1. 集群
一个 Kubernetes 集群包含两种类型的资源:
- Master 调度整个集群
- Nodes 负责运行应用
1.1 Master
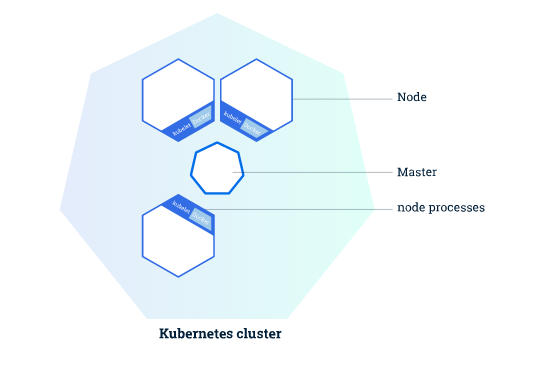
Master 协调集群中的所有活动,例如调度应用、维护应用的所需状态、应用扩容以及推出新的更新。Master组件可以在集群中任何节点上运行。但是为了简单起见,通常在一台VM/机器上启动所有Master组件,并且不会在此VM/机器上运行用户容器。
- kube-apiserver:用于暴露Kubernetes API。任何的资源请求/调用操作都是通过kube-apiserver提供的接口进行
- ETCD:Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计划。
- kube-controller-manager:运行管理控制器,它们是集群中处理常规任务的后台线程。逻辑上,每个控制器是一个单独的进程,但为了降低复杂性,它们都被编译成单个二进制文件,并在单个进程中运行。
- cloud-controller-manager:云控制器管理器负责与底层云提供商的平台交互。
- kube-scheduler:监视新创建没有分配到Node的Pod,为Pod选择一个Node。
- 插件 addons:插件(addon)是实现集群pod和Services功能的 。Pod由Deployments,ReplicationController等进行管理。Namespace 插件对象是在kube-system Namespace中创建。
1.2 Node
Node 是一个虚拟机或者物理机,它在 Kubernetes 集群中充当工作机器的角色 每个Node都有 Kubelet , 它管理 Node 而且是 Node 与 Master 通信的代理。 Node 还应该具有用于处理容器操作的工具,例如 Docker 或 rkt 。处理生产级流量的 Kubernetes 集群至少应具有三个 Node 。Node有如下组成部分:
kubelet:kubelet是主要的节点代理,它会监视已分配给节点的pod,具体功能:
- 安装Pod所需的volume。
- 下载Pod的Secrets。
- Pod中运行的 docker(或experimentally,rkt)容器。
- 定期执行容器健康检查。
- kube-proxy:通过在主机上维护网络规则并执行连接转发来实现Kubernetes服务抽象。
- docker:用于运行容器。
- RKT:运行容器,作为docker工具的替代方案。
- supervisord:是一个轻量级的监控系统,用于保障kubelet和docker运行。
- fluentd:是一个守护进程,可提供cluster-level logging.。
下图是一个一主三从的k8s集群结构:

2. Deployment
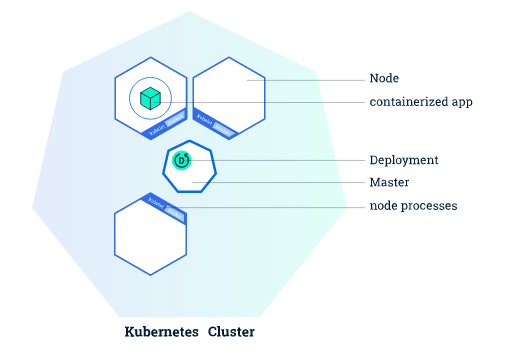
Deployment 指挥 Kubernetes 如何创建和更新应用程序的实例。创建 Deployment 后,Kubernetes master 将应用程序实例调度到集群中的各个节点上。创建应用程序实例后,Kubernetes Deployment 控制器会持续监视这些实例。 如果托管实例的节点关闭或被删除,则 Deployment 控制器会将该实例替换为群集中另一个节点上的实例。 这提供了一种自我修复机制来解决机器故障维护问题。
通过kubectl创建Deployment:
kubectl create deployment kubenetes-bootcamp --image=registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-bootcamp:v1
一般Deployment使用过程如下:
- 使用Deployment来创建ReplicaSet。ReplicaSet在后台创建pod。检查启动状态,看它是成功还是失败。
- 然后,通过更新Deployment的PodTemplateSpec字段来声明Pod的新状态。这会创建一个新的ReplicaSet,Deployment会按照控制的速率将pod从旧的ReplicaSet移动到新的ReplicaSet中。
- 如果当前状态不稳定,回滚到之前的Deployment revision。每次回滚都会更新Deployment的revision。
- 扩容Deployment以满足更高的负载。
- 暂停Deployment来应用PodTemplateSpec的多个修复,然后恢复上线。
- 根据Deployment 的状态判断上线是否hang住了。
- 清除旧的不必要的 ReplicaSet。
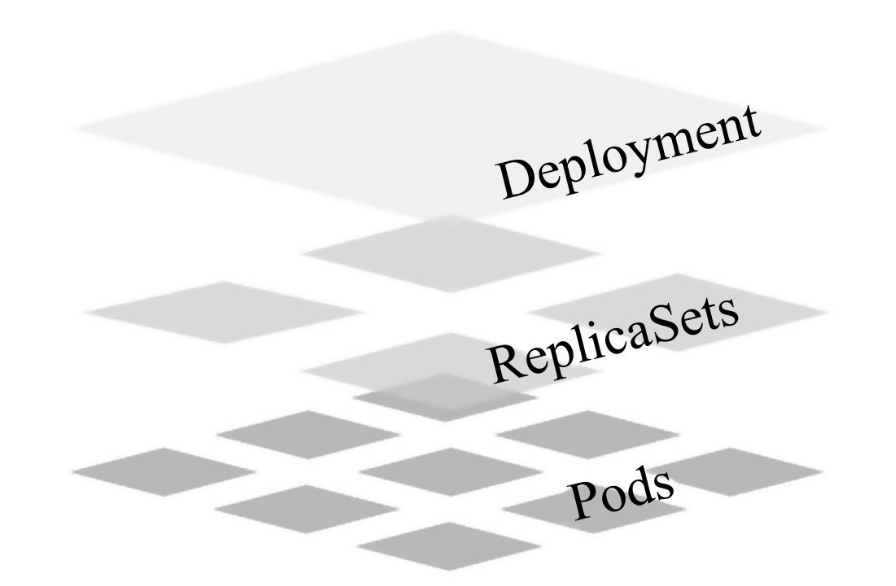
ReplicaSet,Deployment和Pod的关系大题
3. Pod
Pod是Kubernetes创建或部署的最小/最简单的基本单位,一个Pod代表集群上正在运行的一个进程。

一个Pod封装一个应用容器(也可以有多个容器),存储资源、一个独立的网络IP以及管理控制容器运行方式的策略选项。Pod代表部署的一个单位:Kubernetes中单个应用的实例,它可能由单个容器或多个容器共享组成的资源。
每个Pod都是运行应用的单个实例,如果需要水平扩展应用(例如,运行多个实例),则应该使用多个Pods,每个实例一个Pod。在Kubernetes中,这样通常称为Replication。Replication的Pod通常由Controller创建和管理。
4. Replica Sets
ReplicaSet(RS)是Replication Controller(RC)的升级版本。ReplicaSet 和 Replication Controller之间的唯一区别是对选择器的支持。ReplicaSet支持labels user guide中描述的set-based选择器要求, 而Replication Controller仅支持equality-based的选择器要求。
上面也介绍了,RS/RC为介于Deployment和Pods之间的控制器,用于控制Pods的数量为一个期望值。
5. Name 和 Namespaces
有点类似user和group的关系。在查看pods的时候会显示Name 和 Namespaces,见下图

- Name: Kubernetes REST API中的所有对象都用Name和UID来明确地标识。
- Namespace: 当团队或项目中具有许多用户时,可以考虑使用Namespace来区分,a如果是少量用户集群,可以不需要考虑使用Namespace,如果需要它们提供特殊性质时,可以开始使用Namespace。Namespace为名称提供了一个范围。资源的Names在Namespace中具有唯一性。
Namespace的创建、删除和查看:
# 创建kubectl create namespace new-namespace# 删除kubectl delete namespaces new-namespace# 查看kubectl get namespaces
6. Volume
Kubernetes的Volume解决了这两个问题。
- 当容器挂掉kubelet将重启启动它时,文件将会丢失;
- 当Pod中同时运行多个容器,容器之间需要共享文件时。
Kubernetes支持Volume类型有:
- emptyDir:当Pod(不管任何原因)从Node上被删除时,emptyDir也同时会删除,存储的数据也将永久删除。
- hostPath:如果Pod需要使用Node上的文件,可以使用hostPath。
- gcePersistentDisk: Pod删除时,gcePersistentDisk被删除,但Persistent Disk 的内容任然存在。这就意味着gcePersistentDisk能够允许我们提前对数据进行处理,而且这些数据可以在Pod之间“切换”。
- awsElasticBlockStore:挂载AWS上的EBS盘到容器,需要Kubernetes运行在AWS的EC2上。
- nfs:Network File System的缩写,即网络文件系统。Kubernetes中通过简单地配置就可以挂载NFS到Pod中,而NFS中的数据是可以永久保存的,同时NFS支持同时写操作。Pod被删除时,Volume被卸载,内容被保留。
- iscsi:iscsi允许将现有的iscsi磁盘挂载到我们的pod中,和emptyDir不同的是,内容被保留。
- fc (fibre channel):
fc卷允许将现有的光纤通道卷挂载到 Pod 中。 - flocker:是一个开源的容器集群数据卷管理器。它提供各种存储后端支持的数据卷的管理和编排。
- glusterfs:允许将Glusterfs(一个开源网络文件系统)Volume安装到pod中。
- rbd:允许Rados Block Device格式的磁盘挂载到Pod中
- cephfs:可以将已经存在的CephFS Volume挂载到pod中
- gitRepo(已弃用):将git代码下拉到指定的容器路径中。CI/CD
- secret:用于将敏感信息(如密码)传递给pod。可以将secrets存储在Kubernetes API中,使用的时候以文件的形式挂载到pod中,而不用连接api。 secret volume由tmpfs(RAM支持的文件系统)支持。
- persistentVolumeClaim:用来挂载持久化磁盘的。PersistentVolumes是用户在不知道特定云环境的细节的情况下,实现持久化存储(如GCE PersistentDisk或iSCSI卷)的一种方式。
- downwardAPI:通过环境变量的方式告诉容器Pod的信息
- projected:将多个Volume源映射到同一个目录
- azureFileVolume:用于将Microsoft Azure文件卷(SMB 2.1和3.0)挂载到Pod中。
- azureDisk:使用Azure上面的虚拟机来作为Kubernetes集群使用时,那么可以通过AzureDisk这种类型的卷插件来挂载Azure提供的数据磁盘。
- vsphereVolume:配置了vSphere Cloud Provider的Kubernetes可以使用
- Quobyte:在kubernetes中使用Quobyte存储,需要提前部署Quobyte软件
- PortworxVolume:Portworx能把你的服务器容量进行蓄积(pool),将你的服务器或者云实例变成一个聚合的高可用的计算和存储节点。
- ScaleIO:ScaleIO是一种基于软件的存储平台(虚拟SAN),可以使用现有硬件来创建可扩展共享块网络存储的集群。
- StorageOS:是StorageOS向容器提供块存储,可通过文件系统访问。
- local:Local 是Kubernetes集群中每个节点的本地存储(如磁盘,分区或目录),在Kubernetes1.7中kubelet可以支持对kube-reserved和system-reserved指定本地存储资源。
详细内容见官网:https://kubernetes.io/zh/docs/concepts/storage/volumes/
7. Service
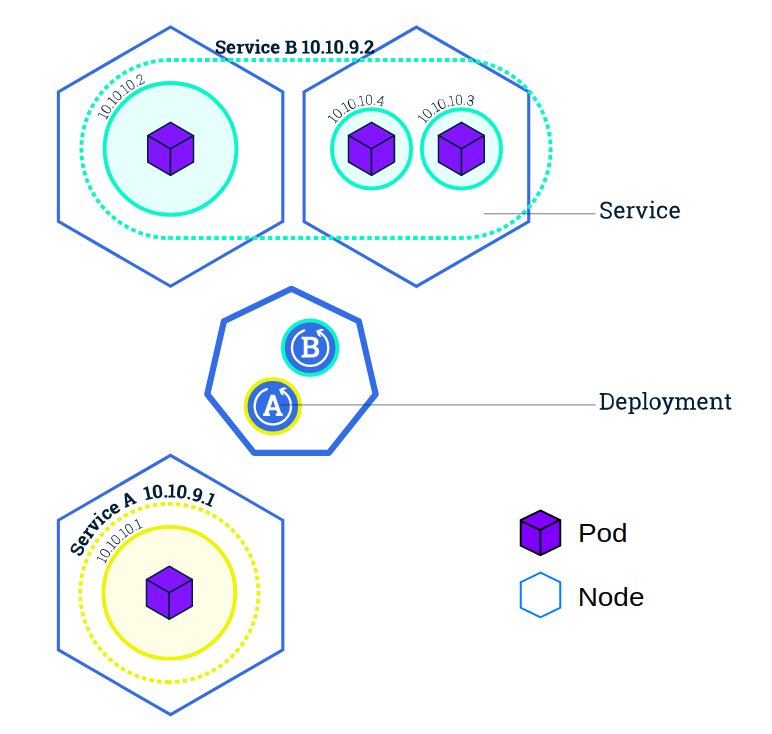
Kubernetes 中的服务(Service)是一种抽象概念,它定义了 Pod 的逻辑集和访问 Pod 的协议。Service 使从属 Pod 之间的松耦合成为可能。 和其他 Kubernetes 对象一样, Service 用 YAML (更推荐) 或者 JSON 来定义. Service 下的一组 Pod 通常由 LabelSelector (请参阅下面的说明为什么您可能想要一个 spec 中不包含selector的服务)来标记。
尽管每个 Pod 都有一个唯一的 IP 地址,但是如果没有 Service ,这些 IP 不会暴露在群集外部。Service 允许您的应用程序接收流量。Service 也可以用在 ServiceSpec 标记type的方式暴露
- ClusterIP (默认) - 在集群的内部 IP 上公开 Service 。这种类型使得 Service 只能从集群内访问。
- NodePort - 使用 NAT 在集群中每个选定 Node 的相同端口上公开 Service 。使用
<NodeIP>:<NodePort>从集群外部访问 Service。是 ClusterIP 的超集。 - LoadBalancer - 在当前云中创建一个外部负载均衡器(如果支持的话),并为 Service 分配一个固定的外部IP。是 NodePort 的超集。
- ExternalName - 通过返回带有该名称的 CNAME 记录,使用任意名称(由 spec 中的
externalName指定)公开 Service。不使用代理。这种类型需要kube-dns的v1.7或更高版本。
8. Labels 和 Selectors
Labels其实就一对 key/value ,被关联到对象上,标签的使用我们倾向于能够标示对象的特殊特点,并且对用户而言是有意义的、说白了就是用来分组打的tag。
Selectors就是通过labels进行来进行选取对应资源。
Service 匹配一组 Pod 是使用 标签(Label)和选择器(Selector), 它们是允许对 Kubernetes 中的对象进行逻辑操作的一种分组原语。标签(Label)是附加在对象上的键/值对,可以以多种方式使用:
- 指定用于开发,测试和生产的对象
- 嵌入版本标签
- 使用 Label 将对象进行分类

9.参考:
https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/expose/expose-intro/
https://kubernetes.io/zh/docs/concepts/storage/volumes/#fc
http://docs.kubernetes.org.cn/703.html
https://blog.csdn.net/ysf465639310/article/details/104794611

若有收获,就点个赞吧
0 人点赞
