SQL执行原理
语法顺序: select—from—where—group by—having—order by
执行顺序: from—where—group by—having—select—order by
第一步 准备表格
复制源数据进行连接、筛选,分组,分组后过滤等操作
- from
- 执行顺序为从后往前、从右到左
- 从后往前意味着,最后面的那个表名为驱动表,执行顺序为从后往前, 所以数据量较少的表尽量放后
- 指定从哪些数据表读取数据
- 从数据库中找到from后指定的表格,复制一张完全一样的表格用于查询处理
- 执行顺序为从后往前、从右到左
- join
- 将多个表格进行连接
- where
- 执行顺序为自下而上、从右到左
- 根据这个原理,表之间的连接必须写在其他Where 条件之前, 可以过滤掉最大数量记录的条件必须写在Where 子句的末尾
- 指定源数据的筛选条件
- 执行顺序为自下而上、从右到左
- group by
- 执行顺序从左往右分组
- 对数据进行分组
- sql进行分组的本质是去重合并
- group by指定了聚合函数的计算依据,具体的聚合运算还是要由聚合函数进行
- 因为group by先运行,并且运行后,表格中的非聚合字段已经形成了,所以select后的非聚合字段一定要与group by后指定的字段一致。也就是说:group by后没有的非聚合字段select无法显示,但group by后有的非聚合字段select可以选择不显示
having
order by
- 根据以下字段的升/降序进行排序
- 执行顺序为从左到右排序,很耗资源
- limit
- 基于排序好的表格,指定行数的数据
- select
- 在阅读SQL代码和书写时,可以先从FROM和JOIN语句看起,明确用了哪些表,然后看SELECT查询和创建了哪些字段,接下来细致研究代码细节,最后看WHERE的筛选逻辑
- SQL语句不区分大小写,因此SELECT与select甚至是SeLect的效果是相同的,但是要对命令和变量进行区分,所以默认命令需要大写,其他内容如变量等则需要小写;但是在高强度编程时,如果编程工具能够识别SQL语法自动对命令和变量进行区分(基本上都有这个功能),则也会使用小写命令
- 命令和变量名称冲突时需要在变量两侧加``(在左上角~那)做区分,’’(单引号在区分字符串时使用),””(已有单引号时用双引号包含单引号)
- 表和变量名中不要出现空格,可使用下划线_替代
- 为提高代码的可移植性,请在查询语句结尾添加一个分号;
- 对于定义模糊或关键变量和关键代码要加注释
- 命令和变量使用单一空格隔开
- 能用自链接则尽量不要使用子查询
- 在各个库中,表和字段别名尽量统一,方便代码移植,不要使用a,b来别名,别名要有含义
代码注释
```sql 单行注释 使用两个连字符-,添加注释
SELECT col_name — 这是一条注释 FROM table_name;
多行注释 多行注释以/起始,以/结尾 /SELECT col_name FROM table_name;/ SELECT col_2 FROM table_name;
<a name="M0Xdn"></a>## FROM- 表和字段一样尽量加上别名,并且同一个表用一个别名- sql server 把子查询作为数据源时,如果没有表别名,将会提示错误。所以一定要别名<a name="IzqQe"></a>## 查询SELECT- 检索某列中不同的值使用**DISTINCT**- 本质上是删除重复值- 可以使用**AS**给查询字段起别名- 在检索中支持进行数学计算- 适用于计算的操作符有+(加),-(减)和/(除)- 支持字符类型的拼接- `SELECT RTRIM(col_name) + '('+RTRIM(col_country)+')' AS col_title FROM table_name ORDER BY col_name;`- 输出:- - 这里实现的就是将col_name列与col_country列进行了拼接,新列的名字叫做col_title- RTRIM()函数是去掉右边的所有空格,LTRIM()是去掉左边的所有空格,TRIM()是去掉两边的所有空格<a name="m7xeh"></a>## 条件WHERE- WHERE子句应该写在表名(即FROM子句)之后,**在ORDER BY子句之前**- 可以使用的运算符- = 等于- <> 不等于- > 大于- < 小于- >= 大于等于- <= 小于等于- BETWEEN…AND… 在指定的两值之间,并且包括边界值- IS NULL 为NULL值- AND 逻辑运算符:与- OR 逻辑运算符:或- IN 条件范围筛选- NOT 逻辑运算符:非- SQL的版本不同,可能导致某些运算符不同(如不等于可以用!=表示),具体要查阅数据库文档。- 用**通配符LIKE**进行过滤- %- 表示任何字符出现任意次数- _- 表示任何字符出现一次- []- 指定一个字符集,它必须匹配该位置的一个字符- ^- 在[]中使用,表示否定- 例子:筛选出,第二个字符为非J且非M的数据- `SELECT col_1 FROM table_1 WHERE col_1 LIKE '_[^JM]%' ORDER BY col_1;`<a name="t01Sl"></a>## 排序ORDER BY- 默认按照升序进行排序(从小到大,从a到z),使用DESC关键字可以改为降序- 可以是单列也可以是多列排序- 可以使用非检索的列进行排序- DESC关键字的用法- 只对跟在语句前面的变量有效。所以,想要对多列进行降序排序时,需要对每一列都指定DESC关键字```sql-- 组合多列排序SELECT * FROM emp ORDER BY salary DESC, eid DESC;
聚合函数
有时候我们只是需要获取数据的汇总信息,比如说行数啊、平均值啊这种,并不需要吧所有数据都检索出来,为此,SQL提供了专门的函数,这也是SQL最强大功能之一。
| 聚合函数 | |
|---|---|
| 函数 | 说明 |
| AVG() | 返回某列的均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列的和 |
⚠️聚合函数都会忽略列中的NULL值,但是COUNT(*)也就是统计全部数据的行数时,不会忽略NULL值。
当添加DISTINCT参数时,就可以只对不同值(也就是某列中的唯一值)进行函数操作。
-- 统计表中的记录条数 使用 count()SELECT COUNT(eid) FROM emp; -- 使用某一个字段SELECT COUNT(*) FROM emp; -- 使用 *SELECT COUNT(1) FROM emp; -- 使用 1,与 * 效果一样-- 使用DISTINCT关键字SELECT AVG(DISTINCT col_1) AS avg_dist_col_1FROM table_1;
分组group by与having
定义:分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组。
语法格式:
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条件。
| 过滤方式 | 特点 |
|---|---|
| where | where 进行分组前的过滤 where 后面不能写 聚合函数 |
| having | having 是分组后的过滤 having 后面可以写 聚合函数 |
--这里我们就筛选出了具有两个以上类别的分组SELECT col_1,COUNT(*) AS num_colFROM table_1GROUP BY col_1HAVING COUNT(*) >= 2;
LIMIT关键字
limit 关键字的作用
- limit是限制的意思,用于限制返回的查询结果的行数 (可以通过limit指定查询多少行数据)
- limit 语法是 MySql的方言,用来完成分页
语法结构SELECT 字段1,字段2... FROM 表名 LIMIT offset , length;
参数说明
- limit offset , length
- 可以接受一个 或者两个 为0 或者正整数的参数
- offset:起始行数, 从0开始记数, 如果省略 则默认为 0.
- length:返回的行数
```sql
查询emp表中的前 5条数据
— 参数1 起始值,默认是0 , 参数2 要查询的条数 SELECT FROM emp LIMIT 5; SELECT FROM emp LIMIT 0 , 5;
查询emp表中 从第4条开始,查询6条
— 起始值默认是从0开始的. SELECT * FROM emp LIMIT 3 , 6;
从第五行之后,返回十行数据(即第6-第15行,下标5-14)
SELECT col_1 FROM table_name LIMIT 10 OFFSET 5;
<a name="Ip6Lr"></a>## 多表连接- 内连接: inner join , 只获取两张表中 交集部分的数据.- 左外连接: left join , 以左表为基准 ,查询左表的所有数据, 以及与右表有交集的部分- 右外连接: right join , 以右表为基准,查询右表的所有的数据,以及与左表有交集的部分内连接和左外连接使用居多<a name="KamEH"></a>### 内连接查询内连接的特点:通过指定的条件去匹配两张表中的数据,匹配上就显示,匹配不上就不显示。<a name="JInPC"></a>#### 隐式内链接概念:- form子句 后面直接写 多个表名 使用where指定连接条件的 这种连接方式是 隐式内连接- 使用where条件过滤无用的数据语法格式 :`SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;`<br />案例:<br />(1)查询所有商品信息和对应的分类信息```sql# 隐式内连接SELECT * FROM products,category WHERE category_id = cid;
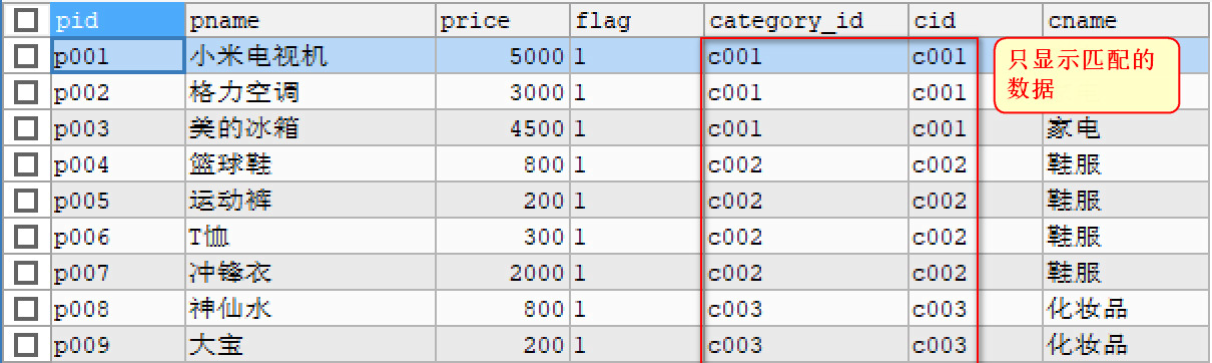
(2)查询商品表的商品名称 和 价格,以及商品的分类信息
-- 可以通过给表起别名的方式, 方便我们的查询(有提示)
SELECT
p.pname,
p.price,
c.cname
FROM products p , category c WHERE p.category_id = c.cid;
(3)查询 格力空调是属于哪一分类下的商品
-- 查询 格力空调是属于哪一分类下的商品
SELECT p.pname,c.cname FROM products p , category c
WHERE p.category_id = c.cid AND p.pname = '格力空调';

显式内连接
说明:使用 inner join …on 这种方式, 就是显式内连接
语法格式:SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件 ( inner 可以省略)
案例:
(1)查询所有商品信息和对应的分类信息
-- 显式内连接查询
SELECT * FROM products p INNER JOIN category c ON p.category_id = c.cid;
(2)查询鞋服分类下,价格大于500的商品名称和价格
# 查询鞋服分类下,价格大于500的商品名称和价格
-- 我们需要确定的几件事
-- 1.查询几张表 products & category
-- 2.表的连接条件 从表.外键 = 主表的主键
-- 3.查询的条件 cname = '鞋服' and price > 500
-- 4.要查询的字段 pname price
SELECT
p.pname,
p.price
FROM products p INNER JOIN category c ON p.category_id = c.cid
WHERE p.price > 500 AND cname = '鞋服';
外连接查询
左外连接
左外连接的特点:
- 以左表为基准,匹配右边表中的数据,如果匹配的上,就展示匹配到的数据
- 如果匹配不到,左表中的数据正常展示,右边的展示为null
语法格式:SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
案例:
(1)连接两张表
-- 左外连接查询
SELECT * FROM category c LEFT JOIN products p ON c.`cid`= p.`category_id`;
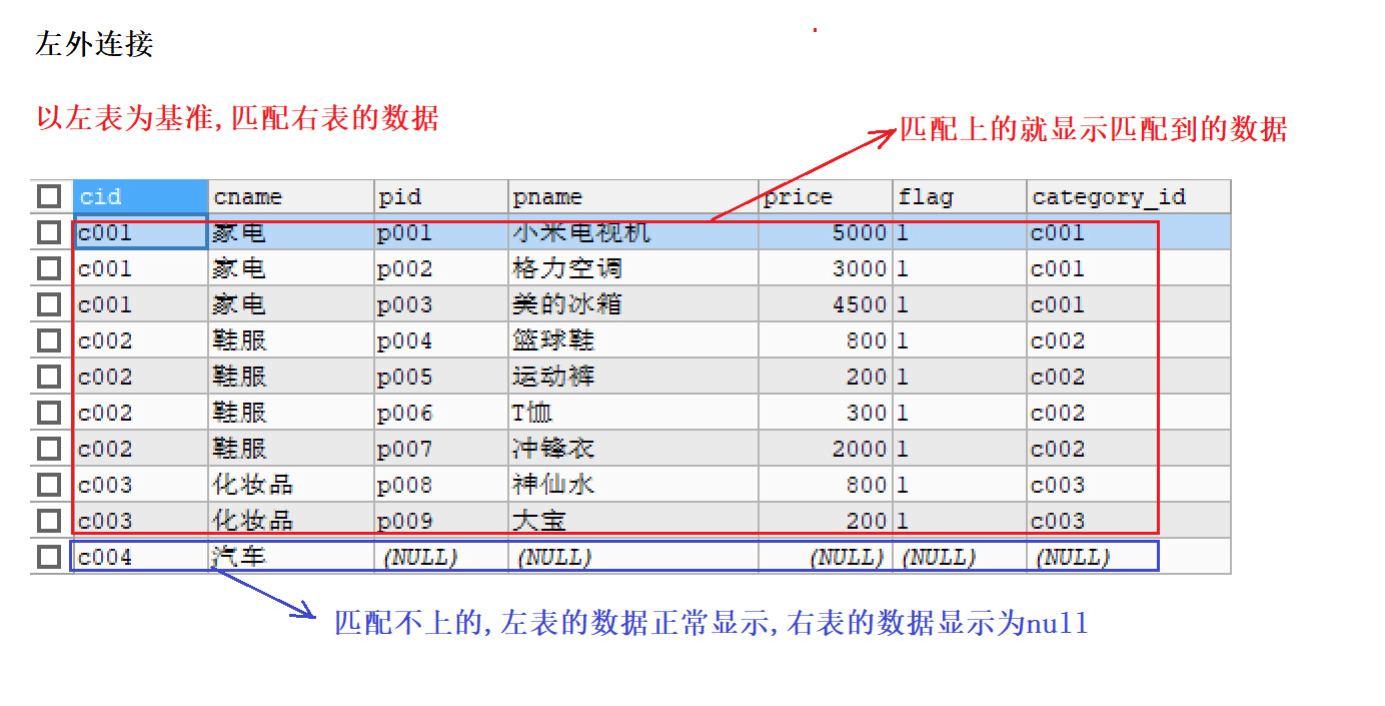
(2)查询每个分类下的商品个数
# 查询每个分类下的商品个数
/*
1.连接条件: 主表.主键 = 从表.外键
2.查询条件: 每个分类 需要分组
3.要查询的字段: 分类名称, 分类下商品个数
*/
SELECT
c.`cname` AS '分类名称',
COUNT(p.`pid`) AS '商品个数'
FROM category c LEFT JOIN products p ON c.`cid` = p.`category_id`
GROUP BY c.`cname`;

右外连接
右外连接的特点:
- 以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
- 如果匹配不到,右表中的数据正常展示, 左边展示为null
语法格式:SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
案例:
(1)连接两张表
-- 右外连接查询
SELECT * FROM products p RIGHT JOIN category c ON p.`category_id` = c.`cid`;
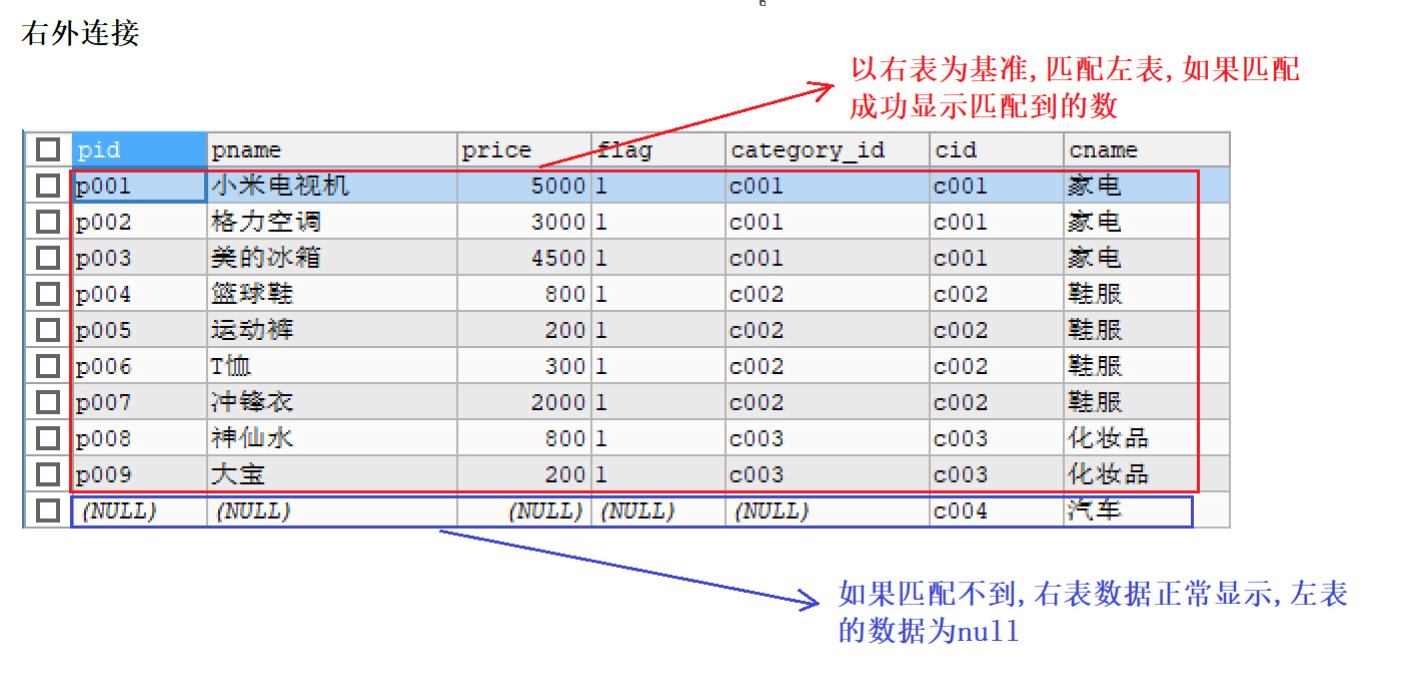
合并查询
UNION
说明:
- UNION 操作符用于合并两个或多个 SELECT 语句的结果集,并消除重复行
- UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型,同时,每条 SELECT 语句中的列的顺序必须相同。
基本语法:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
使用场景:
- 在一个查询中从不同的表返回结果
- 对一个表执行多个查询返回结果
- 多数情况下,组合相同表的多个查询所完成的任务与具有多个WHERE子句的一个查询是一样的。
以下三个语句的结果是一致的
-- 语句1:原始语句
-- 查询一
SELECT customer_name,phone_number
FROM customers
WHERE customer_state IN ('str1','str2');
--查询二
SELECT customer_name,phone_number
FROM customers
WHERE customer_state = 'str3';
-- 语句2:使用UNION链接
SELECT customer_name,phone_number
FROM customers
WHERE customer_state IN ('str1','str2')
UNION
SELECT customer_name,phone_number
FROM customers
WHERE customer_state= 'str3'
ORDER BY customer_name;
-- 在最后添加了ORDER BY对所有SELECT语句进行排序,这里只是为了示例在使用UNION时如何进行排序。
-- 语句3:使用WHERE
SELECT customer_name,phone_number
FROM customers
WHERE customer_state IN ('str1','str2')
OR customer_state = 'str3';
UNION ALL
说明:
- UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。
- UNION ALL 运算符所遵从的规则与 UNION 一致。
UNION和UNION ALL关键字都是将两个结果集合并为一个,也有区别。
- 重复值:UNION在进行表连接后会筛选掉重复的记录,而UNION ALL不会去除重复记录。
- UNION ALL只是简单的将两个结果合并后就返回。
在执行效率上,UNION ALL 要比UNION快很多,因此,若可以确认合并的两个结果集中不包含重复数据,那么就使用UNION ALL。
子查询
什么是子查询
子查询概念
- 一条select 查询语句的结果,作为另一条 select 语句的一部分
- 子查询的特点
- 子查询必须放在小括号中
- 子查询的场景中还会有另外一个特点,整个sql至少会有两个select关键字
- 子查询常见分类
— 2.将最高价格作为条件,获取商品信息 SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
<a name="A5FEc"></a>
### from型子查询
语法格式:`SELECT 查询字段 FROM (子查询)表别名 WHERE 条件; `<br />注意: 当子查询作为一张表的时候,需要起别名,否则无法访问表中的字段。<br />(1)查询商品中,价格大于500的商品信息,包括 商品名称 商品价格 商品所属分类名称
```sql
-- 1. 先查询分类表的数据
SELECT * FROM category;
-- 2.将上面的查询语句 作为一张表使用
SELECT
p.`pname`,
p.`price`,
c.cname
FROM products p
-- 子查询作为一张表使用时 要起别名 才能访问表中字段
INNER JOIN (SELECT * FROM category) c
ON p.`category_id` = c.cid WHERE p.`price` > 500;
exists型子查询
语法格式:SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
-- 子查询获取的是单列多行数据
SELECT * FROM category
WHERE cid IN (SELECT DISTINCT category_id FROM products WHERE price < 2000);
MySQL函数
数学函数
| 函数 | 作用 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| FLOOR(x) | 向下取整 ,返回不大于x的最大整数值 |
| CEIL(X) | 向上取整 ,返回不小于x的最小整数值 |
| RAND() | 返回0~1的随机数 |
| PI() | 返回圆周率的值 |
| MOD(x,y) | 返回x除以y以后的余数 |
字符串函数
| 函数 | 作用 |
|---|---|
| CONCAT(s1,s2…) | 将字符串拼接,连接为一个字符串 |
| LEFT(s,n) | 返回从字符串s开始的n最左字符 |
| RIGHT(s,n) | 返回从字符串s开始的n最右字符 |
| LENGTH(s) | 获取字符串s的长度 |
| TRIM(s) | 移除掉字串中s的字头或字尾处空格 |
| REPLACE(s,s1,s2) | 用字符串s2替代字符串s重的字符串s1 |
| SUBSTRING(s,n,len) | 截取字符串s中第n个位置开始,长度为len的字符串 |
| MID(s,n.len) | 同SUBSTRING(s,n,len) |
| REVERSE(s) | 将字符串s的顺序翻转过来 |
| POSITION(findstr in s) | 获取某一字符在字符串中的位置,这个位置是从左开始计数,最左侧第一个字符起始位置为1 |
| STRPOS(s,findstr) | 获取某一字符在字符串中的位置,这个位置是从左开始计数,最左侧第一个字符起始位置为1 |
| SUBSTR(s,start,length) | 在字符串的start处开始截取length长度的字符串 |
| COALESCE(s1,s2) | 会返回其参数中第一个不为NULL的参数,其参数必须是相同的类型 |
LEFT(phone_number, 3) -- 返回从左侧数,前3个字符
RIGHT(phone_number, 8) -- 返回从右侧数,前8个字符
LENGTH(phone_number) -- 返回phone_number的长度
POSITION(',' IN city_state) -- 返回‘,’在city_state中的位置
STRPOS(city_state, ‘,’) -- 跟上面的语句等价
SUBSTR(city_state,4,5) -- 返回city_state字符串中,以第4个字符为起始的5个字符。
CONCAT(first_name, ' ', last_name) -- 结果为:first_name last_name
--或者你也可以使用双竖线来实现上述任务
first_name || ' ' || last_name
CAST(date_column AS DATE)
-- 你也可以写成这样
date_column::DATE
--这里是将date_column转换为DATE格式的数据,其他时间相关的数据类型与样式
--对照可以参考上面写过的SQL Date数据类型,确保你想转换的数据样式与数据类型对应。
COALESCE(col_1,0) -- 将col_1中的NULL值替换为0
COALESCE(col_2,'no DATA') -- 将col_2中的NULL值替换为no DATA
日期和时间函数
SQL Date 数据类型
MySQL 使用下列数据类型在数据库中存储日期或日期/时间值:
- DATE - 格式:YYYY-MM-DD
- DATETIME - 格式:YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式:YYYY-MM-DD HH:MM:SS
- YEAR - 格式:YYYY 或 YY
| 函数 | 作用 |
| —- | —- |
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| MONTH(d) | 返回月份 |
| YEAR(d) | 返回年份 |
| DATE_TRUNC(‘datepart’, timestamp) | 将日期截取到特定部分
其中datepart即为截取依据,后面的timestamp类型可以参考上面的Date数据类型 | | DATE_PART (‘datepart’, date或timestamp) | 获取日期的特定部分
如获取日期2018-10-6的月份,只会获得一个结果10 | | DATEDIFF(‘datepart’,startdate,enddate) | 获取日期时间间隔 | | TO_DATE(col_name,’datepart’) | 将某列转为DATE格式,主要是将单独的月份或者年份等等转换为SQL可以读懂的DATE类型数据
这样做的目的是为了后续可以方便地使用时间筛选函数 |
datepart对应表
| 日期部分或时间部分 | 缩写 |
|---|---|
| 世纪 | c、cent、cents |
| 十年 | dec、decs |
| 年 | y、yr、yrs |
| 季度 | qtr、qtrs |
| 月 | mon、mons |
| 周 | w,与 DATE_TRUNC一起使用时将返回离时间戳最近的一个星期一的日期 |
| 一周中的日 ( DATE_PART支持) |
dayofweek、dow、dw、weekday 返回 0–6 的整数(星期日是0,星期六是6) |
| 一年中的日 ( DATE_PART支持) |
dayofyear、doy、dy、yearday |
| 日 | d |
| 小时 | h、hr、hrs |
| 分钟 | m、min、mins |
| 秒 | s、sec、secs |
| 毫秒 | ms、msec、msecs、msecond、mseconds、millisec、millisecs、millisecon |
--DATE_TRUN函数
SELECT DATE_TRUNC('y',col_date) col_year
FROM table_1
GROUP BY 1
ORDER BY 1 DESC
LIMIT 10; --如上,我们将col_date列按照年(’y’)进行了分组,并按由大至小的顺序排序,取前10组数据。
--TO_DATE函数
TO_DATE(col_name, 'DD Mon YYYY'); --这里是将col_name这列按照datepart转化为DATE类型的数据。
条件判断函数
| 函数 | 作用 |
|---|---|
| IF(expo,v1,v2) | 如果表达式成立,则执行v1,否则执行v2 |
| CASE WHEN | 用于计算条件列表并返回多个可能结果表达式之一 |
-- IF(expo,v1,v2)
SELECT IF(10>5,10,5) as 最大值;
select if(10>2,10,2);
select pname,if(price>2000,'奢侈品','普通商品') '商品性质' from products;
select pname,if(price>2000,price-1000,price) '优惠后的价格' from products;
-- CASE WHEN
SELECT CASE WHEN 10>5 THEN 10 ELSE 5 END AS 最大值;
case
when 条件1 then 结果1
when 条件2 then 结果2
when ... then 结果n
(else 结果n+1)
end
CASE WHEN注意事项:
- CASE 语句始终位于 SELECT 条件中
- CASE 必须包含以下几个部分:WHEN、THEN和 END。ELSE 是可选组成部分,用来包含不符合上述任一 CASE 条件的情况。
- 可以在 WHEN 和 THEN之间使用任何条件运算符编写任何条件语句(例如 WHERE),包括使用 AND 和 OR 连接多个条件语句。
使用示例:
SELECT account_id, unit_name,
CASE WHEN standard_qty = 0 OR standard_qty IS NULL THEN 0
ELSE standard_amt_usd / standard_qty
END AS unit_price
FROM orders
LIMIT 10;
-- 如上,当standard_qty为0或者不存在时我们返回0,当standard_qty不为0时进行计算,并储存为新列unit_price。
系统信息函数
| 函数 | 作用 |
|---|---|
| VERSION() | 返回数据库的版本号 |
| DATABASES() | 返回当前数据库名 |
| USER() | 返回当前用户名 |
临时表格 WITH
这种方法,就是使用WITH将子查询的部分创建为一个临时表格,然后再进行查询即可。
WITH sub AS(
SELECT day,channel, COUNT(*) AS events
FROM web_events
GROUP BY 1,2
ORDER BY 3 DESC) -- 创建临时表格
SELECT *
FROM sub -- 对临时表格进行检索
GROUP BY channel
ORDER BY 2 DESC; -- 这里是根据临时表格的第二列(channel)进行排序
窗口函数

若有收获,就点个赞吧
0 人点赞
