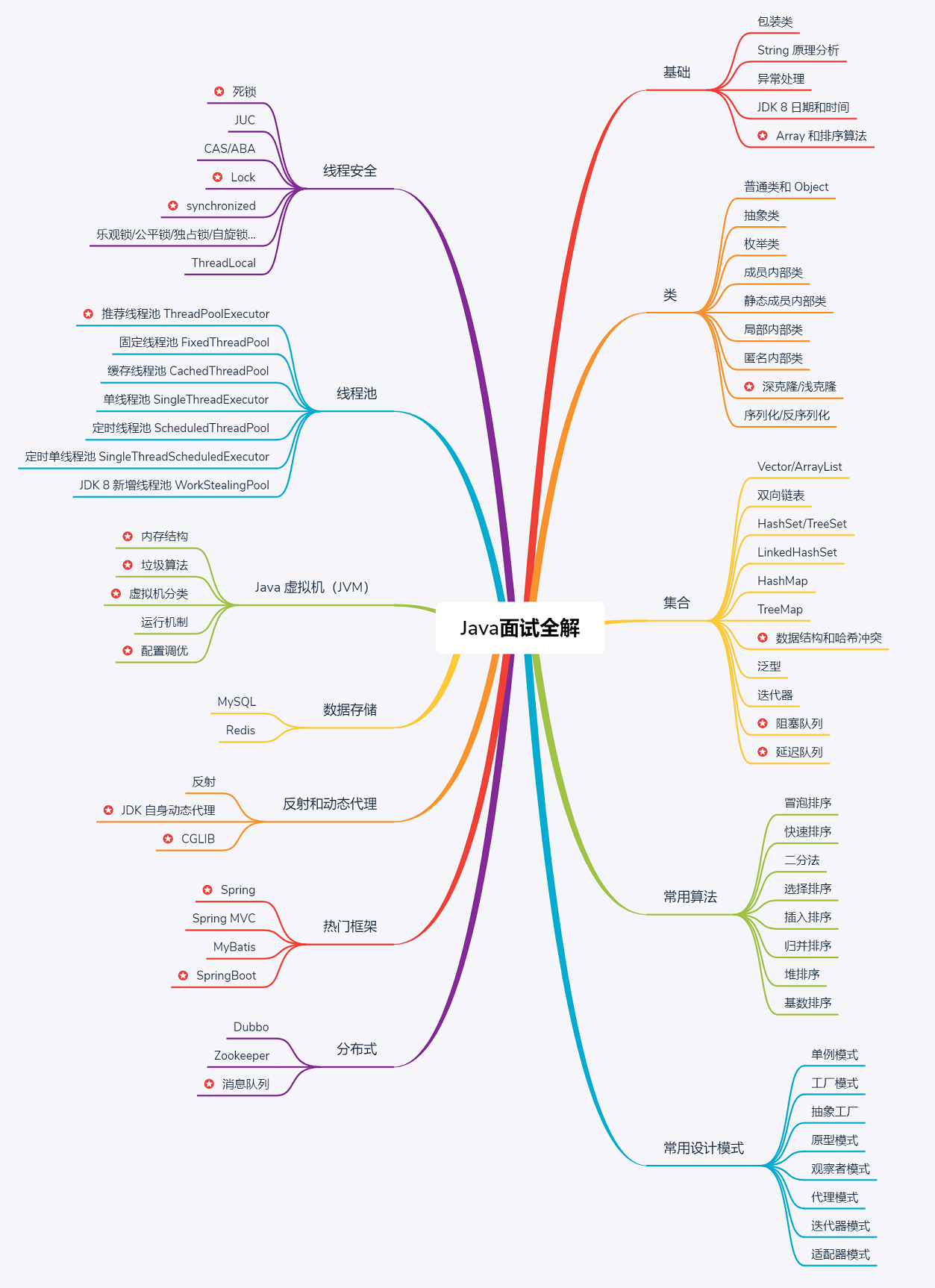
基础
String原理解析
java 底层实际上是一个字符数组: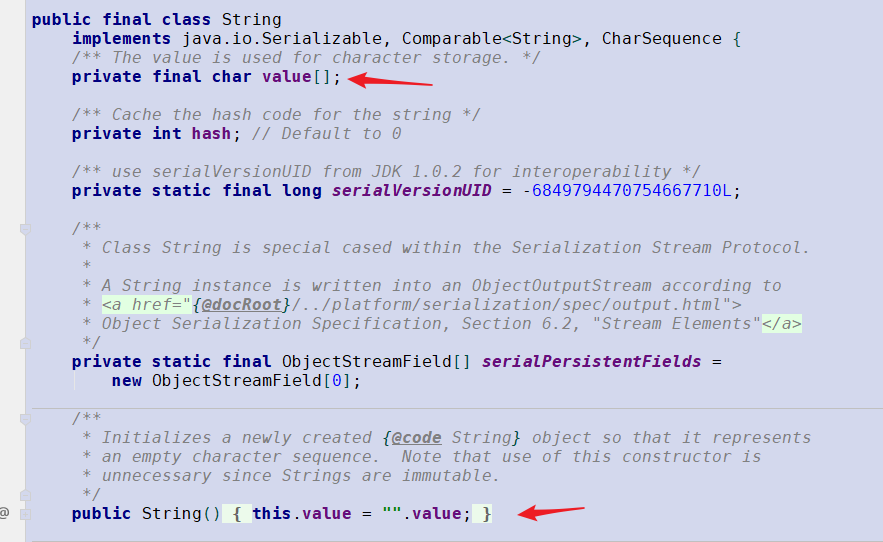
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
答案
class Solution {public int[] intersection(int[] nums1, int[] nums2) {Set<Integer> set = Arrays.stream(nums1).distinct().boxed().collect(Collectors.toSet());return Arrays.stream(nums2).distinct().filter(set::contains).toArray();}}
异常处理
java8日期
面试官:String,StringBuffer,StringBuilder的区别
- 线程安全:String、 StringBuffer
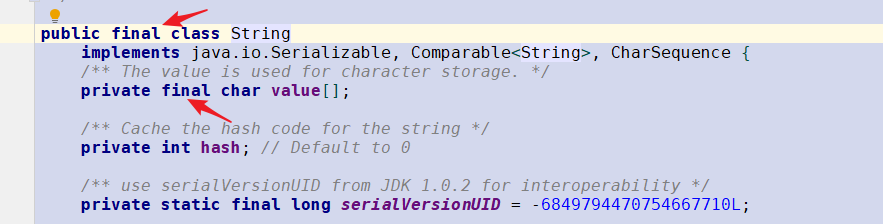
因为String字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享
- 线程不安全: StringBuilder
因为StringBuilder的方法都是没有加Synchronized同步锁的,所以线程不安全
- 执行效率**: StringBuilder > StringBuffer > String**
- 存储空间:
- String的值是不可变的,每次对String的操作都会生成新的String对象,效率低,耗费大量内存空间,从而会引起GC。
- StringBuilder、StringBuffer 都是可变的。
- 使用场景:
- 操作少量的数据使用String;
- 单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
- 多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
HashMap
思考角度:
存储结构
默认容量
装载因子
hashcode/equals
1.7和1.8版本变化
- 存储结构:
- 数组+链表+红黑树(JDK8)
- 默认容量: 16
- 装载因子: 0.75
- key可以为null;
- HashCode : 计算键的hashcode作为存储键信息的数组下标用于查找键对象的存储位置。
- equse: HashMap使用equse()判断当前的键是否与表中存在的键相同(hashCode相同equse不一定相同,equse相同hashcode一定相同)。补充说一句:“两个不同的键值对,哈希值相等”,这就是哈希冲突。(若要判断两个对象是否相等,除了要覆盖equals()之外,也要覆盖hashCode()函数。否则,equals()无效。 )
为何要设计出迭代器
迭代器本质是一种设计模式,为了解决 为不同的集合类提供 **统一的遍历操作接口**。
java单击并发控制
- 基础:
- 同步方法: synchronized
- 同步块: synchronized
- 进阶:
- 重入锁 ReentrantLock
多线程创建的方式
Thread 、 Runnable 、 Callable
- 继承Thread类创建线程,重写run()方法
- 只能单继承,。多次调用start()会抛异常IllegalThreadStateException
- 实现Runnable接口创建线程
- 多实现
- 实现Callable接口通过FutureTask包装器来创建Thread线程
使用ExecutorService、Callable、Future实现有返回结果的线程
Thread 、 Runnable 、 Callable 实现的区别
第一种实现方式:继承Thread
特点: 只能实现单继承、 启动调用start()方法。
public class ThreadTest {public static void main(String[] args) {System.out.println("主线程开始");ExtendThread t = new ExtendThread();//调用start()方法 结果是两个线程同时运行:// 当前线程(从调用返回到<code> start </ code>方法)// 和另一个线程(执行其* <code> run </ code>方法)t.start();//重复调用会抛异常:IllegalThreadStateException// t.start();System.out.println("主线程结束");}}//继承Thread,重新run()方法class ExtendThread extends Thread {@Overridepublic void run() {for (int i = 0; i < 10; i++) {System.out.println(i);}}}
正常运行结果:
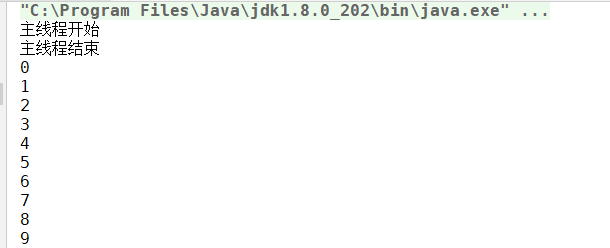
连续两次调用start()方法: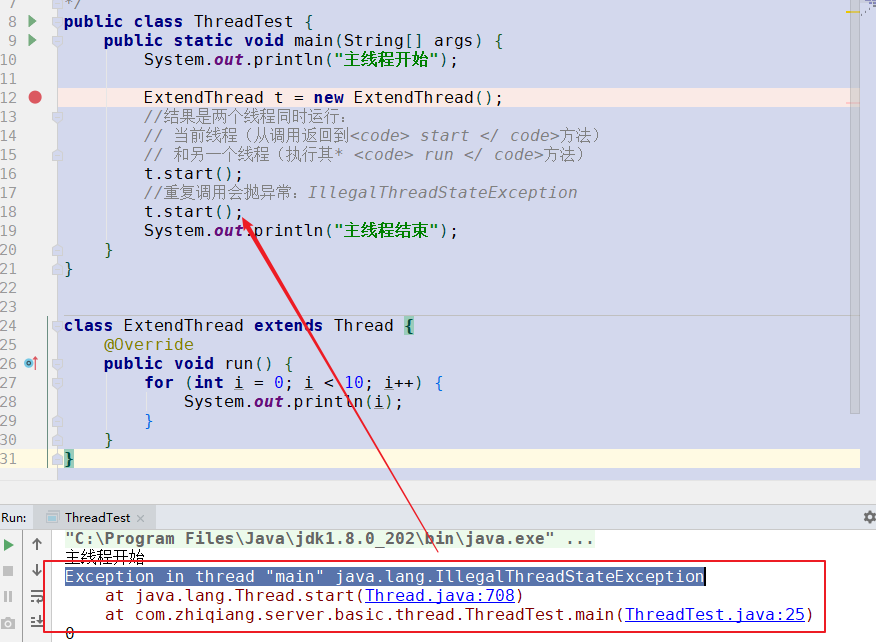
休眠 Thread.sleep(1) ;
- Thread类— 常用API方法:



第二种实现方法:实现Runnbale接口 (内部只有一个run()方法)
- 优点:
- 除非程序员打算修改或增强类的基本行为,否则不应将类归为子类 ,即采用继承Thread类的方式。
- java类单继承多实现。 如果一个子类以及继承了另外的一个父类, 就不能在继承Thread类了。
- Runnable接口只有一个run()方法。
- Thread类实现了Runnable接口。
- 便于多个线程共享资源;
使用Runnbale实现代码: ```java public class RunnableTest{
public static void main(String[] args){
System.out.println("主线程开始");ThreadTestA test = new ThreadTestA();//创建线程Thread t = new Thread(test);//启动线程t.start();System.out.println("主线程结束");
} }
/**
继承Runnable 重写run方法 */ class ThreadTestA implements Runnable {
@Override public void run() {
for (int i = 0; i < 10; i++) {System.out.println(i);}
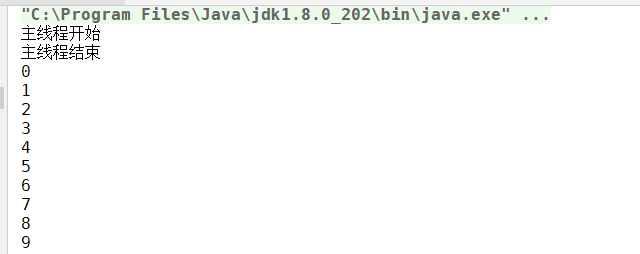
} } ``` 运行结果:
怎么防止前端重复提交
- 前端生成唯一ID,后端通过唯一索引(这个用的比较多)
- 前端控制:
- 提交按钮后屏蔽提交按钮(js控制)
- 后端控制:
- 利用Session防止表单重复提交
SpringAOP的原理 **
spring实现AOP的思路很简单:
- 通过预编译方式和运行期动态代理方式实现程序功能的统一维护的一种技术
- 主要功能:日志记录、性能统计、安全控制、事务处理、异常处理等等
- AOP实现方式
- 预编译:AspectJ
- 运行期动态代理(JDK动态代理、CGLib动态代理):SpringAOP、JbossAOP
- 预编译:AspectJ
- AOP几个相关概念
面向切面的核心思想就是,让核心的业务逻辑代码,不需要去管理一些通用的逻辑,比如说事务,安全等这方面的共同逻辑,解耦业务逻辑和通用逻辑
批量往mysql导入1000万数据有什么方法 ?
show global variables like 'max_allowed_packet' ;
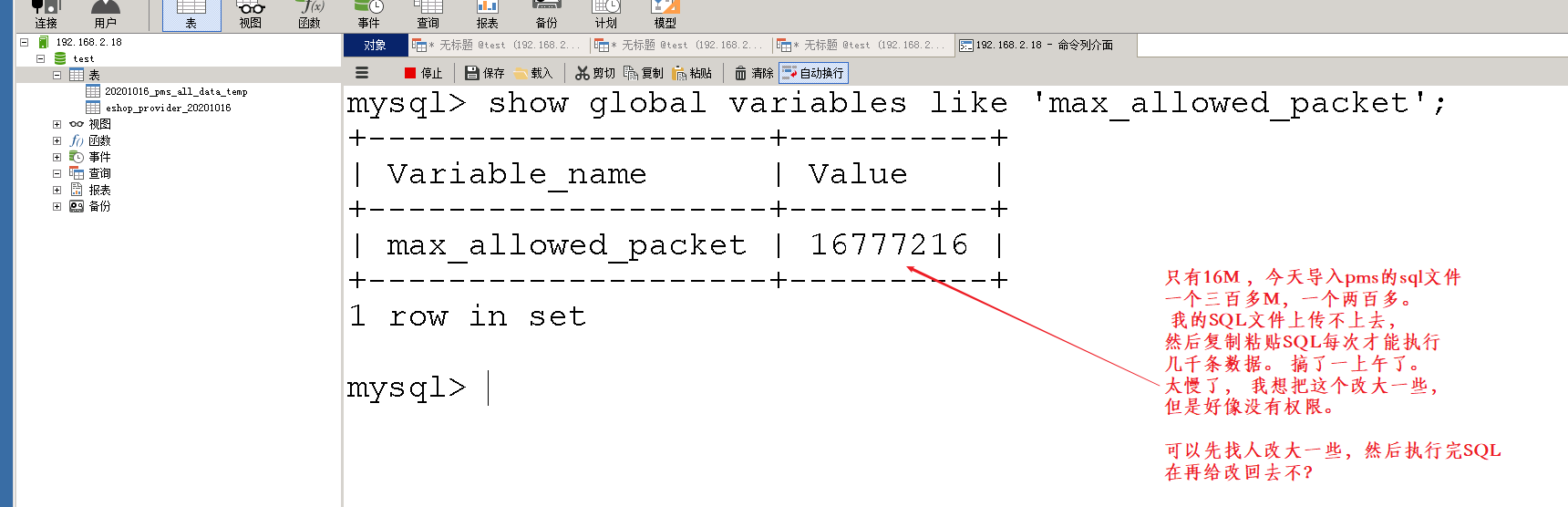
减少IO次数 —> SQL写法优化 —> 合理设置批量大小 —> 尽量顺序插入
- 一条SQL语句插入多条数据;
- 在事物中进行插入处理,切记不要一条数据提交一下,要分批处理;
- 数据有序插入,是为了减少索引的维护压力;
例如:
批量插入:
<insert id="insertPrBulkDetails"><if test="@org.apache.commons.collections.CollectionUtils@isNotEmpty(details)">INSERT INTO `t_eshop_pr_bulk_detail`(`id`,`fk_pr_id`,`pms_material_code`,`pms_material_name`,`type_code`,`type_name`,`sub_type_code`,`sub_type_name`,`min_type_code`)VALUES<foreach collection="details" item="item" separator="," >(#{item.id},#{item.fkPrId},#{item.pmsMaterialCode},#{item.pmsMaterialName},#{item.typeCode},#{item.typeName},#{item.subTypeCode},#{item.subTypeName},#{item.minTypeCode})</foreach></if></insert>
事物插入: ```sql
START TRANSACTION;
INSERT INTO
XXX表(gmt_create,gmt_modified,字段A,字段B,字段C)
VALUES
(NOW(),NOW(),#vals[].字段A#,#字段B[].字段C#),
(NOW(),NOW(),#vals[].字段A#,#字段B[].字段C#),
(NOW(),NOW(),#vals[].字段A#,#字段B[].字段C#);
INSERT INTO
XXX表(gmt_create,gmt_modified,字段A,字段B,字段C)
VALUES
(NOW(),NOW(),#vals[].字段A#,#字段B[].字段C#),
(NOW(),NOW(),#vals[].字段A#,#字段B[].字段C#),
(NOW(),NOW(),#vals[].字段A#,#字段B[].字段C#);
COMMIT;
---<a name="6HjK7"></a>## Array和排序算法<a name="ZFhlO"></a># 类<a name="m3CvV"></a>## 深克隆/浅克隆<a name="2UJaH"></a>## 序列化/反序列化<a name="mEuB5"></a>## 枚举类<a name="VnhpO"></a>## 抽象类<a name="7yTe6"></a># 集合<a name="LSOTJ"></a>## Vector/ArrayList<a name="ZCRSV"></a>## 双向链表<a name="PszO4"></a>## HashMap<a name="ioCzj"></a>## 数据结构<a name="k8qFJ"></a>### 常见的数据结构:- 数组(查询效率高)- 栈(last in first out): 典型的撤回操作,括号匹配- 队列(first in first out):- 链表(插入快)- 单向链表:- 双向链表:- 图(graph)- 遍历图的两种算法:- 广度优先搜索- 深度优先搜索- 树(Tree):被广泛应用在人工智能和一些复杂的算法当中,用来提供搞笑的存储结构;- N 叉树- 平衡树- 二叉树- 二叉查找树- 平衡二叉树- 红黑树- 前缀树:与树类似,用于处理字符串相关的问题是非常高效。他可以实现快速检索,常用语字段中的单词查找,搜索引擎的自动补全等。- 哈希表:将某个对象变换成唯一标识符,改标识符通常用一个短的随机字母和数字组成的字符串来代表。hash哈希可以用来实现各种数据结构,其中最常用的就是哈希表(hash table)- hash table通常由数组实现。- 指标: 哈希函数、 哈希表的大小、 哈希冲突的处理方式<a name="x1Kl3"></a>### 常见的相关面试题:1. 数组:1. 查找数组中第二小的元素:```javapublic class SecondSmallest {static Integer get2Smallest(int[] arr){//int[] arr = {5,6,41,5,3,1}//定义最小跟第二小变量int first, second, arr_size= arr.length;if (arr_size < 2){System.out.println(" Invalid Input ");return null;}//定义第一跟第二是最大的数first = second = Integer.MAX_VALUE;for (int i = 0; i < arr.length; i++) {if(arr[i] < first){second = first;first = arr[i];}else if(arr[i] > first && arr[i] < second) {second = arr[i];}}//如果第二小等于 int 的最大值,报错if(second == Integer.MAX_VALUE){System.out.println("There is no second");return null;}return second;}public static void main(String[] args) {int[] arr = {5,6,41,5,3,1};Integer secondSmallest = get2Smallest(arr);System.out.println("The SecondSmallest is :"+ secondSmallest);}}
泛型
迭代器
阻塞队列
延迟队列
常用算法
冒泡排序法
快速排序
二分法
选择排序
插入排序
归并排序
堆排序
基数排序
常用设计模式
单例模式
工厂模式
抽象模式
原型模式
观察者模式
代理模式
迭代器模式
适配器模式
线程安全
死锁*
JUC
CAS/ ABA
Lock*
synchronized *
乐观锁、公平锁、独占锁、自旋锁
ThreadLocal
线程池
推荐线程池 ThreadPoolExecutor
固定线程池 FixedThreadPool
缓存线程池 CachedThreadPool
单线程池 SingleThreadExecutor
定时线程池 ScheduledThreadPool
JDK8 新增线程池 WorkStealingPool
JVM *
内存结构
垃圾算法
虚拟机分类
运行机制
配置调优
反射跟动态代理
反射
JDK动态代理
CGLIB 代理
热门框架
Spring
SpringMVC
MyBatis
SpringBoot
数据库
MySQL
Redis

若有收获,就点个赞吧
0 人点赞
