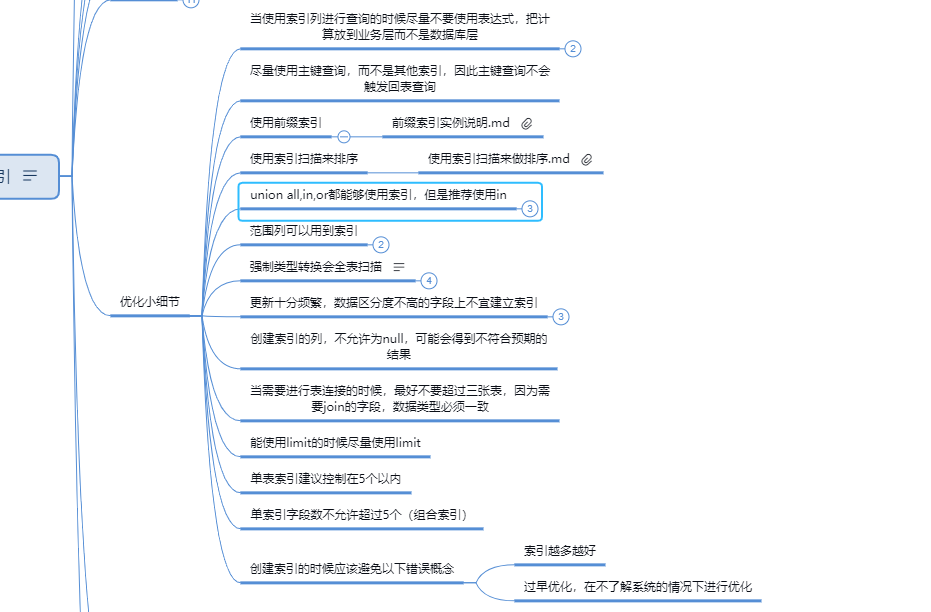
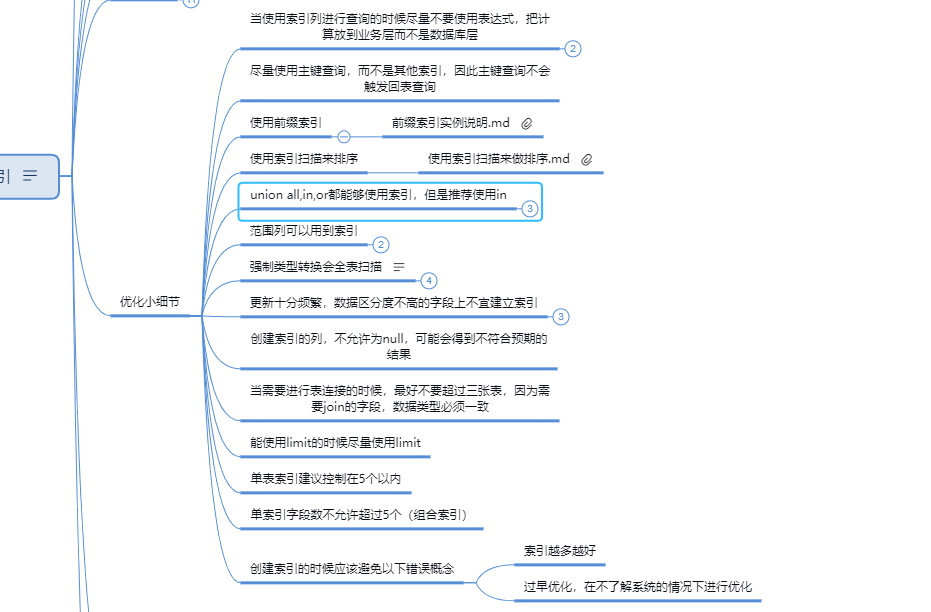
MySQL的InnoDB引擎关于索引和列的一些限制
1. 聚簇/非聚簇索引
2. 主键索引
3. 唯一索引
4. 普通索引
5. 联合索引
6. Hash索引

7. 排序
无论如何排序都是一个成本很高的操作,所以从性能的角度出发,应该尽可能避免排序或者尽可能避免对大量数据进行排序。
推荐使用利用索引进行排序,但是当不能使用索引的时候,mysql就需要自己进行排序,如果数据量小则再内存中进行,如果数据量大就需要使用磁盘,mysql中称之为filesort。
如果需要排序的数据量小于排序缓冲区(show variables like ‘%sort_buffer_size%’;),mysql使用内存进行快速排序操作,如果内存不够排序,那么mysql就会先将树分块,对每个独立的块使用快速排序进行排序,并将各个块的排序结果存放再磁盘上,然后将各个排好序的块进行合并,最后返回排序结果
两次传输
- 第一次数据读取是将需要排序的字段读取出来,然后进行排序,第二次是将排好序的结果按照需要去读取数据行。
- 这种方式效率比较低,原因是第二次读取数据的时候因为已经排好序,需要去读取所有记录而此时更多的是随机IO,读取数据成本会比较高
- 两次传输的优势,在排序的时候存储尽可能少的数据,让排序缓冲区可以尽可能多的容纳行数来进行排序操作
单次传输
- 先读取查询所需要的所有列,然后再根据给定列进行排序,最后直接返回排序结果,此方式只需要一次顺序IO读取所有的数据,而无须任何的随机IO,问题在于查询的列特别多的时候,会占用大量的存储空间,无法存储大量的数据
当需要排序的列的总大小超过max_length_for_sort_data定义的字节,mysql会选择双次排序,反之使用单次排序,当然,用户可以设置此参数的值来选择排序的方式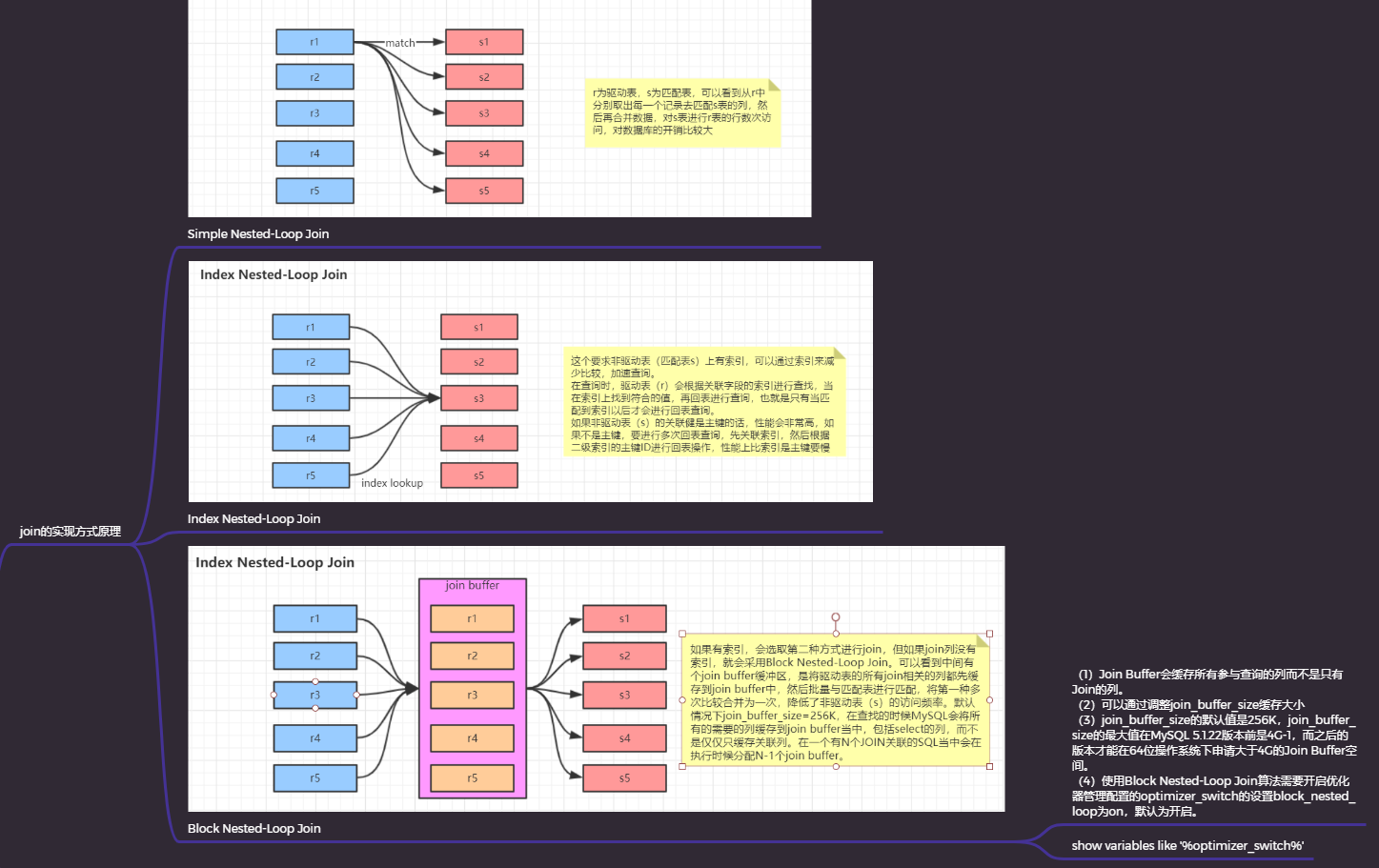

若有收获,就点个赞吧
0 人点赞
