awk更偏向于对文本的格式化处理输出。不仅仅是一款工具,也是一门解释性语言。创建简短的程序来处理自己的需求,如读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等
1、适用场景
- 超大文件处理;
- 输出格式化的文本报表;
- 执行算数运算;
- 执行字符串操作等。
2、awk的处理模式
一般是遍历一个文件中的每一行,然后分别对文件的每一行进行处理。
awk对输入的一行数据进行处理的模式,对整个文件进行重复执行此模式处理,在此说明对输入的一行数据处理的内在机制如下图所示: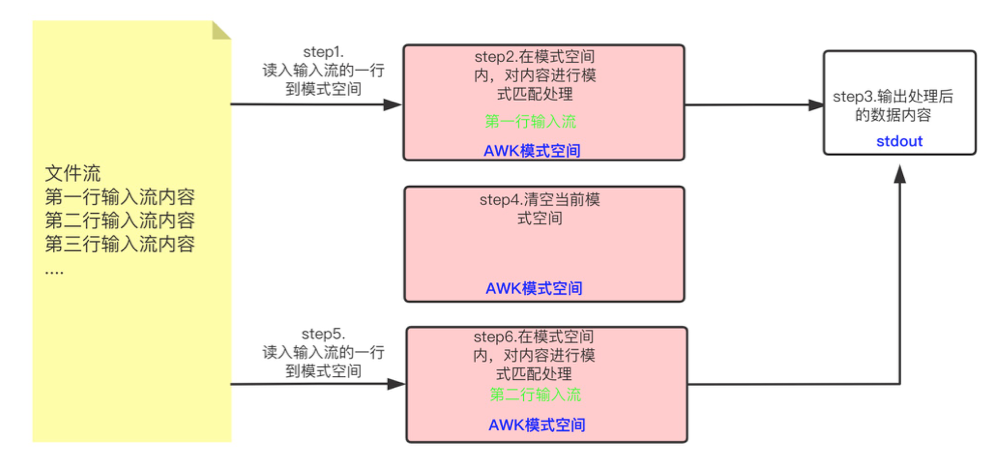
处理过程不断重复,直到到达文件结尾。
- 首先读入文件流的一行到模式空间;
- 在模式空间内,对内容进行模式匹配处理;
- 然后输出处理后的数据内容;
- 清空当前模式空间;
- 读取第二行输入流到模式空间;
- 又开始对模式空间内的第二行输入数据进行处理。
总体可以分为以下三步:
- 读(Read):AWK 从输入流(文件、管道或者标准输入)中读入一行然后将其存入内存中。
- 执行(Execute):对于每一行输入,所有的 AWK 命令按顺序执行。 默认情况下,AWK 命令是针对于每一行输入,但是我们可以将其限制在指定的模式中。
-
3、语法

awk [options] 'PATTERN {action}' file1,file2 # 'PATTERN {action}' 程序结构
4、程序结构
开始块(BEGIN BLOCK):
语法:BEGIN{awk-commands}开始块就是awk程序启动时执行的代码部分(在处理输入流之前执行),并且在整个过程中只执行一次;一般情况下,我们在开始块中初始化一些变量。BEGIN是awk的关键字,因此必须要大写。【注:开始块部分是可选,即你的awk程序可以没有开始块部分】
- 主体块(Body Block):
语法:/pattern/{awk-commands}针对每一个输入的行都会执行一次主体部分的命令,默认情况下,对于输入的每一行,awk都会执行主体部分的命令,但是我们可以使用/pattern/限制其在指定模式下。
- 结束块(END BLOCK):
语法:END{awk-commands}结束块是awk程序结束时执行的代码(在处理完输入流之后执行),END也是awk的关键字,必须大写,与开始块类似,结束块也是可选的。
5、命令详解
awk print输出:
print item1,item2...- 1、各字段之间逗号隔开,输出时以空白字符分隔;
- 2、输出的字段可以为字符串或数值,当前记录的字段(如$1)、变量或 awk 的表达式;数值先会转换成字符串然后输出;
- 3、print 命令后面的 item 可以省略,此时其功能相当于
print $0,如果想输出空白,可以使用print ""; - 4、默认输出分隔符是空格,-F指定分隔符
# 以":"为分隔符格式化文件,print打印输出第一行$1和最后一行$NF,以-t作为输出分隔符[root@VM-0-17-centos ~]# awk -F: '{print $1,$NF}' /etc/passwd | column -troot /bin/bashbin /sbin/nologindaemon /sbin/nologinadm /sbin/nologinlp /sbin/nologinsync /bin/sync
awk printf 输出.
- 其与 print 命令最大区别,printf 需要指定 format,format 必须给出;
- format 用于指定后面的每个 item 输出格式;
- printf 语句不会自动打印换行字符
\n。
format 格式的指示符都以 % 开头,后跟一个字符:
%c:显示ascall码%d:%i:十进制整数%e,%E:科学计数法%f:浮点数%s:字符串%u:无符号整数%%:显示%自身修饰符:#[.#]:第一个#控制显示的宽度:第二个#表示小数点后的精度:%3.1f-:左对齐+:显示数组符号
[root@master ~]# awk -F: '{printf "Username:%-15s ,Uid:%d\n",$1,$3}' /etc/passwdUsername:root ,Uid:0Username:bin ,Uid:1Username:daemon ,Uid:2Username:adm ,Uid:3Username:lp ,Uid:4Username:sync ,Uid:5Username:shutdown ,Uid:6
6、awk变量
- 记录变量:
- IFS(input field separator),输入字段分隔符(默认空白)
- OFS(output field separator),输出字段分隔符
- RS(Record separator):输入文本换行符(默认回车)
- ORS:输出文本换行符
- 数据变量
- NR:the number of input records,awk 命令所处理的文件的行数,如果有多个文件,这个数目会将处理的多个文件计数
- NF:number of field,当前记录的 field 个数
一学就会,一用就废啊。。可咋整!暂时放弃了。

若有收获,就点个赞吧
0 人点赞
