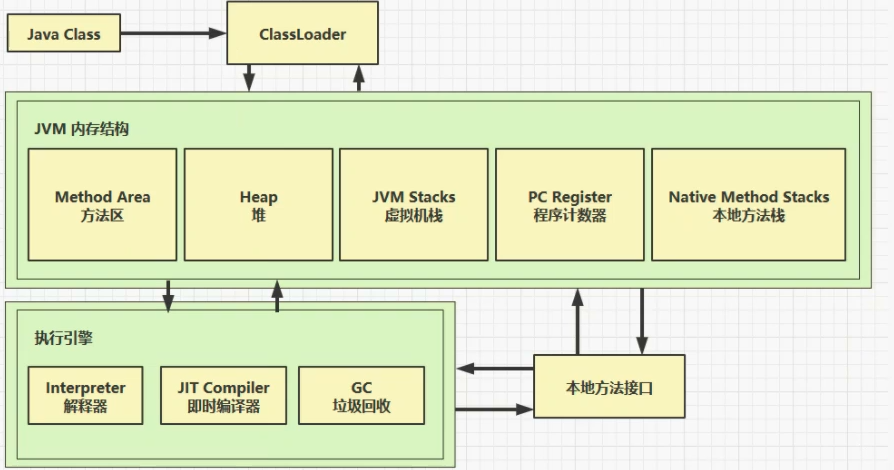
谈谈你对JVM的理解
- Java虚拟机是一台执行Java字节码的虚拟计算机,它拥有独立的运行机制,其运行的Java字节码可以由多种语言编译而成。
- Java虚拟机就是二进制字节码的运行环境,负责装载字节码到其内部,解释/编译为对应平台上的机器指令执行。
JVM是运行在操作系统之上的,它与硬件没有直接的交互
JVM概念图
程序计数器
程序计数器的作用是什么
- 任何时间一个线程都只有一个方法在执行,而PC用于记录JVM中下一条所要执行的JAVA方法的指令地址
- CPU会为每个线程分配时间片,当前线程的时间片使用完以后,CPU就会去执行另一个线程中的代码。而程序计数器是每个线程所私有的,当另一个线程的时间片用完,又返回来执行当前线程的代码时,通过程序计数器可以知道应该执行哪一句指令
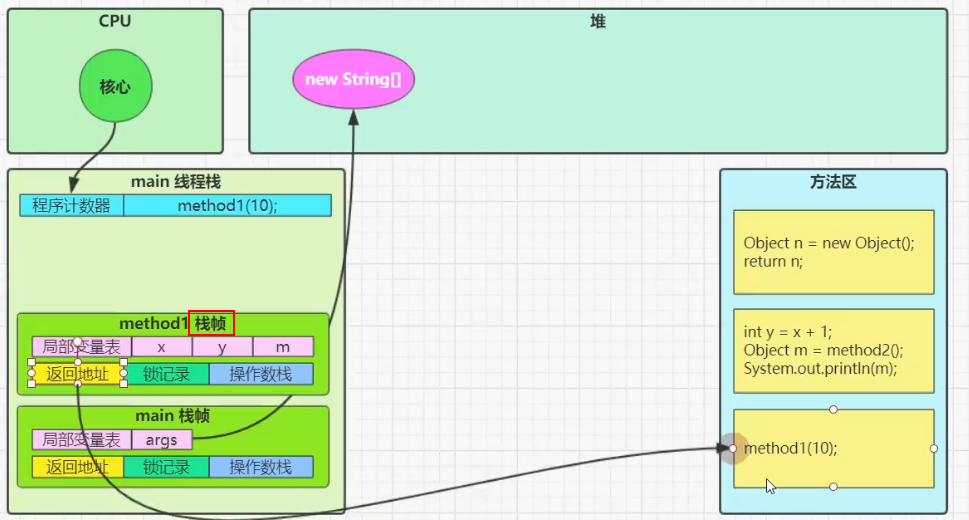
虚拟机栈
定义
- 每个线程运行,jvm都会为其分配内存空间,称为虚拟机栈
- 每个栈由多个栈帧组成(栈帧里面包含各种参数、局部变量、返回地址),每个栈帧对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的方法(也是栈顶部的栈帧)
栈只有进栈入栈的功能,并不会发生GC
栈中可能发生的异常?
- stackoverflow:如果采用固定大小的虚拟机栈,那每一个线程可以在创建时指定所分配的栈大小,当线程请求内存过大时,报stackoverflow错误
- OutofMemoryError:如果采用动态分配栈大小的模式,在尝试扩展但无法申请足够内存时,或者创建新的线程没有足够内存去创建对应虚拟机栈时,报OutofMemoryError错误
本地方法栈
本地方法就是Java调用非Java代码的API,因为JAVA有时候没法直接和操作系统底层交互,所以需要用到本地方法(线程私有)。
本地方法栈管理着本地方法的调用,在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一
堆
通过new关键字创建的对象都会被放在堆内存
所有线程都共享堆,堆内存中的对象都需要考虑线程安全问题
有垃圾回收机制(Minor GC、Major GC、Full GC)
堆里面的内存并不是都共享的,还有TLAB(线程私有的缓存区),用于提高线程同步的并发性。
堆的内存分布?
在 JDK 7 版本及 JDK 7 版本之前,堆内存被通常分为下面三部分:
- 新生代(Young Generation):又可分为Eden+Survivor空间
- 老生代(Old Generation)
- 永久代(Permanent Generation)
而JDK8 以后,永久代变成了元空间(在方法区里面)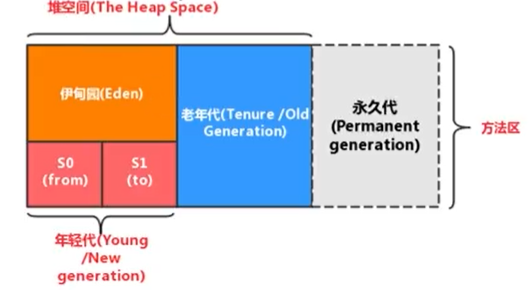
- 几乎所有的对象都是在Eden区被new出来的(如果对象过大,可能直接进入老年代)
- 从Eden->Survivor->老年代:都是发生GC的过程
Java对象都是在堆上分配吗
- 不一定,未逃逸出当前函数的指针指向的对象可以在栈上分配
- 但是HotSpot虚拟机目前说这个逃逸分析算法还不成熟,因此都是在堆上分配
方法区
方法区是一个概念,永久代和元空间都是其实现。
1.6JDK
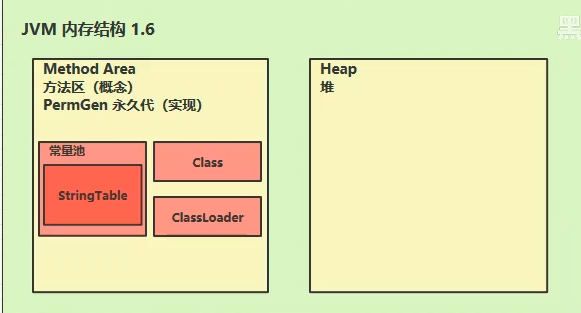
- 静态变量、字符串常量池都在永久代中
1.7JDK
- 将静态变量、字符串常量池存放在堆中
1.8JDK

- 字符串常量池在堆中
- 方法区也是线程共享的,其存储着类相关信息(类型信息、静态变量、运行时常量池等)
- JDK1.8,元空间已经不占用堆内存了(不由JVM管理),而是移出到本地内存当中(操作系统内存,且默认没有设置上限内存)
永久代为什么要被元空间代替?
- 对永久代调优困难(full GC很浪费时间)
- 永久代的空间大小难设置(导致动态加载类时,容易产生OOM)
什么是运行时常量池
- 常量池:常量池是_._class文件中的,可以看作一张表(由二进制字节码组成),虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量信息
- 运行时常量池:当该类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
StringTable
- StringTable在堆中
我们来讨论以下代码的执行周期:
字符串定义
public class StringTableStudy {public static void main(String[] args) {String a = "a";String b = "b";String ab = "ab";}}
- 当程序运行时,开始加载运行时常量池,此时,a、b、ab这些都只是常量池中的符号,并不是java的String对象
- 当程序执行到String a = “a”; 时,才会把该符号变成“a”字符串对象,这种行为是懒惰的
- 将字符串对象加载到StringTable中(也叫串池)
- 以上机制,可以避免重复创建字符串对象
字符串变量拼接
我们来讨论字符串变量拼接创建字符串的执行周期
public class StringTableStudy {public static void main(String[] args) {String a = "a";String b = "b";String ab = "ab";//拼接字符串对象来创建新的字符串String c = a+b;}}
- 通过拼接的方式(+号)来创建字符串的过程是使用StringBuilder方法来做的,其过程就是StringBuilder().append(“a”).append(“b”).toString()
- 而StringBuilder的toString方法就是 new 一个String对象(会在堆生成)
- 因此,当我们判断 c == ab 时,其实是不等的,因为一个在堆内存中,另一个在串池中
字符串常量拼接
public class StringTableStudy {public static void main(String[] args) {String ab = "ab";String d = "a" + "b";}}
- 使用拼接字符串常量的方法来创建新的字符串时,因为内容是常量,javac在编译期会进行优化,结果已在编译期就确定结果为”ab”
- 此时,如果串池中存在”ab”,则直接返回
intern方法
public class Main {public static void main(String[] args) {String str = new String("a") + new String("b");//执行完后:StringTable={"a","b"} ,str则是以“ab”的形式存在于堆内存之中System.out.println(str == “ab”); // 串池中并没有“ab”,返回false// 调用intern方法,将“ab”放入串池String str2 = str.intern();System.out.println(str2 == “ab”); // 返回true}}
字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 这时串池中没有”ab”,则会放入到串池中;如果有,则不放入
- 无论放入是否成功,都会返回串池中的字符串对象
intern在JDK6、7版本中的区别?

StringTable调优
- 因为StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少字符串放入串池所需要的时间
- 考虑是否需要将字符串对象入池:可以通过intern方法减少重复入池
StringTable为什么要调整到堆中?
- 因为永久代的回收效率很低(当触发Full GC才会,而Full GC是当老年代、永久代空间不足才触发),但是实际开发中会有大量字符串被创建、需要回收,于是移动到堆中
为什么需要Java直接内存,它是什么?
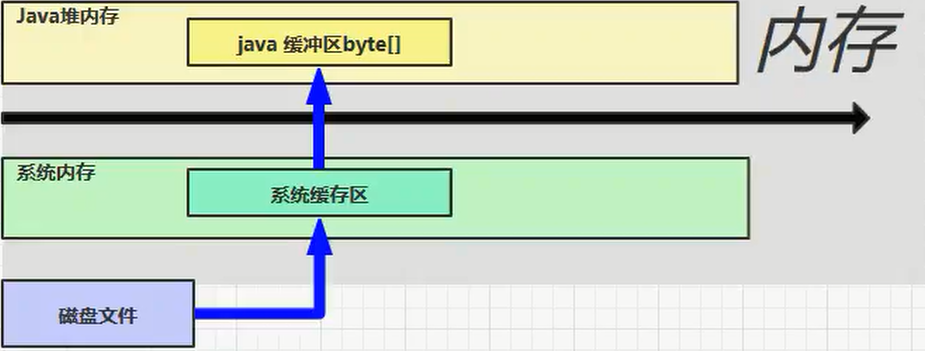
- 在进行IO读写的时候,避免了 Java 堆和 Native 堆(native heap)中来回复制数据,浪费空间
- DirectByteBuffer 直接在堆内储存有对其的引用,不需要复制就能访问

若有收获,就点个赞吧
0 人点赞
