HashMap常见面试题
- 当key为null时,进行put操作,数据会被放在那个桶位?为什么?
- 数组0的位置
- 为什么HashMap内部的散列表数组长度一定时2的次方数?
- 如果不是2的次方数会出现大量的重复 而且有些位置存放不到数据(散列性差)
- HashMap内部的散列表结构,什么时候初始化?以及初始化大小分别有几种情况?
- 调用put方法的时候初始化, 初始化大小可以根据创建map的时候设置,如果没有设置默认16
- HashMap为什么需要扩容,扩容resize()又是如何实现的?
- 为了map的查询性能,数组长度太小不管优化成什么数据结构重复率也会很高,导致查询变慢。这是牺牲空间提升时间的解决方案
- 扩容值根据加载因子 数组长度到了一定的位置就会进行扩容,每次数组长度<<1,还会根据新的数组长度计算重复位置链表中的哈希值 把哈希值不同的元素放到新的位置。
- JDK8中,HashMap为什么引入红黑树
HashMap()
- 构造一个空的 HashMap ,默认初始容量(16)和默认负载系数(0.75)。
- new的时候还没有初始化在第一次put的时候才会初始化
//HashMap的无参构造方法源码public HashMap() {//默认加载因子0.75this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}
HashMap(int initialCapacity, float loadFactor)
- initialCapacity 设置的数组长度
- loadFactor 设置负载因子
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)//数组长度不能小于0 小于0抛出异常throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)//如果数组长度大于最大长度就把数组长度设置为最大长度initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))//如果加载因子小于等于0或者不是数字抛出异常throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}
HashMap(Map<? extends K,? extends V> m)
- 把传入的map变为Hashmap
public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}
put方法
```java public V put(K key, V value) { //通过hash方法计算出这个数据存放在Node[]中的index位置 return putVal(hash(key), key, value, false, true); } static final int hash(Object key) { int h; //key如果是null那么就把该数据存放到Node[]中的第一个位置 //如果key不为null那么根据二进制算出该数据存放到Node[]中的index //该index不会越界 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
- 把传入的map变为Hashmap
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node
hashMap数据存放图<br />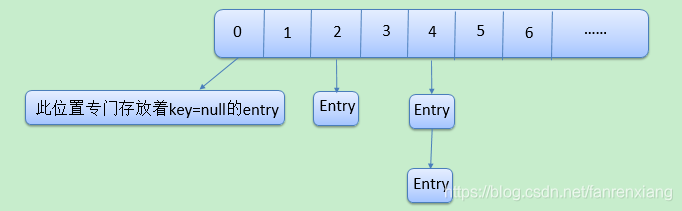<a name="E2pNG"></a>## get方法```java//get源码根据hash值找到index找到该值如果有重复就遍历列表找到对应的key返回value//是红黑树就遍历红黑树找到valuepublic V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}
remove方法
//删除也是一样根据hash找到位置如果是链表就把上一个node的next属性指向被删除元素的next//如果是红黑树就删除该元素然后红黑树会进行平衡public V remove(Object key) {Node<K,V> e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;}
HashMap扩容
- 当Node[]的内容达到initialCapacityloadFactor就会进行扩容比如默认值(160.75=12)当Node[]元素中有12个值了就会进行扩容是当前数组的2倍长度
- 而且还会根据数组长度和元素key的哈希值重新计算重复元素在新的Node[]中的index
//扩容源码final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}

若有收获,就点个赞吧
0 人点赞
