1.前缀索引
长度设计,通过计算选择性来确定前缀索引的选择性:SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;结果越接近1时,索引效果越好。定好长度可以节省空间,也可以加快查询时间。
例子: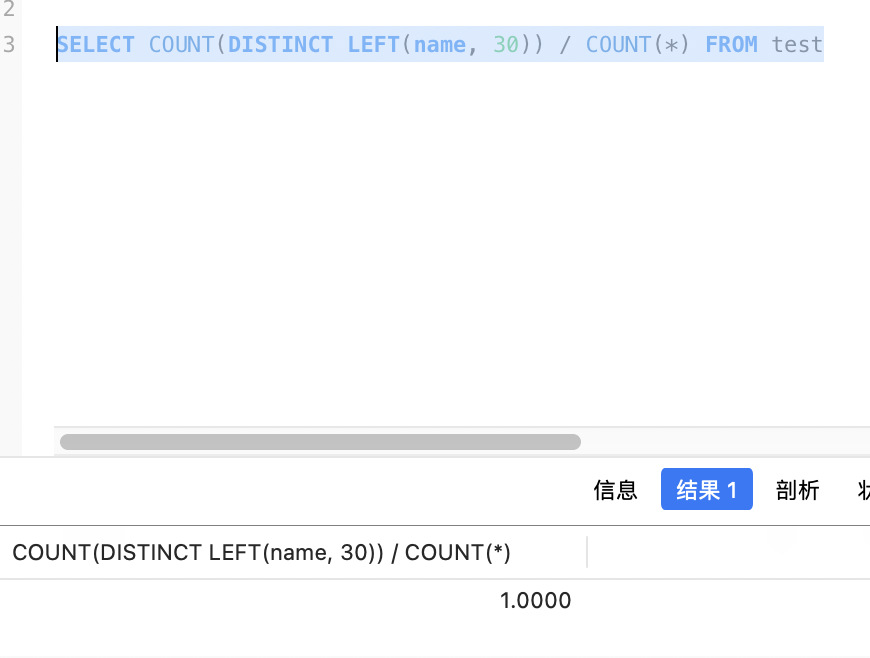
2.建立索引的列,不允许为 null
单列索引不存 null 值,复合索引不存全为 null 的值,如果列允许为 null,可能会得到“不符合预期”的结果集,所以,请使用 not null 约束以及默认值。
3.业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引
不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的。另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
4.创建索引时避免以下错误观念
- 索引越多越好,认为一个查询就需要建一个索引。
- 宁缺勿滥,认为索引会消耗空间、严重拖慢更新和新增速度。
- 抵制唯一索引,认为业务的唯一性,一律需要在应用层通过“先查后插”方式解决。
- 过早优化,在不了解系统的情况下就开始优化。
5.mysql Hash索引和BTree索引的区别
Hash仅支持=、>、>=、<、<=、between。BTree可以支持like模糊查询。
BTree索引:只要它的查询条件是一个不以通配符开头的常量
如果以通配符开头,或者没有使用常量,则不会使用索引。select * from user where name like ‘jack%’;select * from user where name like ‘jac%k%’;
Hash索引:select * from user where name like ‘%jack’;select * from user where name like simply_name;
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到分支节点,最后才能访问到叶子结点这样多次IO访问,所以检索效率远高于BTree索引。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
- Hash索引仅仅能满足“=”,“IN”,“<=>”查询,不能使用范围查询。
- 联合索引中,Hash索引不能利用部分索引键查询。
对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。 - Hash索引无法避免数据的排序操作
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。 - Hash索引任何时候都不能避免表扫描
Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。 - Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能低下。6.Mysql中key 、primary key 、unique key 与index区别
最后一句的KEYCREATE TABLE `phpcolor_ad` (`id` mediumint(8) NOT NULL AUTO_INCREMENT,`name` varchar(30) NOT NULL,`type` mediumint(1) NOT NULL,`code` text,PRIMARY KEY (`id`),KEY `type` (`type`));
type(type)是什么意思?如果只是key的话,就是普通索引。
1.key 是数据库的物理结构,它包含两层意义和作用:
一是约束(偏重于约束和规范数据库的结构完整性),
二是索引(辅助查询用的)
2.primary key 有两个作用
一是约束作用(constraint),用来规范一个存储主键和唯一性,
二是在此key上建立了一个主键索引;PRIMARY KEY 约束:唯一标识数据库表中的每条记录;
1)主键必须包含唯一的值;
2)主键列不能包含 NULL 值;
3)每个表都应该有一个主键,并且每个表只能有一个主键。(PRIMARY KEY 拥有自动定义的 UNIQUE 约束)
3.unique key 也有两个作用
一是约束作用(constraint),规范数据的唯一性
二是在这个key上建立了一个唯一索引
UNIQUE 约束:唯一标识数据库表中的每条记录。
UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。(每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束)。
4.index是数据库的物理结构,它只是辅助查询的,它创建时会在另外的表空间(mysql中的innodb表空间)以一个类似目录的结构存储。索引要分类的话,分为前缀索引、全文本索引等;索引只是索引,它不会去约束索引的字段的行为(那是key要做的事情)。

若有收获,就点个赞吧
0 人点赞
