什么是索引
- 定义:索引是依靠某些数据结构和算法来组织数据,最终引导⽤户快速检索出所需要的数据
- 特点
- 通过数据结构和算法来对原始的数据进⾏⼀些有效的组织
- 通过这些有效的组织,可以引导使⽤者对原始数据进⾏快速检索
MySQL索引原理详解
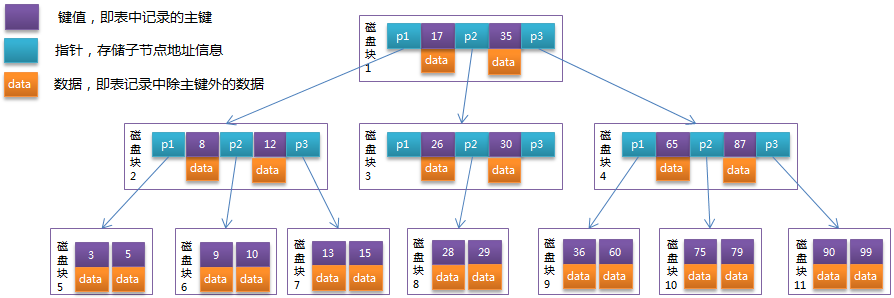
- 机械硬盘磁盘块:⽂件系统与磁盘交互的的最⼩单位(计算机系统读写磁盘的最⼩单位),⼀个磁盘块由连续⼏个(
2^n)扇区组成,块⼀般⼤⼩⼀般为4KB - 数据检索过程:我们对数据存储⽅式不做任何优化,直接将数据库中表的记录存储在磁盘中,假如某个表只有⼀个字段,为int类型,int占⽤4个byte,每个磁盘块可以存储1000条记录,100万的记录需要1000个磁盘块,如果我们需要从这100万记录中检索所需要的记录,需要读取1000个磁盘块的数据(需要1000次io),每次io需要9ms,那么1000次需要9000ms=9s,100万条数据随便⼀个查询就是9秒,这种情况我们是⽆法接受的,显然是不⾏的
- 迫切需求
- 需要⼀种数据存储结构:当从磁盘中检索数据的时候能够减少磁盘的io次数,最好能够降低到⼀个稳定的常量值
- 需要⼀种检索算法:当从磁盘中读取磁盘块的数据之后,这些块中可能包含多条记录,这些记录被加载到内存中,那么需要⼀种算法能够快速从内存多条记录中快速检索出⽬标数据
- 循环遍历查找:从⼀组⽆序的数据中查找⽬标数据,常见的⽅法是遍历查询,n条数据,时间复杂度为O(n),最快需要1次,最坏的情况需要n次,查询效率不稳定
- ⼆分法查找:定位数据⾮常快,前提是:⽬标数组是有序的
- 有序数组:如果我们将mysql中表的数据以有序数组的⽅式存储在磁盘中,那么我们定位数据步骤是
- 取出⽬标表的所有数据,存放在⼀个有序数组中
- 如果⽬标表的数据量⾮常⼤,从磁盘中加载到内存中需要的内存也⾮常⼤
- 上步取出所有数据耗费的io次数太多,且耗费的内存空间太⼤,还有新增数据的时候,为了保证数组有序,插⼊数据会涉及到数组内部数据的移动,也是⽐较耗时的,显然⽤这种⽅式存储数据是不可取的
- 链表:分为单链表和双向链表
- 单链表:每个节点中有持有指向下⼀个节点的指针,只能按照⼀个⽅向遍历链表
- 双向链表:每个节点中两个指针,分别指向当前节点的上⼀个节点和下⼀个节点
- 链表的优点:
- 可以快速定位到上⼀个或者下⼀个节点
- 可以快速删除数据,只需改变指针的指向即可,这点⽐数组好
- 链表的缺点:
- ⽆法向数组那样,通过下标随机访问数据
- 查找数据需从第⼀个节点开始遍历,不利于数据的查找,查找时间和⽆需数据类似,需要全遍历,最差时间是O(N)
- ⼆叉查找树:⼆叉树是每个结点最多有两个⼦树的树结构,通常⼦树被称作“左⼦树”(left subtree)和“右⼦树”(right subtree)。⼆叉树常被⽤于实现⼆叉查找树和⼆叉堆。
- ⼆叉树有如下特性:
- 每个结点都包含⼀个元素以及n个⼦树,这⾥0≤n≤2。
- 左⼦树和右⼦树是有顺序的,次序不能任意颠倒,左⼦树的值要⼩于⽗结点,右⼦树的值要⼤于⽗结点
- 可以通过这2个指针快速访问左右⼦节点,时间为O(logN),和⼆分法查找效率⼀样,查询数据还是⽐较快的
- ⼆叉树的优缺点:
- 查询数据的效率不稳定,若树左右⽐较平衡的时,最差情况为O(logN),如果插⼊数据是有序的,退化为了链表,查询时间变成了O(N)
- 数据量⼤的情况下,会导致树的⾼度变⾼,如果每个节点对应磁盘的⼀个块来存储⼀条数据,需io次数⼤幅增加,显然⽤此结构来存储数据是不可取的
- ⼆叉树有如下特性:
- 平衡⼆叉树(AVL树)
- 平衡⼆叉树是⼀种特殊的⼆叉树,所以他也满⾜前⾯说到的⼆叉查找树的两个特性
- 它的左右两个⼦树的⾼度差的绝对值不超过1,并且左右两个⼦树都是⼀棵平衡⼆叉树
- 平衡⼆叉树相对于⼆叉树来说,树的左右⽐较平衡,不会出现⼆叉树那样退化成链表的情况,不管怎么插⼊数据,最终通过⼀些调整,都能够保证树左右⾼度相差不⼤于1
- 这样可以让查询速度⽐较稳定,查询中遍历节点控制在O(logN)范围内
- 如果数据都存储在内存中,采⽤AVL树来存储,还是可以的,查询效率⾮常⾼。不过我们的数据是存在磁盘中,⽤过采⽤这种结构,每个节点对应⼀个磁盘块,数据量⼤的时候,也会和⼆叉树⼀样,会导致树的⾼度变⾼,增加了io次数,显然⽤这种结构存储数据也是不可取的
- B-树
- B杠树,在平衡⼆叉树上进化来的,前⾯介绍的⼏种树,每个节点上⾯只有⼀个元素,⽽B-树节点中可以放多个元素,主要是为了降低树的⾼度
- 有如下特性:
- 每个节点最多有m个孩⼦,m称为b树的阶
- 除了根节点和叶⼦节点外,其它每个节点⾄少有Ceil(m/2)个孩⼦
- 若根节点不是叶⼦节点,则⾄少有2个孩⼦
- 所有叶⼦节点都在同⼀层,且不包含其它关键字信息
- 每个⾮终端节点包含n个关键字(健值)信息
- 关键字的个数n满⾜:ceil(m/2)-1 <= n <= m-1
- ki(i=1,…n)为关键字,且关键字升序排序
- Pi(i=1,…n)为指向⼦树根节点的指针。P(i-1)指向的⼦树的所有节点关键字均⼩于ki,但都⼤于k(i-1)
- 缺点:B-不利于范围查找
- b+树
- 特征
- 每个结点⾄多有m个⼦⼥
- 除根结点外,每个结点⾄少有[m/2]个⼦⼥,根结点⾄少有两个⼦⼥
- 有k个⼦⼥的结点必有k个关键字
- ⽗节点中持有访问⼦节点的指针
- ⽗节点的关键字在⼦节点中都存在(如上⾯的1/20/35在每层都存在),要么是最⼩值,要么是最⼤值,如果节点中关键字是升序的⽅式,⽗节点的关键字是⼦节点的最⼩值
- 最底层的节点是叶⼦节点
- 除叶⼦节点之外,其他节点不保存数据,只保存关键字和指针
- 叶⼦节点包含了所有数据的关键字以及data,叶⼦节点之间⽤链表连接起来,可以⾮常⽅便的⽀持范围查找
- 特征

- b+树与b-树的⼏点不同
- b+树中⼀个节点如果有k个关键字,最多可以包含k个⼦节点(k个关键字对应k个指针);⽽b-树对应k+1个⼦节点(多了⼀个指向⼦节点的指针)
- b+树除叶⼦节点之外其他节点值存储关键字和指向⼦节点的指针,⽽b-树还存储了数据,这样同样⼤⼩情况下,b+树可以存储更多的关键字
- b+树叶⼦节点中存储了所有关键字及data,并且多个节点⽤链表连接,从上图中看⼦节点中数据从左向右是有序的,这样快速可以⽀撑范围查找(先定位范围的最⼤值和最⼩值,然后⼦节点中依靠链表遍历范围数据)
- B-Tree和B+Tree该如何选择
- B-Tree因为⾮叶⼦结点也保存具体数据,所以在查找某个关键字的时候找到即可返回。⽽B+Tree所有的数据都在叶⼦结点,每次查找都得到叶⼦结点。所以在同样⾼度的B-Tree和B+Tree中,B-Tree查找某个关键字的效率更⾼
- 由于B+Tree所有的数据都在叶⼦结点,并且结点之间有指针连接,在找⼤于某个关键字或者⼩于某个关键字的数据的时候,B+Tree只需要找到该关键字然后沿着链表遍历就可以了,⽽B-Tree还需要遍历该关键字结点的根结点去搜索
- 由于B-Tree的每个结点(这⾥的结点可以理解为⼀个数据页)都存储主键+实际数据,⽽B+Tree⾮叶⼦结点只存储关键字信息,⽽每个页的⼤⼩有限是有限的,所以同⼀页能存储的B-Tree的数据会⽐B+Tree存储的更少。这样同样总量的数据,B-Tree的深度会更⼤,增⼤查询时的磁盘I/O次数,进⽽影响查询效率
- Mysql的存储引擎和索引:内部索引是由不同的引擎实现的,主要说⼀下InnoDB和MyISAM这两种引擎中的索引,这两种引擎中的索引都是使⽤b+树的结构来存储的
- InnoDB中的索引
- 主键索引:每个表只有⼀个主键索引,b+树结构,叶⼦节点同时保存了主键的值也数据记录,其他节点只存储主键的值。
- 辅助索引:每个表可以有多个,b+树结构,叶⼦节点保存了索引字段的值以及主键的值,其他节点只存储索引指端的值。
- MyISAM引擎中的索引
- B+树结构,MyISM使⽤的是⾮聚簇索引,⾮聚簇索引的两棵B+树看上去没什么不同,节点的结构完全⼀致只是存储的内容不同⽽已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独⽴的地⽅,这两颗B+树的叶⼦节点都使⽤⼀个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独⽴的,通过辅助键检索⽆需访问主键的索引树
- InnoDB中的索引

- InnoDB数据检索过程
- 如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了
- 如果需要搜索name=’Ellison’的数据,需要2步:
- 先在辅助索引中检索到name=’Ellison’的数据,获取id为14
- 再到主键索引中检索id为14的记录
- 辅助索引这个查询过程在mysql中叫做回表
- MyISAM数据检索过程
- 在索引中找到对应的关键字,获取关键字对应的记录的地址
- 通过记录的地址查找到对应的数据记录
- innodb查询:最好是采⽤主键查询,这样只需要⼀次索引,如果使⽤辅助索引检索,涉及到回表操作,⽐主键查询要耗时⼀些
- 辅助索引为什么不像myisam那样存储记录的地址
- 表中的数据发⽣变更的时候,会影响其他记录地址的变化,如果辅助索引中记录数据的地址,此时会受影响,⽽主键的值⼀般是很少更新的,当页中的记录发⽣地址变更的时候,对辅助索引是没有影响的
- ⻚结构
- mysql中页是innodb中存储数据的基本单位,也是mysql中管理数据的最⼩单位,和磁盘交互的时候都是以页来进⾏的,默认是16kb,mysql中采⽤b+树存储数据,页相当于b+树中的⼀个节点
- 每个Page都有通⽤的头和尾,但是中部的内容根据Page的类型不同⽽发⽣变化。Page的头部⾥有我们关⼼的⼀些数据
- Page的头部保存了两个指针,分别指向前⼀个Page和后⼀个Page,根据这两个指针我们很容易想象出Page链接起来就是⼀个双向链表的结构
- innodb为了快速查找记录,在页中定义了⼀个称之为page directory的⽬录槽(slots),每个槽位占⽤两个字节(⽤于保存指向记录的地址),page directory中的多个slot组成了⼀个有序数组(可⽤于⼆分法快速定位记录,向下看),⾏记录被Page Directory逻辑的分成了多个块,块与块之间是有序的,能够加速记录的查找
- 数据检索过程
- 在page中查询数据的时候,先通过b+树中查询⽅法定位到数据所在的页,然后将页内整体加载到内存中,通过⼆分法在page directory中检索数据,缩⼩范围
- 对page的结构总结⼀下
- b+树中叶⼦页之间⽤双向链表连接的,能够实现范围查找
- 页内部的记录之间是采⽤单向链表连接的,⽅便访问下⼀条记录
- 为了加快页内部记录的查询,对页内记录上加了个有序的稀疏索引,叫页⽬录(page directory)
- 整体上来说mysql中的索引⽤到了b+树,链表,⼆分法查找,做到了快速定位⽬标数据,快速范围查找
MySQL索引管理
- 索引分类
- 聚集索引:每个表有且⼀定会有⼀个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采⽤B+树结构保存在⽂件中,叶⼦节点存储主键的值以及对应记录的数据,⾮叶⼦节点不存储记录的数据,只存储主键的值。当表中未指定主键时,mysql内部会⾃动给每条记录添加⼀个隐藏的rowid字段(默认4个字节)作为主键,⽤rowid构建聚集索引。聚集索引在mysql中又叫主键索引
- ⾮聚集索引(辅助索引):也是b+树结构,不过有⼀点和聚集索引不同,⾮聚集索引叶⼦节点存储字段(索引字段)的值以及对应记录主键的值,其他节点只存储字段的值(索引字段);每个表可以有多个⾮聚集索引
- ⾮聚集索引分为
- 单列索引:即⼀个索引只包含⼀个列
- 多列索引(⼜称复合索引):即⼀个索引包含多个列
- 唯⼀索引:索引列的值必须唯⼀,允许有⼀个空值
- 数据检索的过程
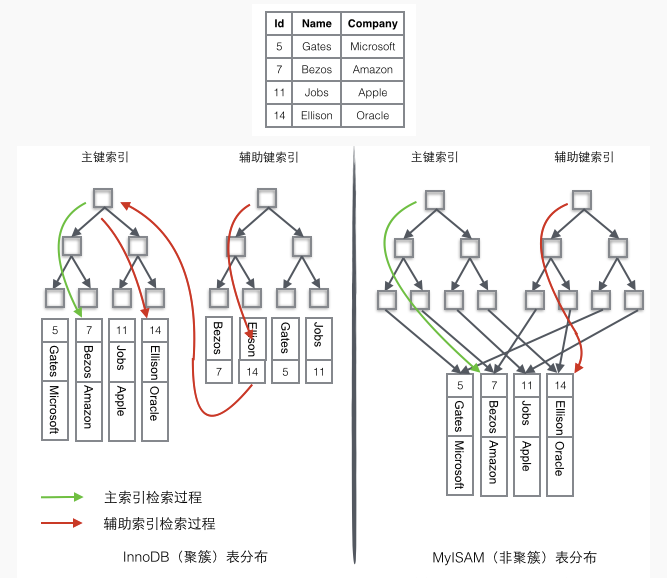
上⾯的表中有2个索引:id作为主键索引,name作为辅助索引。innodb我们⽤的最多,我们只看图中左边的innodb中数据检索过程:如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了。如果需要搜索name='Ellison'的数据,需要2步:1. 先在辅助索引中检索到name='Ellison'的数据,获取id为142. 再到主键索引中检索id为14的记录辅助索引相对于主键索引多了第⼆步
- 索引管理
- 创建索引
- ⽅式1:
create [unique] index 索引名称 on 表名(列名[(length)]) - ⽅式2:
alter 表名 add [unique] index 索引名称 on (列名[(length)]);- 如果字段是char、varchar类型,length可以⼩于字段实际长度,如果是blog、text等长⽂本类型,必须指定length
- [unique]:中括号代表可以省略,如果加上了unique,表⽰创建唯⼀索引
- 如果table后⾯只写⼀个字段,就是单列索引,如果写多个字段,就是复合索引,多个字段之间⽤逗号隔开
- ⽅式1:
- 删除索引
drop index 索引名称 on 表名;
- 查看索引
show index from 表名;,查看某个表中所有的索引信息
- 索引修改
- 可以先删除索引,再重建索引
- 创建索引并指定⻓度
- 对email创建索引的时候指定⼀个长度为15,这样相对于整个email字段更短⼀些,查询效果是⼀样的,这样⼀个页中可以存储更多的索引记录
create index idx3 on test1 (email(15));
- 创建索引
如何正确的使⽤索引
- 先来回顾⼀些知识
- mysql采⽤b+树的⽅式存储索引信息
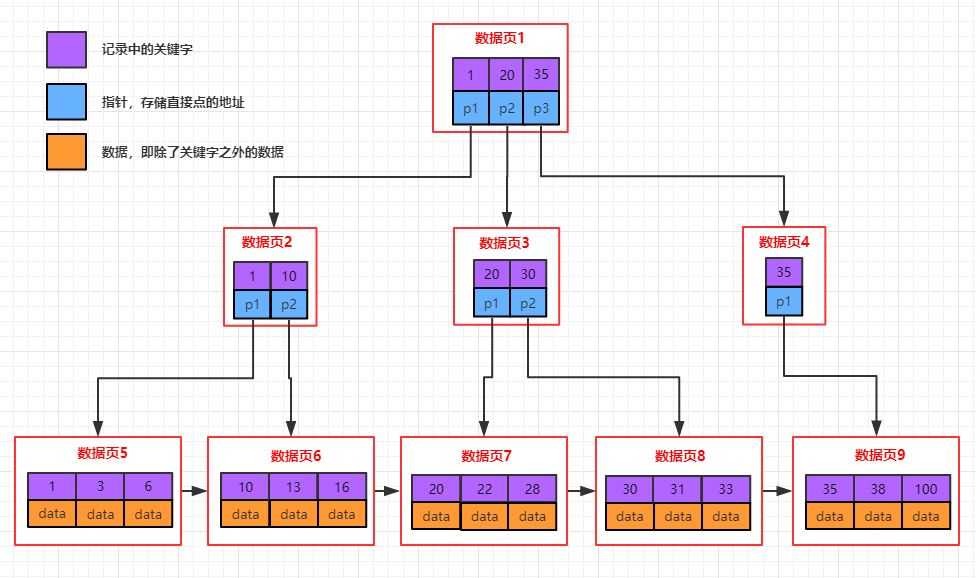
- b+树的⼏个特点
- 叶⼦节点(最下⾯的⼀层)存储关键字(索引字段的值)信息及对应的data,叶⼦节点存储了所有记录的关键字信息
- 其他⾮叶⼦节点只存储关键字的信息及⼦节点的指针
- 每个叶⼦节点相当于mysql中的⼀页,同层级的叶⼦节点以双向链表的形式相连
- 每个节点(页)中存储了多条记录,记录之间⽤单链表的形式连接组成了⼀条有序的链表,顺序是按照索引字段排序的
- b+树中检索数据时:每次检索都是从根节点开始,⼀直需要搜索到叶⼦节点
- InnoDB的数据是按数据页为单位来读写的。也就是说,当需要读取⼀条记录的时候,并不是将这个记录本⾝从磁盘读取出来,⽽是以页为单位,将整个也加载到内存中,⼀个页中可能有很多记录,然后在内存中对页进⾏检索。在innodb中,每个页的⼤⼩默认是16kb
- Mysql中索引分为
- 聚集索引(主键索引):每个表⼀定会有⼀个聚集索引,整个表的数据存储以b+树的⽅式存在⽂件中,b+树叶⼦节点中的key为主键值,data为完整记录的信息;⾮叶⼦节点存储主键的值。通过聚集索引检索数据只需要按照b+树的搜索过程,即可以检索到对应的记录
- ⾮聚集索引:每个表可以有多个⾮聚集索引,b+树结构,叶⼦节点的key为索引字段字段的值,data为主键的值;⾮叶⼦节点只存储索引字段的值。通过⾮聚集索引检索记录的时候,需要2次操作,先在⾮聚集索引中检索出主键,然后再到聚集索引中检索出主键对应的记录,该过程⽐聚集索引多了⼀次操作
- 通常说的这个查询⾛索引了是什么意思:当我们对某个字段的值进⾏某种检索的时候,如果这个检索过程中,我们能够快速定位到⽬标数据所在的页,有效的降低页的io操作,⽽不需要去扫描所有的数据页的时候,我们认为这种情况能够有效的利⽤索引,也称这个检索可以⾛索引,如果这个过程中不能够确定数据在那些页中,我们认为这种情况下索引对这个查询是⽆效的,此查询不⾛索引
- b+树中数据检索过程
- 唯⼀记录检索:查询105的记录,过程如下
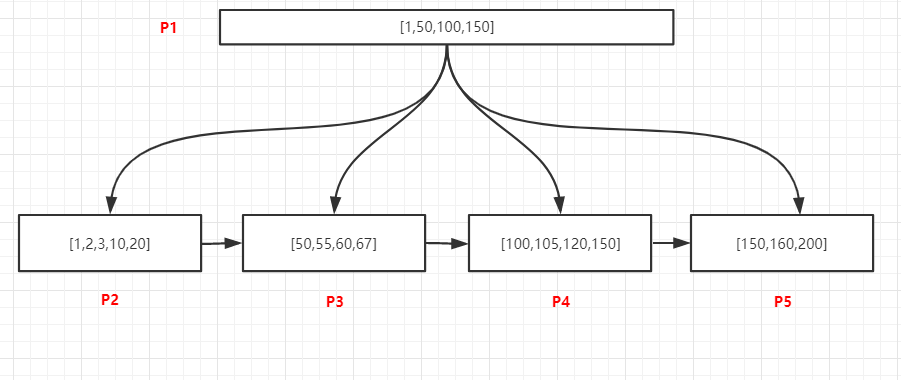
- 将P1页加载到内存- 在内存中采⽤⼆分法查找,可以确定105位于[100,150)中间,所以我们需要去加载100关联P4页- 将P4加载到内存中,采⽤⼆分法找到105的记录后退出
- 查询某个值的所有记录:查询105的所有记录,过程如下
- 将P1页加载到内存- 在内存中采⽤⼆分法查找,可以确定105位于[100,150)中间,100关联P4页- 将P4加载到内存中,采⽤⼆分法找到最右⼀个⼩于105的记录,即100,然后通过链表从100开始向后访问,找到所有的105记录,直到遇到第⼀个⼤于105的值为⽌
- 范围查找:查询[55,150]所有记录,由于页和页之间是双向链表升序结构,页内部的数据是单项升序链表结构,所以只⽤找到范围的起始值所在的位置,然后通过依靠链表访问两个位置之间所有的数据即可,过程如下
- 将P1页加载到内存- 内存中采⽤⼆分法找到55位于50关联的P3页中,150位于P5页中- 将P3加载到内存中,采⽤⼆分法找到第⼀个55的记录,然后通过链表结构继续向后访问P3中的60、67,当P3访问完毕之后,通过P3的nextpage指针访问下⼀页P4中所有记录,继续遍历P4中的所有记录,直到访问到P5中的150为
- 模糊匹配:查询以f开头的所有记录
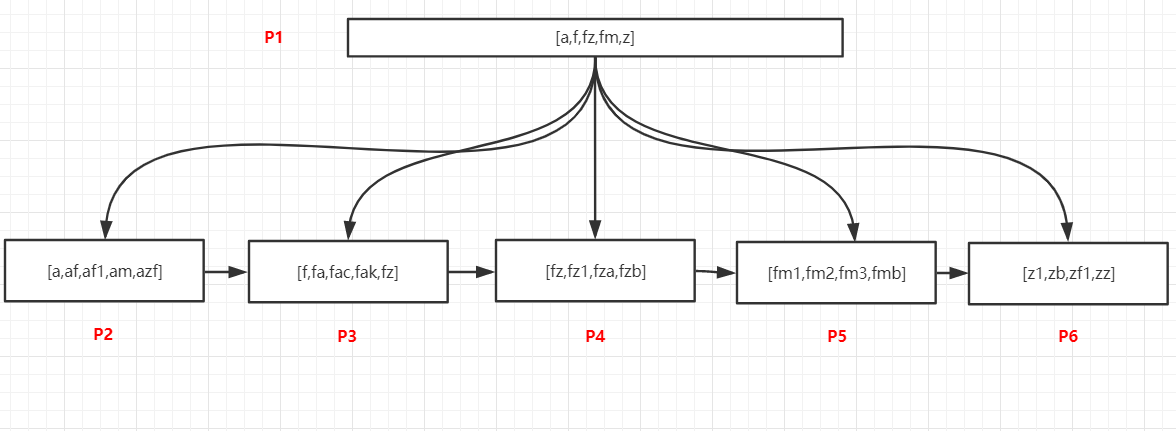
- 将P1数据加载到内存中- 在P1页的记录中采⽤⼆分法找到最后⼀个⼩于等于f的值,这个值是f,以及第⼀个⼤于f的,这个值是z,f指向叶节点P3,z指向叶节点P6,此时可以断定以f开头的记录可能存在于[P3,P6)这个范围的页内,即P3、P4、P5这三个页中- 加载P3这个页,在内部以⼆分法找到第⼀条f开头的记录,然后以链表⽅式继续向后访问P4、P5中的记录,即可以找到所有已f开头的数据
- 查询包含f的记录
- 包含的查询在sql中的写法是%f%
- 可以看⼀下上⾯的数据,f在每个页中都存在,我们通过P1页中的记录是⽆法判断包含f的记录在那些页的,只能通过io的⽅式加载所有叶⼦节点,并且遍历所有记录进⾏过滤,才可以找到包含f的记录
- 所以如果使⽤了%值%这种⽅式,索引对查询是⽆效的
- 最左匹配原则
当b+树的数据项是复合的数据结构,⽐如(name,age,sex)的时候,b+树是按照从左到右的顺序来建⽴搜索树的,⽐如当(张三,20,F)这样的数据来检索的时候,b+树会优先⽐较name来确定下⼀步的所搜⽅向,如果name相同再依次⽐较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下⼀步该查哪个节点,因为建⽴搜索树的时候name就是第⼀个⽐较因⼦,必须要先根据name来搜索才能知道下⼀步去哪⾥查询。⽐如当(张三,F)这样的数据来检索时,b+树可以⽤name来指定搜索⽅向,但下⼀个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是⾮常重要的性质,即索引的最左匹配特性。
- 下图中是3个字段(a,b,c)的联合索引,索引中数据的顺序是以a asc,b asc,c asc这种排序⽅式存储在节点中的,索引先以a字段升序,如果a相同的时候,以b字段升序,b相同的时候,以c字段升序

- 查询a=1的记录:由于页中的记录是以a asc,b asc,c asc这种排序⽅式存储的,所以a字段是有序的,可以通过⼆分法快速检索到,过程如下
- 将P1加载到内存中
- 在内存中对P1中的记录采⽤⼆分法找,可以确定a=1的记录位于{1,1,1}和{1,5,1}关联的范围内,这两个值⼦节点分别是P2、P4
- 加载叶⼦节点P2,在P2中采⽤⼆分法快速找到第⼀条a=1的记录,然后通过链表向下⼀条及下⼀页开始检索,直到在P4中找到第⼀个不满⾜a=1的记录为⽌
- 查询a=1 and b=5的记录
- ⽅法和上⾯的⼀样,可以确定a=1 and b=5的记录位于{1,1,1}和{1,5,1}关联的范围内,查找过程和a=1查找步骤类似
- 查询b=1的记录
- 这种情况通过P1页中的记录,是⽆法判断b=1的记录在那些页中的,只能加载索引树所有叶⼦节点,对所有记录进⾏遍历,然后进⾏过滤,此时索引是⽆效的
- 按照c的值查询
- 这种情况和查询b=1也⼀样,也只能扫描所有叶⼦节点,此时索引也⽆效了
- 按照b和c⼀起查
- 这种也是⽆法利⽤索引的,也只能对所有数据进⾏扫描,⼀条条判断了,此时索引⽆效
- 按照[a,c]两个字段查询
- 这种只能利⽤到索引中的a字段了,通过a确定索引范围,然后加载a关联的所有记录,再对c的值进⾏过滤
- 查询a=1 and b>=0 and c=1的记录
- 只能先确定a=1 and b>=0所在页的范围,然后对这个范围的所有页进⾏遍历,c字段在这个查询的过程中,是⽆法确定c的数据在哪些页的,此时我们称c是不⾛索引的,只有a、b能够有效的确定索引页的范围
- 类似这种的还有>、<、between and,多字段索引的情况下,mysql会⼀直向右匹配直到遇到范围查询(>、<、between、like)就停⽌匹配
- 索引区分度
- 索引区分度 = count(distint 记录) / count(记录)
- 当索引区分度⾼的时候,检索数据更快⼀些,索引区分度太低,说明重复的数据⽐较多,检索的时候需要访问更多的记录才能够找到所有⽬标数据
- 当索引区分度⾮常⼩的时候,基本上接近于全索引数据的扫描了,此时查询速度是⽐较慢的
- 创建索引的时候,尽量选择区分度⾼的列作为索引
- 正确使⽤索引
- ⽆索引检索效果:全表扫描
- 主键检索:速度很快,⾛的是唯⼀记录检索
- between and范围检索:速度也很快,采⽤的上⾯介绍的范围查找可以快速定位⽬标数据;但是如果范围太⼤,跨度的page也太多,速度也会⽐较慢;所以使⽤between and的时候,区间跨度不要太⼤
- in的检索:平时我们做项⽬的时候,建议少⽤表连接,⽐如电商中需要查询订单的信息和订单中商品的名称,可以先查询查询订单表,然后订单表中取出商品的id列表,采⽤in的⽅式到商品表检索商品信息,由于商品id是商品表的主键,所以检索速度还是⽐较快的
- 多个索引时查询如何⾛:当多个条件中有索引的时候,并且关系是and的时候,会⾛索引区分度⾼的
- 模糊查询:全表扫描,⽆法利⽤索引,所以速度⽐较慢
- 回表:在索引树中不存在的时候,需要再次到聚集索引中去获取
- 索引覆盖:查询中采⽤的索引树中包含了查询所需要的所有字段的值,不需要再去聚集索引检索数据
select id,name from test1 where name='javacode3500000';- name对应idx1索引,id为主键,所以idx1索引树叶⼦节点中包含了name、id的值,这个查询只⽤⾛idx1这⼀个索引就可以了,如果select后⾯使⽤*,还需要⼀次回表获取sex、email的值
- 所以写sql的时候,尽量避免使⽤,可能会多⼀次回表操作,需要看⼀下是否可以使⽤索引覆盖来实现,效率更⾼⼀些
- 索引下推:简称ICP,Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是⼀种在存储引擎层使⽤索引过滤数据的⼀种优化⽅式,ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数,比如,
select count(id) from test1 a where name like 'javacode35%' and sex = 1;,过程如下:- ⾛name索引检索出以javacode35的第⼀条记录,得到记录的id
- 利⽤id去主键索引中查询出这条记录R1
- 判断R1中的sex是否为1,然后重复上⾯的操作,直到找到所有记录为⽌
- 上⾯的过程中需要⾛name索引以及需要回表操作,如果采⽤ICP的⽅式,我们可以这么做,创建⼀个(name,sex)的组合索引,查询过程如下
- ⾛(name,sex)索引检索出以javacode35的第⼀条记录,可以得到(name,sex,id),记做R1
- 判断R1.sex是否为1,然后重复上⾯的操作,知道找到所有记录为⽌
- 这个过程中不需要回表操作了,通过索引的数据就可以完成整个条件的过滤,速度⽐上⾯的更快⼀些
- 数字使字符串类索引失效
select * from test1 where name = 1;,字符串和数字⽐较的时候,会将字符串强制转换为数字,然后进⾏⽐较,所以第⼆个查询变成了全表扫描,只能取出每条数据,将name转换为数字和1进⾏⽐较- 而如果字段是数组类型的,查询的值是字符串还是数组都会⾛索引
- 函数使索引⽆效:使⽤了函数之后,索引树是⽆法快速定位需要查找的数据所在的页的,只能将所有页的记录加载到内存中,然后对每条数据使⽤函数进⾏计算之后再进⾏条件判断,此时索引⽆效了,变成了全表数据扫描
- 运算符使索引⽆效:使⽤运算符,索引树是⽆法快速定位需要查找的数据所在的页的,只能将所有页的记录加载到内存中,然后对每条数据的目前字段进⾏计算之后再判断是否等于目标值,此时索引⽆效了,变成了全表数据扫描
- 使⽤索引优化排序
- 我们有个订单表torder(id,userid,addtime,price),经常会查询某个⽤户的订单,并且按照addtime升序排序,我们来分析⼀下
- 在user_id上创建索引,这种情况数据检索的过程
- 1、⾛user_id索引,找到记录的的id
- 2、通过id在主键索引中回表检索出整条数据
- 3、重复上⾯的操作,获取所有⽬标记录
- 4、在内存中对⽬标记录按照addtime进⾏排序
- 当数据量⾮常⼤的时候,排序还是⽐较慢的,可能会⽤到磁盘中的⽂件,有没有⼀种⽅式,查询出来的数据刚好是排好序的
- 再回顾⼀下mysql中b+树数据的结构,记录是按照索引的值排序组成的链表
- 如果将userid和addtime放在⼀起组成联合索引(userid,addtime),这样通过user_id检索出来的数据⾃然就是按照addtime排好序的,这样直接少了⼀步排序操作,效率更好,如果需addtime降序,只需要将结果翻转⼀下就可以了
- 总结⼀下使⽤索引的⼀些建议
- 在区分度⾼的字段上⾯建⽴索引可以有效的使⽤索引,区分度太低,⽆法有效的利⽤索引,可能需要扫描所有数据页,此时和不使⽤索引差不多
- 联合索引注意最左匹配原则:必须按照从左到右的顺序匹配,mysql会⼀直向右匹配直到遇到范围查询(>、<、between、like)就停⽌匹配,⽐如a = 1 and b = 2 and c > 3 and d = 4 ,如果建⽴(a,b,c,d)顺序的索引,d是⽤不到索引的,如果建⽴(a,b,d,c)的索引则都可以⽤到,a,b,d的顺序可以任意调整
- 查询记录的时候,少使⽤*,尽量去利⽤索引覆盖,可以减少回表操作,提升效率
- 有些查询可以采⽤联合索引,进⽽使⽤到索引下推(IPC),也可以减少回表操作,提升效率
- 禁⽌对索引字段使⽤函数、运算符操作,会使索引失效
- 字符串字段和数字⽐较的时候会使索引⽆效
- 模糊查询’%值%’会使索引⽆效,变为全表扫描,但是’值%’这种可以有效利⽤索引
- 排序中尽量使⽤到索引字段,这样可以减少排序,提升查询效率

若有收获,就点个赞吧
0 人点赞
