1. 项目需求分析
- 采集埋点的日志数据(文件形式
- 采集业务数据库中数据(结构化数据
- 数据仓库的搭建(用户行为数仓、业务数仓
- 分析统计业务指标
- 对结果进行可视化展示
2. 项目框架
2.1 阿里云技术框架
| 阿里云产品 | 简介 | 类比 | | —- | —- | —- | | DataHub | 数据总线 | Kafka + 各种服务接口 | | MaxCompute | 大数据计算框架 | Hadoop + Hive + 调度器 | | DataWorks | 可视化MaxCompute的开发管理平台 | | | RDS | 关系型数据库 | MySql | | QuickBI | 可视化数据展示工具 | Tableau、Echarts、Kibana | | ECS | 弹性服务器 | Linux服务器 |
2.2 技术选型
| 需求 | 阿里云框架 | 开源框架 |
|---|---|---|
| 数据采集传输 | 采集文件日志: Flume、DataHub 业务数据(mysql):RDS |
采集文件日志:Flume、Kafka 业务数据(mysql):Sqoop、DataX 定时导离线数据 |
| 数据存储 | MaxCompute、DataWorks | MySQL、Hadoop、HBase |
| 数据计算 | MaxCompute、DataWorks | Hive(MapReduce引擎)、Spark、Flink |
| 数据可视化 | QuickBI | Tableau、Echarts、Kibana |
2.3 系统数据流程设计
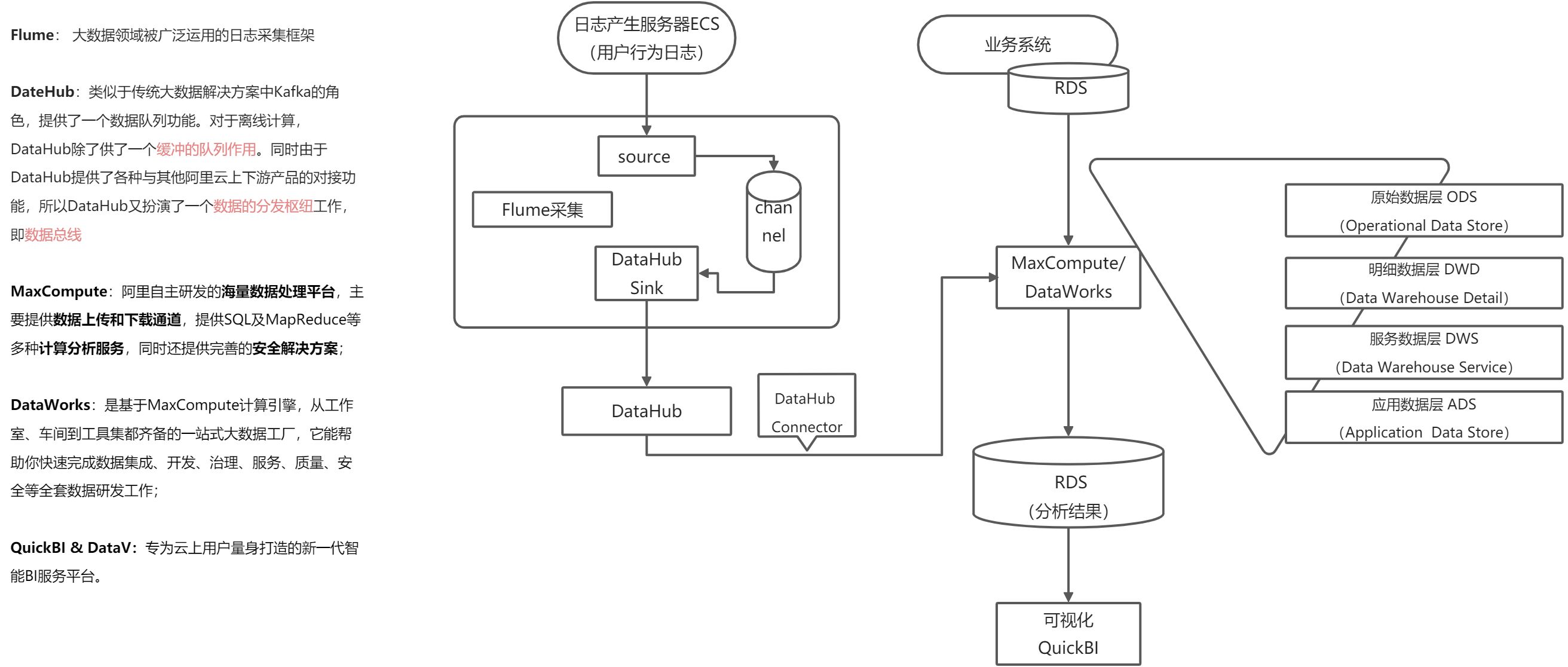
2.4 服务器购买
物理机 or 云主机
- 机器成本
- 物理机:主流:128G内存, 20核物理CPU, 40线程,8THDD(机械硬盘)和2TSSD(固态硬盘),价格4W+。服务器托管费用,寿命5年
- 云主机:相同配置,每年5W
- 运维成本
- 物理机:专业运维人员,每月15000;电费
- 云主机:很多运维工作由阿里云完成,运维相对较轻松
主流:中小型公司一般都采用云主机
集群规模计算
- 用户行为数据
- 日活用户100万,每人一天平均100条: 100万 * 100条 = 1亿条
- 每条日志1K左右,1亿 * 1K / 1024 / 1024 = 100G
- 数仓ODS层采用LZO压缩 + parque链式存储: 100G压缩为10G左右
- 数仓DWD层采用LZO压缩 + parque链式存储: 10G左右
- 数仓DWS层轻度聚合存储(为了快速计算,不压缩):50G左右
- 数仓ADS层:结果数据,数据量忽略不计
- 保存3副本: 70G * 3 = 210G
- 半年内不扩容服务器:210G * 180天 = 37T
- 预留20%~30%Buf: 37T / 0.7 = 53T
- DataHub中数据
- 每天100G * 副本(2) = 200G
- 保存3天:200G * 3天 = 600G
- 预留30%Buf = 600G / 0.7 =1T
- Flume中的缓存数据:忽略不计
- 业务数据
- 日活100万、下单用户10万,每人每天产生的业务数据10条,每条日志1K左右: 10万 10条 1K = 1G左右
- 数仓四层存储: 1G * 3 = 3G
- 保存3副本: 3G * 3 = 9G
- 半年内不扩容服务器:9G * 180天 = 1.6T
- 预留20%~30%Buf: 1.6T / 0.7 = 2T
集群总规模: 53T + 1T + 2T = 56T
约 8T * 7 台服务器
购买建议
| 购买服务 | 建议配置 | 年成本 | 备注 |
|---|---|---|---|
| DataHub | medium | 免费 | |
| MaxCompute | 32CU * 7 | 35w | 1CU = 1cpu + 4G内存 |
| RDS | 4核8G | 1w | 存放离线统计结果 |
| QuickBI | 高级版 | 4w+ | |
| 年总成本 | 40w |

若有收获,就点个赞吧
0 人点赞
