1、CPU飙高
1.1 Load Average & CPU使用率
Load(负载)和CPU使用率是衡量进程占用CPU的两个最直观的指标。
1.1.1 负载
在Linux中,Load代表正在CPU上运行和等待运行的进程数,以及可执行态、不可中断睡眠态的进程总数,对应整体操作系统而言,负载是指整体系统的负载,即CPU负载 + Disk负载 + 网络负载 + 其余外设负载。
但实际定位过程中,可以理解为Load负载是进程状态为可执行状态(R)的进程总数。
1.1.2 CPU使用率
CPU时间分片一般分为四类:
- 用户进程运行时间(User Time);
- 系统内核运行时间(System Time);
- 空闲时间(Idle Time);
- 被抢占时间(Steal Time)。
除了Idle Time外,其余时间CPU都处于工作运行状态。
通常而言,我们泛指的整体CPU使用率为User Time 和 System Time占比之和(例如tsar中CPU util),即: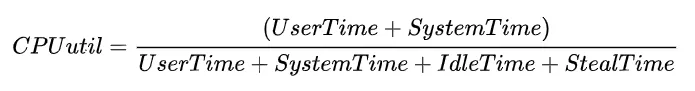
为了便于定位问题,大多数性能统计工具都将这4类时间片进一步细化成了8类,如下为TOP对CPU时间片的分类:
- us:用户进程空间中未改变过优先级的进程占用CPU百分比;
- sy:内核空间占用CPU百分比;
- ni:用户进程空间内改变过优先级的进程占用CPU百分比;
- id:空闲时间百分比;
- wa:空闲&等待I/O的时间百分比;
- hi:硬中断时间百分比;
- si:软中断时间百分比;
- st:虚拟化时被其余VM窃取时间百分比。
1.2 CPU飙高问题排查三板斧
该三板斧尤其针对Java程序导致CPU飙高的情况,目的是找到导致CPU飙高的线程的信息及堆栈情况,再结合代码定位具体问题。三板斧如下:
(1)查看哪个进程占用CPU过高
toptop | grep 用户名
top命令可以查看当前系统中所有进程的CPU、内存信息,展示的结果是动态刷新的,进程越靠上说明进程占用的CPU越高。通过该命令找到占用CPU最高的进程。如下图所示,可以发现进程号为28284的进程占用CPU最高。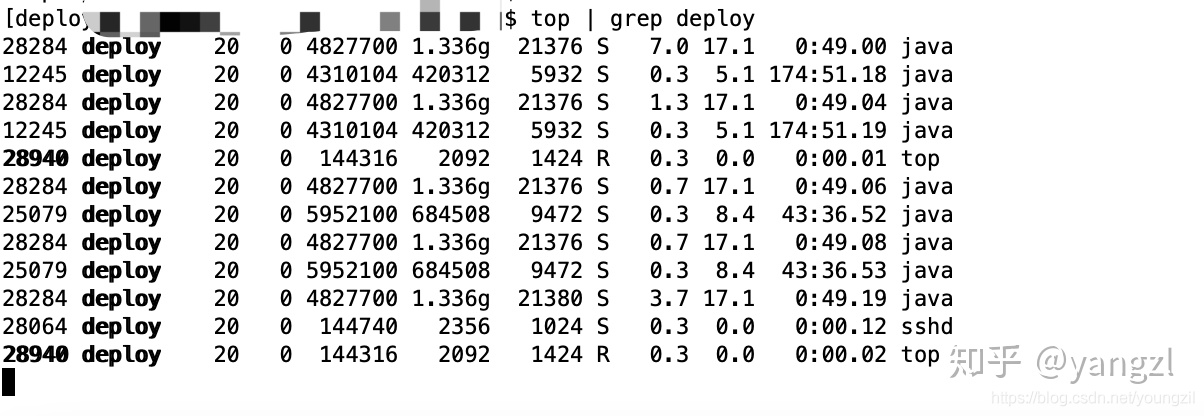
(2)查看哪个线程占用CPU过高
top -hp 进程PID
进程PID是第一步top命令查询得到的CPU占比最高的进程PID。top -hp命令可以查询当前进程中CPU占比最高的线程,注意打印到控制台的PID是线程号,如下图所示,线程ID为28323的线程占用CPU最高(虽然只有0.3%,但是是那个意思):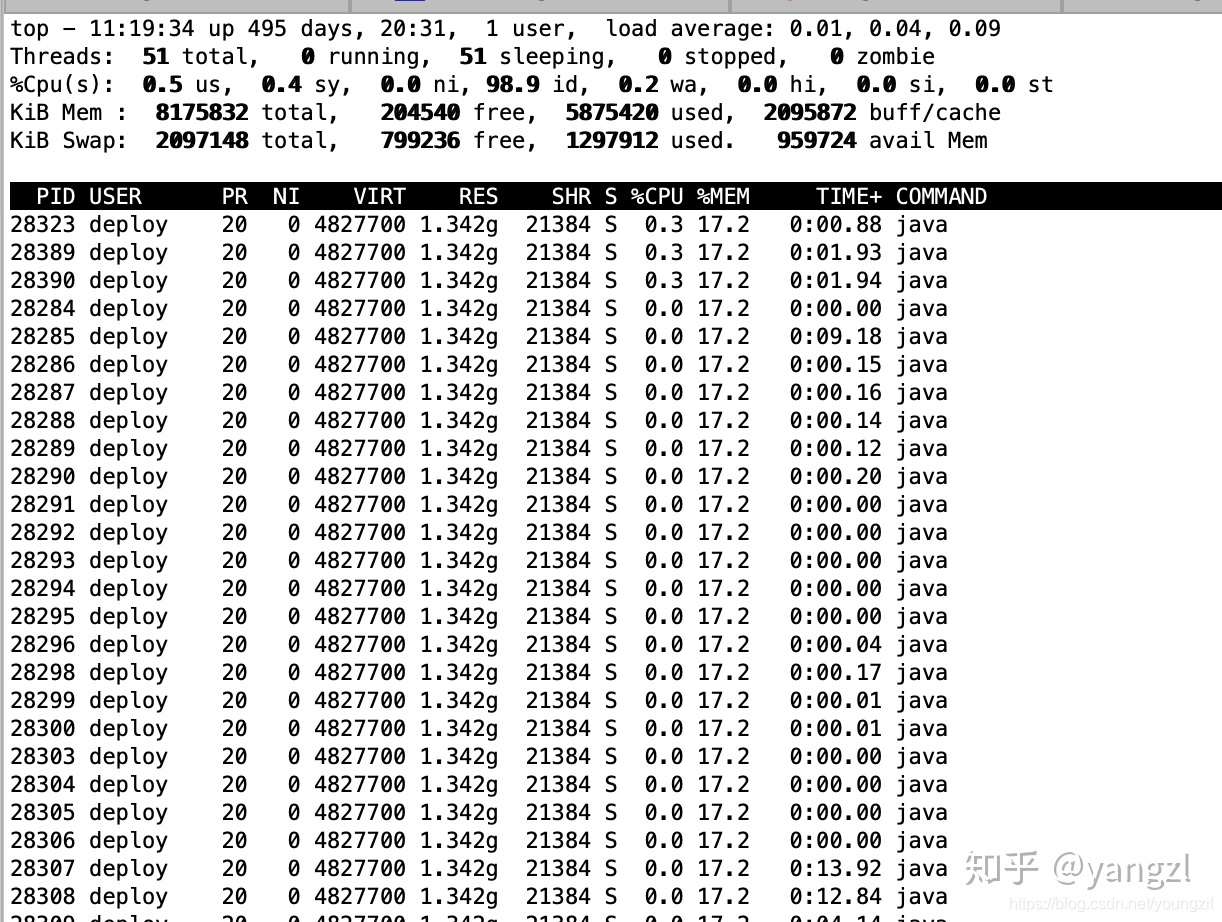
(3)查询线程堆栈信息
# 将第二步查询得到线程ID转换成16进制printf “%x\n” tid# jstack工具查询线程信息jstack 进程ID | grep 16进制的线程ID

jstack工具打印问题线程的堆栈信息,可以看到这个线程执行了哪些逻辑导致了CPU飙高,需要结合代码定位。
1.3 Arthas工具定位
Arthas工具是阿里巴巴开源的Java进程诊断工具,可以参考我这篇文章:https://www.yuque.com/docs/share/d8be3140-ed8d-4adb-a446-8e8d87233f63?# 《Arthas使用》
(1)top命令查看当前哪个进程占用CPU比较高
top
(2)启动Arthas工具,选择问题进程,查看仪表盘
dashboard
(3)查看CPU使用率top 3的线程的堆栈信息
# 查看当前进程中所有线程信息thread# 查看当前CPU使用率top 3的线程信息thread -n 3# 查看指定线程的信息thread tid
(4)确定方法后还可以跟踪指定方法的出参、返回值、异常信息、调用时间、调用路径等
monitorwatchtracestack
1.4 根据CPU时间片具体分析
top、vmstat命令可以展示每个进程具体占用CPU时间片的情况,即1.1中介绍的两个指标,我们可以根据这两个指标排查一些问题。
1.4.1 Load和CPU使用率都高
这是我们最常遇到的情况,根据CPU具体资源分配表现,可分为以下三类。
(1)CPU sys高
对应vmstat命令展示的CPU部分的sy指标。这种情况CPU主要开销在于系统内核,可进一步查看上下文切换情况。
- 如果非自愿上下文切换较多,说明CPU抢占较为激烈,大量进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换;
- 如果自愿上下文切换较多,说明可能存在I/O、内存等系统资源瓶颈,大量进程无法获取所需资源,导致的上下文切换。
(2)CPU si高
对应top命令第一行中的si。这种情况CPU大量消耗在软中断,可进一步查看软中断类型。一般而言,网络I/O或者线程调度引起软中断最为常见:
- NET_TX & NET_RX:NET_TX是发送网络数据包的软中断,NET_RX是接收网络数据包的软中断,这两种类型的软中断较高时,系统存在网络I/O瓶颈可能性较大;
- SCHED:SCHED为进程调度以及负载均衡引起的中断,这种中断出现较多时,系统存在较多进程切换,一般与非自愿上下文切换高同时出现,可能存在CPU瓶颈。
(3)CPU us高
对应vmstat命令展示的CPU部分的us指标。这种情况说明资源主要消耗在应用进程,可能引发的原因有以下几类:
- 死循环或代码中存在CPU密集计算。这种情况多核CPU us会同时上涨;
- 内存问题,导致大量FULLGC,阻塞线程。这种情况一般只有一核CPU us上涨;
资源等待造成线程池满,连带引发CPU上涨。这种情况下,线程池满等异常会同时出现。
1.4.2 Load高 & CPU使用率低
这种情况出现的根本原因在于不可中断睡眠态(TASK_UNINTERRUPTIBLE)进程数较多,即CPU负载不高,但I/O负载较高。可进一步定位是磁盘I/O还是网络I/O导致。
1.5 实战
2、OOM && 频繁 FullGC
这类问题一般有以下直观现象表现:
系统运行缓慢,RT变长;
- 有些进程CPU占用率很高;
- 有些进程的日志里出现OOM,gc情况fullGc频繁
2.1 排查思路
一般对整个服务系统会有监控告警系统,运维人员可以通过监控告警系统告知开发人员是哪一台服务器的哪个服务出现问题,因此后续的排查思路是建立在提前已经知道是哪个Java进程出了问题。
(1)确认环境上进程是否还存在
检查进程是否还存在,如果进程存在,还可以通过该命令获取进程启动时的JVM参数,观察跟堆内存相关的-Xms -Xmx参数设置的是否过小。ps -ef | grep 服务名
(2)服务健康检查
一般服务都会提供一个健康检查接口,外部调用该接口来确认服务是否还正常。
举例: ```bash服务正常返回结果
curl http://192.168.1.110:20606/serviceCheck {“appName”:”test-app”,”status”:”UP”}
服务异常,服务挂掉
curl http://192.168.1.110:20606/serviceCheck curl: (7) couldn’t connect to host
**(3)查看服务日志**```bashtail -f ***.log
实时跟踪日志打印情况:
- 看日志是否还在打印;
- 看是否还有请求进来;
- 看日志里是否有OOM的相关日志打印。
(4)获取CPU占用率高的线程的堆栈信息
# top命令获取CPU占用率高的Java进程id
top
# 获取该进程CPU占用率高的线程id
top -hp |grep Java进程PID
# 将第二步查询得到线程ID转换成16进制
printf “%x\n” tid
# jstack工具查询线程信息
jstack 进程ID | grep 16进制的线程ID
如果是CPU占用率高的top线程是在做gc操作,线程堆栈信息举例如下:
$ cat 11441_jstack.txt | grep "GC task thread"
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007f971401e000 nid=0x2cb4 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007f9714020000 nid=0x2cb5 runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007f9714022000 nid=0x2cb6 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007f9714023800 nid=0x2cb7 runnable
或者:
"main" #1 prio=5 os_prio=0 tid=0x00007f8718009800 nid=0xb runnable [0x00007f871fe41000]
java.lang.Thread.State: RUNNABLE
at com.aibaobei.chapter2.eg2.UserDemo.main(UserDemo.java:9)
"VM Thread" os_prio=0 tid=0x00007f871806e000 nid=0xa runnable
这里的 VM Thread 一行的最后显示 nid=0xa,这里 nid 的意思就是操作系统线程 id 的意思,而 VM Thread 指的就是垃圾回收的线程。
(5)查看服务gc情况
jstat -gc Java进程PID
jstat -gcutil Java进程PID
着重观察FGC的值,看是否过高。
(6)获取堆快照文件
如果JVM启动参数里有-XX:+HeapDumpOnOutOfMemoryError参数和-XX:HeapDumpPath参数,可以去-XX:HeapDumpPath参数指定的路径下获取堆快照的.hprof文件;如果没有这两个参数,需要手动获取当前JVM的堆快照文件,用jmap工具,命令如下:
jmap -dump:[live],format=b,file=<file-path> <pid>
jmap工具使用参考我这篇文章:https://www.yuque.com/docs/share/a58fa76d-d64f-4474-ab8b-d1614a212c97?# 《JDK工具包》
(7)MAT工具分析快照
生成的.hprof二进制文件并不能直接分析定位原因,需要借助专业的堆快照分析工具:Memory Analysis Tools(MAT),通过MAT工具的shell脚本对.hprof文件生产zip报告,命令如下:
./ParseHeapDump.sh java_pid14441.hprof org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
重点关注Leak_Suspects.zip,将文件下载到本地,用浏览器打开html文件,通过观察饼图和stacktrace可以定位到OOM的类以及具体代码处。
注意:由于.hprof文件一般会很大,需要找一个空闲内存较多的服务器执行ParseHeapDump.sh生成zip分析报告,且MemoryAnalyzer.ini里的-Xmx要比.hprof文件的大小 + 1G。
MAT工具使用参考我这篇文章:https://www.yuque.com/docs/share/43bf410f-1ef3-4bfb-b492-bec29e6b5e54?# 《MAT工具分析堆内存快照》
2.2 实战
参考博客:
体验了一把线上CPU100%及应用OOM的排查和解决过程
【干货】java项目内存溢出(OOM)的排查方法及原因分析—源自一次真实线上事故
一次频繁Full GC问题排查过程分享
3、网络IO
4、磁盘IO
参考
CPU飚高问题排查
CPU飚高,系统性能问题如何排查
CPU的工作原理是什么
并发编程大扫盲:带你了解何为线程上下文切换
你要偷偷学会排查线上CPU飙高的问题,然后惊艳所有人
【干货】java项目内存溢出(OOM)的排查方法及原因分析—源自一次真实线上事故
体验了一把线上CPU100%及应用OOM的排查和解决过程
jstat命令查看jvm的GC情况(以Linux为例)
一次频繁Full GC问题排查过程分享
一次性搞清楚线上CPU100%,频繁FullGC排查思路

若有收获,就点个赞吧
0 人点赞
