用Python实现表间血缘管理
数据血缘介绍
数据血缘定义:表B数据内容的变化会影响表C,则BC间存在血缘关系,B是C的第一层上游表。但假使B又有上游表A,则A是C的第二层上游表。AB共为C的上游表。
根据以上,定义:C的上游表={A,B},里面包含了两个元素。
举例来说,如下图所示,「T到货清单SKC副本_01」的第一层上游表是2张F表+1张D表,第二层上游表是3张S表,总计有6张上游表。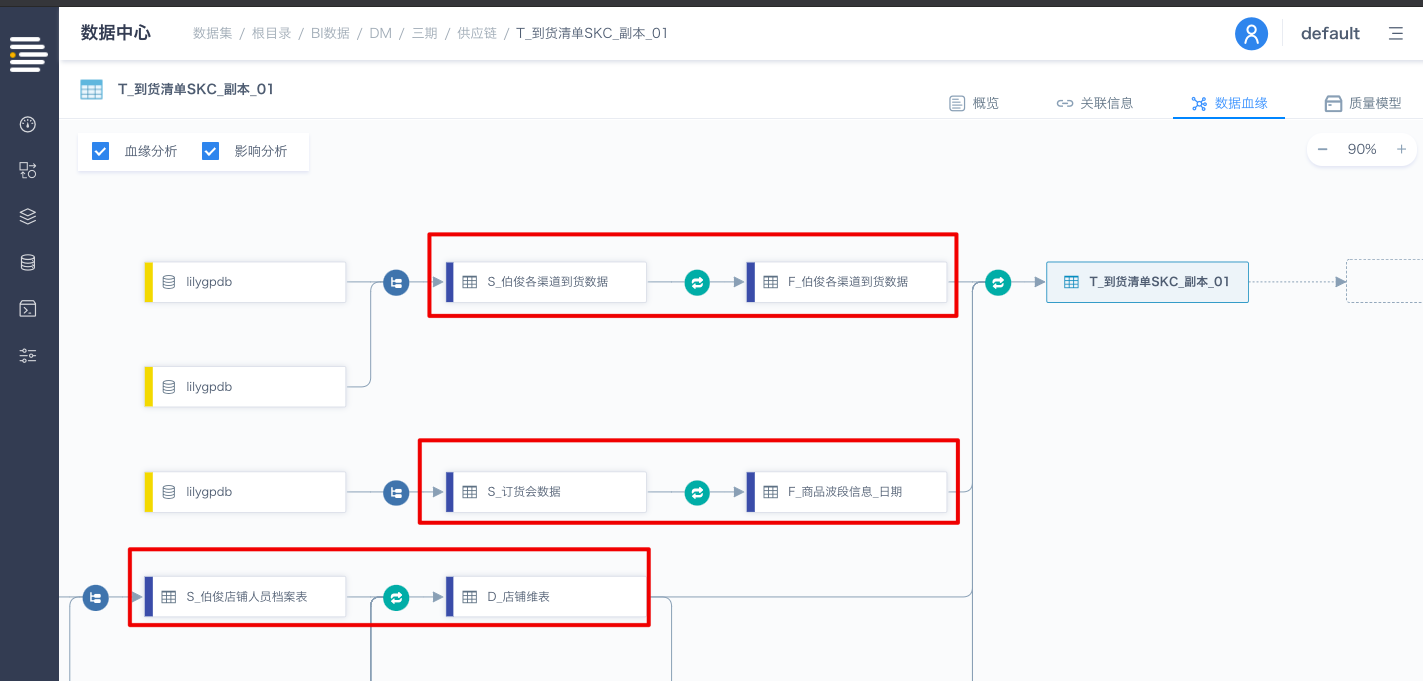
再举例来说,具体到BI平台,表之间第一层上下游关系可以通过数据模型查看,ETL的输入表是输出表的第一层上游表。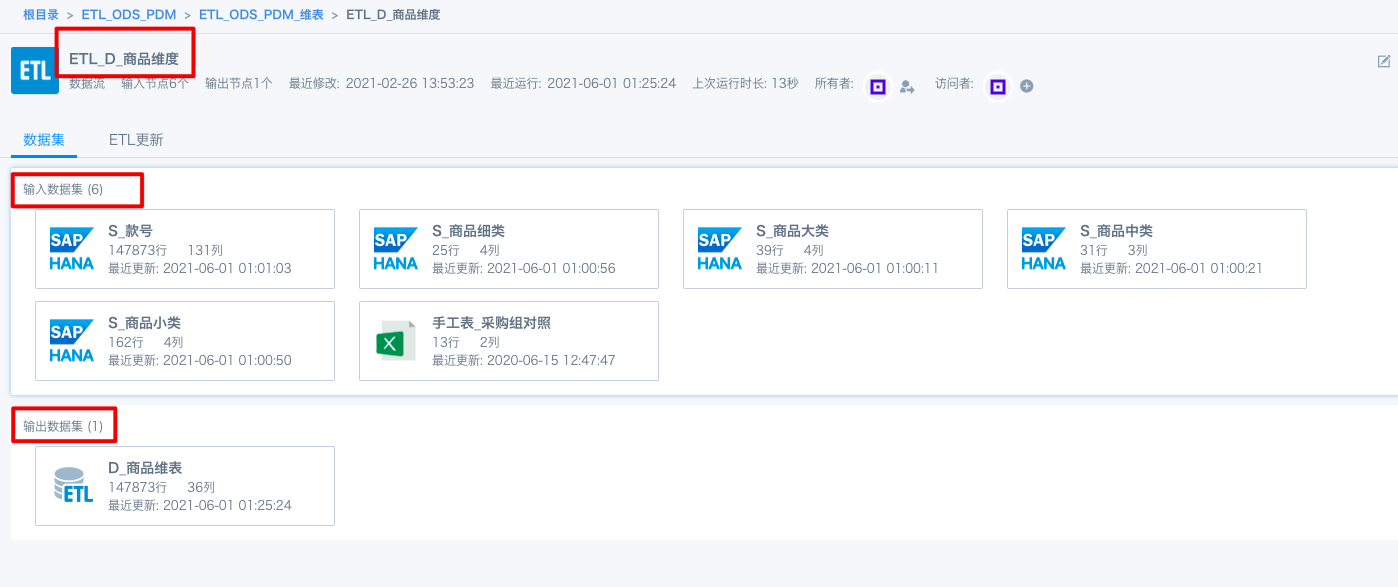
项目背景介绍
BI平台因计算资源受限,要把ETL、数据集等迁移到开发平台,确保两个平台数据都一致之后,BI平台可删除大量ETL,节省计算资源。
但BI平台的表是有数仓层级架构的,如ODS(命名叫S表)->DWD(命名叫F1表)->DWS(命名叫F2表)->ADS(命名叫T表)。数仓架构的存在,导致表之间存在血缘管理。
一般来说,手工表的上游表={},S表的上游表={},F1的上游表={S表},F2的上游表={S表,F1表},T表的上游表={S表,F1表,F2表}。这里出现了“循环嵌套”,即T表的上游表中出现了F1表、F2表,但F1表、F2表又有各自的上游表。
因此,追根溯源,手工表的上游表={},S表的上游表={},F1的上游表={手工表,S表},F2的上游表={手工表,S表},T的上游表={手工表,S表}
可见,要使T表数据在两个平台对得上,必须满足:
- T的上游表={手工表,S表},两个平台都对得上
- 输出T表的ETL逻辑,两个平台都对得上
因此现在要准备一份表之间的血缘关系表,任意选择表X,都能快速知道X所有上游表。
数据准备
已经通过JSON数组解析的方式,得到了两份表(具体实现方式,后面会有一篇新的羽雀文章进行总结,后续会附上文章链接):BI平台中 「ETL与对应输入表」,「ETL与对应输出表」。
希望得到:
表血缘关系明细.xlsx
Python实现代码
此代码可借助开发平台的python算子实现。
import pandas as pddi= load_input1()do= load_input2()tx='迁移ETL清单'ty='数据集名称'D = {}def get_ins(out):D[out] = []etl = list(set(do[do[ty]==out][tx].values))[0]ins = list(set(di[di[tx]==etl][ty].values))for _in in ins:if len(do[do[ty]==_in])==0:D[out].append(_in)else:if _in not in D:get_ins(_in)for x in D[_in]:D[out].append(x)D[out] = list(set(D[out]))for out in do[ty].values:if out not in D:get_ins(out)dr = pd.DataFrame([], columns=['数据集', '上游数据集'])for x in D:for y in D[x]:dr.loc[len(dr.index)] = [x, y]dr=dr.reset_index()save_output1(dr)
备注:该代码还存在一定优化空间,目前运行时长和数据量呈线性关系。如需优化后的代码,可私下联系我。

若有收获,就点个赞吧
0 人点赞
