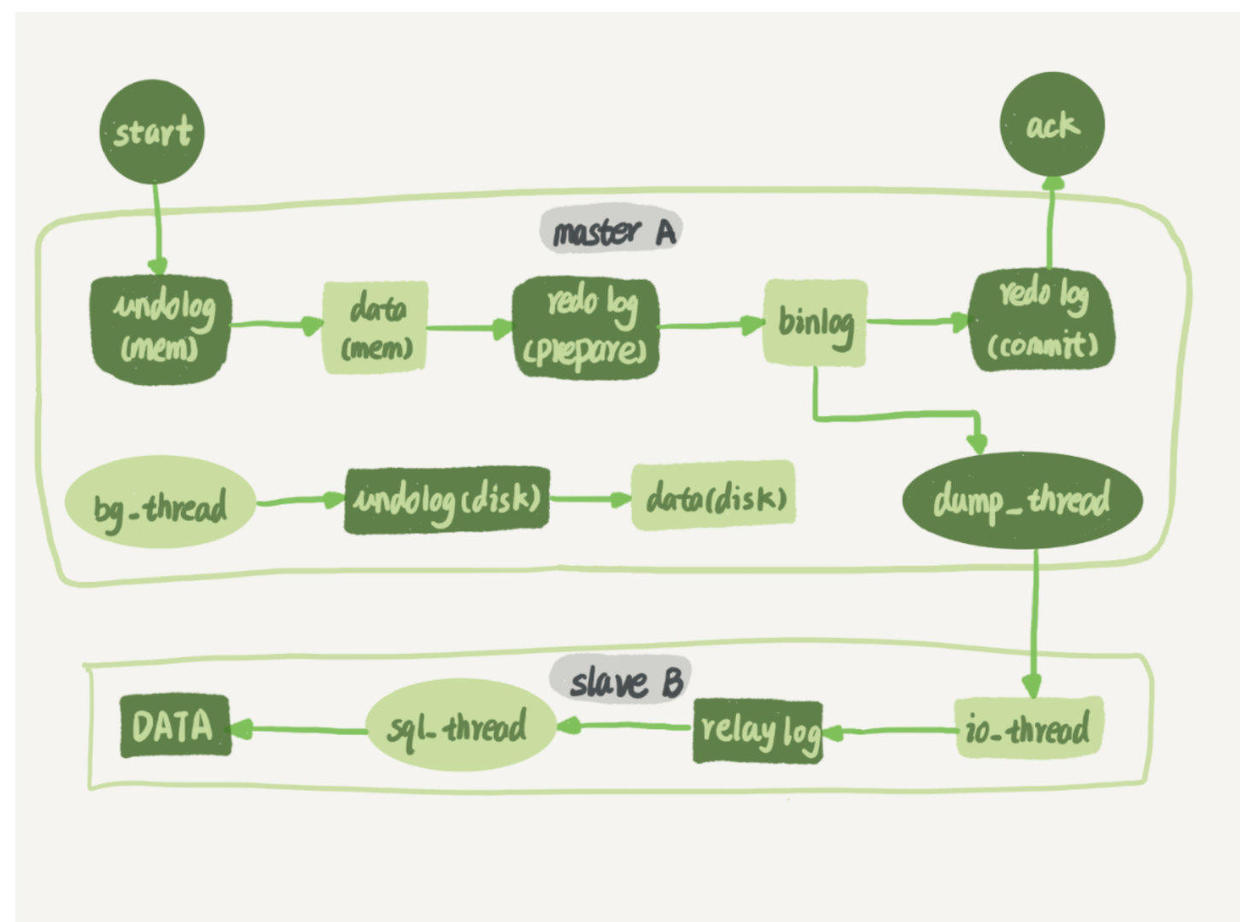 [3]
[3]
image-20200325005851525[4]
因为语言上还是有很多区别的,在后面又问了几个有关于 c++ 的问题,答得不是很好
虚函数是什么 「没答上来」;
略。
因为看到我博客有些滑动窗口算法,就问了 tcp 滑动窗口底层的代码实现;
进程、线程、协程的区别,我说完之后,又延伸到线程是如何保证同步的,借此谈到了线程安全,然后我自己拓展了 synchronized「详细介绍了锁升级过程」、lock体系、CAS 的实现以及 final 关键字和 ThreadLocal;
协程的应用场景主要在于 :I/O 密集型任务。
这一点与多线程有些类似,但协程调用是在一个线程内进行的,是单线程,切换的开销小,因此效率上略高于多线程。当程序在执行 I/O 时操作时,CPU 是空闲的,此时可以充分利用 CPU 的时间片来处理其他任务。在单线程中,一个函数调用,一般是从函数的第一行代码开始执行,结束于 return 语句、异常或者函数执行(也可以认为是隐式地返回了 None )。有了协程,我们在函数的执行过程中,如果遇到了耗时的 I/O 操作,函数可以临时让出控制权,让 CPU 执行其他函数,等 I/O 操作执行完毕以后再收回控制权。
简单来讲协程的好处:
跨平台
跨体系架构
无需线程上下文切换的开销
无需原子操作锁定及同步的开销
方便切换控制流,简化编程模型
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序:这一点和事件驱动一样,可以使用异步IO操作来解决
最后再贴个图来总结一下,更清楚: [5]
[5]
img[6]
作者:程序猿杂货铺 链接:https://juejin.im/post/5d5df6b35188252ae10bdf42来源:掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
进行间通信 IPC 有哪些方式「我只说了信号量、共享区域、管道这几个,面试官也没追问」
管道。管道的实质是一个内核缓冲区,进程以先进先出的方式从缓冲区存取数据,管道一端的进行顺序的将进程数据写入缓冲区,另一端的进则顺序地读取数据,该缓冲区可以看做一个循环队列,读和写的位置都是自动增加的,一个数据只能被读一次,读出以后在缓冲区就不复存在了。当缓冲区读空或者写满时,有一定的规则控制相应的读进程或写进程是否进入等待队列,当空的缓冲区有新数据写入或满的缓冲区有数据读出时,就唤醒等待队列中的进程继续读写。管道是一种半双工通信方式,数据只能单向流动。需要进行通信时,需要建立2个管道。
信号量。进程之间通信的机制,例如 Semphore ?
共享内存。进程的不同虚拟内存映射到用一个物理内存上,实现共享。
内存泄露问题如何排查,主要问linux如何进行排查「没答上来,就说可以用可视化界面」
内存泄露会发生什么情况,系统会假死吗?
最后谈了谈一些数据结构和算法:
两个堆如何实现队列「貌似堆不就是优先级队列嘛…」,两个队列如何实现堆;「面试官表述不清楚,可能就是想指堆栈???」
两个栈如何实现队列,两个队列如何实现栈;
链表如何查找是否有环;
链表如何确定环的起点;
两条链表找公共处的起点。
还有一些细枝末节的问题,印象已经不深了,大概就是这些吧。
总结一下:面试官非常擅长挖掘面试者的优势,对面试者不太懂的全部不问,基本上我会什么就问什么,所以大概面试了半小时后,就开始对着我的博客问,所以整体上给人的感觉是很好的。大家如果要面腾讯的话建议多看看c++,并且对常见的 计网 和 os 的问题尽量往深处走,面试官只看中你对问题的深度,不会的问题他不会追问。
最大的收获:
面试官对自己方方面面的建议。并且给自己推荐了三本书《unix网络编程卷一》《unix网络编程卷二》《linux内核》

若有收获,就点个赞吧
0 人点赞
