MySQL常见问题:
- 你知道 InnoDB 索引所使用的算法是什么吗?
- 为什么 InnoDB 要使用 B+ 树而不是其他的数据结构呢?
- 在 InnoDB 中,是不是必须要有主键?如果建表的时候不指定主键会怎样?
- InnoDB 的主键和索引有什么区别?
InnoDB存储引擎支持以下几种索引:
- B+树索引
- 全文索引
- 哈希索引
B+树就是常规意义的索引,不是二叉树,而是balance树。B+索引常常被误解的是,通过B+索引只能找到被查找数据所在的数据页。然后在内存中查找对应的数据
计算机存储:
根据其与 CPU 的距离由近到远有以下几个:寄存器、缓存、内存、硬盘。操作系统读取内存和硬盘的时候,基本上以 “页” 为单位进行操作的。
读取页:
应用程序上存取的不是实际内存,而是虚拟内存。而操作系统映射虚拟内存,只能以页为单位进行映射。因此,即便你操作的是内存,还是请自觉尽量对齐页。
硬盘的读写有以下两个特点:
- 慢: 磁盘需要转才能转到对应的位置;SSD 好很多,但也比不上内存,毕竟要从长长的总线加载到内存中呢
块: 在软件中使用的 page,在硬件届经常是可以对应到 block。磁盘和 SSD 的数据修改都是以 block 为单位的
存储系统中的 “页”
InnoDB 引擎的关键特性包括以下内容:
- 插入缓冲(Insert Buffer)
- 两次写(Double Write)
- 自适应哈希索引(Adapitve Hash Index)
- 异步 IO(Async IO)
- 刷新临接页(Flush Neighbor Page)
索引的原理
索引的原理,本质上就是解决快速查找和快速修改的目的。其次则是解决非常纠结的硬盘写入流程,整个过程中还需要各种防止崩溃和宕机——毕竟 MySQL 的数据一致性要求是很高的。
作为 MySQL,经常需要关注的数据结构有以下几个:哈希表、B树、B+树。
哈希表
哈希(hash)算法的时间复杂度为 O(1)。MySQL的Memory引擎在索引中使用了哈希算法。因为其他引擎需要考虑落地硬盘的问题所以没有使用hash算法。哈希表在实际应用中需要考虑表的扩容和缩容的问题。当哈希表需要扩容/缩容的时候,整个表中的所有元素都可能需要重新排列
B树
B树的原理其实相对而言比较简单,它就是一棵树。B树相比起最基本的树结构来说,比较特别的就是树的分裂和合并。主要就是在数据库的内容增加和减少的时候所发生。MongoDB 使用的就是 B树
B树有时候也被称为B-树,但是有些文章中B树指的又不是B-树,而是二叉树(Binary Tree)
B树的特点是:
- 每一个节点可以多路分叉,不是二叉树。查询效率上比起二叉树而言肯定是较弱的。
- 在其每一个节点上都会存储数据
为什么采用 B树,而不是搜索效率更高的红黑树呢?
- 首先,B树每一个节点是有一定长度的,在引擎的设计中,会充分利用这一特性,结合前文所提到的 “页”,将同一个节点放在同一页中,大大提高硬盘的存取效率
其次,首先,红黑树在插入的过程中,经常会出现节点的旋转,旋转次数多了之后,可能导致附近的节点分散分布在硬盘的多个页中。那么在数据落地的时候,就会大大降低效率,并且提高失败的风险
B+树
InnoDB 使用的树结构是B+树
一个B+树的示意结构图如下: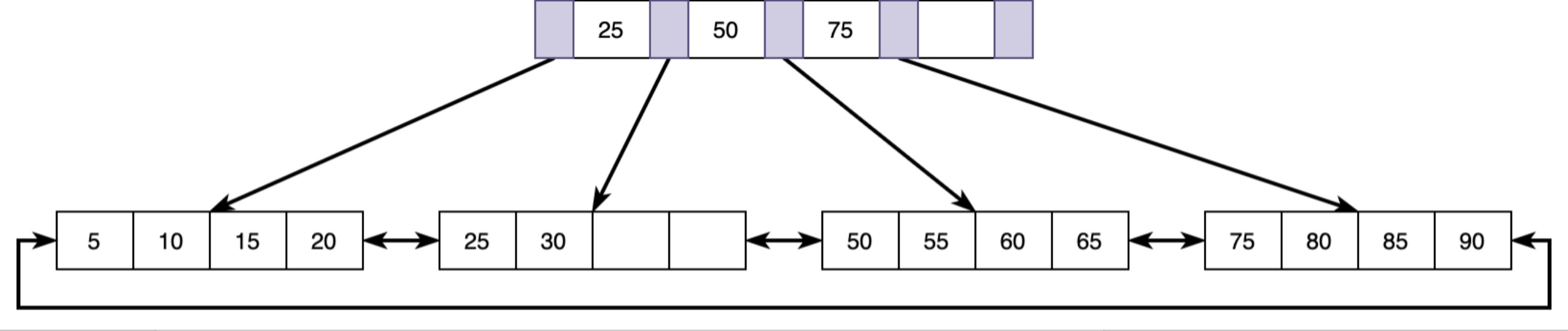
B+树和B树的差异:B树的数据不仅存在叶子结点中,分支节点也存储。但是B+树的数据仅仅存储在叶子结点中,分支节点仅保存索引。如果要查询到数据,那么必须查到叶子结点才能查到。
- B树的各个节点之间除了父子关系之外,不会有其他的关系。但是B+树的叶子节点之间,还有双向链表相互连接。这一点的好处是,对于设计遍历操作,或者是 offset - limit 的操作,能够大大地提高搜索效率
InnoDB 索引的分类
按存储内容区分
Clustered Index:**聚簇索引/聚集索引/聚类索引(聚簇索引指的是在叶子结点上,存储的数据就是完整的 MySQL 的一行数据**)
Secondary Index:**非聚簇索引**/辅助索引/二级索引(在非聚簇索引的叶子结点上,存储的是对应的那一行 MySQL 数据的主键)
对于 MyISAM 引擎来说,主键不是必须的,如果不指定主键,那就没有主键
在 InnoDB 中主键是必要的,如果不指定主键的话,那么 InnoDB 会隐含地添加一个6个字节 24 位宽的整型ID作为主键。但这会导致这个整型 ID 不可见,导致相关的一些操作比如 last inserted id 变得没有意义。因此在实际操作中我们还是需要显式地指定主键。对于 InnoDB 来说,聚簇索引可以等同于就是主键的索引
回表:
如果通过非聚簇索引,也就是除了主键以外的字段查找到了条目之后,此时 InnoDB 仅仅拿到了两个数据:一个是当前节点的索引列的值;另一个是主键。如果客户端还请求了其他数据的话,那么 InnoDB 需要再到当前表的聚簇索引中进行查阅。这个动作称为 “回表” 查询
按组成逻辑区分
- 主键索引: 就是聚簇索引
- 单列索引: 除了主键之外的非聚簇索引的最简单的模式
- 联合索引: 就是多列的索引(当创建一个联合索引时,索引中的每一个字段的值,都会在索引的数据结构中出现)
- 唯一索引: 这是单列索引和联合索引的特例,不同的就是在整个表中仅在符合单列或者多列条件所指定的同一个/一组值的数据行,仅允许存在一条
覆盖索引
覆盖索引指的是引擎不需要回聚集索引去查全部数据,仅仅在索引的二叉树上就可以查出来需要的数据,不需要回表
“覆盖索引” 并不是一种索引的类别,而是一种查询情况。在大部分按照索引进行的查询时,还需要进行回表查询从而得到所需要的其他字段。但是如果你查询的字段,当前的索引已经完全覆盖了,那么这个时候 InnoDB 不会再进行多余的回表查询,而是在非聚簇索引查询中就直接把字段返回了。这个现象就称为 “覆盖索引”(covering index)。空间索引
InnoDB 在 5.7.4 labs 版本中开始支持对空间索引的支持。简单而言,我们平时的索引就是一个纬度的,比如一个数字x。而空间索引则是对一个空间坐标系的索引,比如 (x, y) 或者是 (x, y, z)。
InnoDB 的索引采用 R 树。在大部分的应用场景中,如果不涉及地理数据的话,空间索引我们用得还是比较少的。
索引区分度:
SHOW INDEX FROM matrix_invite_link;
cardinality值需重点关注
公式为var = cardinality/总记录数量,var越接近1,索引的作用越大,越需要建立索引
联合索引的用法
index a,bc
select from t where a = ‘’会使用索引a
select from t where a= ‘’ and b = ‘’ 会使用索引abc
select from t where a= ‘’ and b = ‘’ and c= ‘’ 会使用索引abc
select from t where a= ‘’ order by b 会使用索引abc
select from t where a= ‘’ order by b,c 会使用索引abc
select from t where a= ‘’ order by c 不是使用索引
因为索引abc会把数据按照abc的方式去排序
回答面试题
| 问: | InnoDB 索引所使用的索引和算法是什么? |
|---|---|
| 答: | B+树索引、二分查找法 |
| 问: | 为什么 InnoDB 要使用 B+ 树而不是其他的数据结构呢? |
| 答: | 相比起红黑树,B树的节点以页为单位,而页则与硬盘中的页相互绑定,因此可以优化硬盘存取的效率 |
| 相比起红黑树,B树的深度比较稳定,查找的耗时比较可预期——这个其实是B树的分裂和旋转策略所决定的 | |
| 相比起B树,B+树的叶子结点之间包含双向链表,可以极大地优化遍历类和 offset - limit 类查询的耗时 | |
| InnoDB 在使用 B+树中,使用了非聚簇索引,这一算法可以极大地减少索引所占的空间,从而大大减少索引占用的内存和硬盘空间,提高索引重建效率 | |
| 其实这个答案不唯一 | |
| 问: | 在 InnoDB 中,是不是必须要有主键?如果建表的时候不指定主键会怎样? |
| 答: | 主键是必须有的,如果不指定的话,InnoDB 会自动创建一个6字节的自增ID |
| 问: | InnoDB 的主键和索引有什么区别? |
| 答: | InnoDB 的主键是一种特殊的索引,也就是聚簇索引;而其他的索引都是非聚簇索引。区别就是聚簇索引上保存的是完整的一行数据,而非聚簇索引上保存的是索引值以及主键 |

若有收获,就点个赞吧
0 人点赞
