有时候,我们查看数据时,数据太多冗杂,也能难找到我们想要的东西
管道符虽然是个东西,但限于其能力,我们还需要另一种可以精准找出我们想要内容的工具
场景模拟一:在服务器日志中,找出“下标越界”的error,以及特定的warning
场景模拟二:找出简历中的应聘者的电子邮箱或联系方式
等等…
正则表达式
因为之前学过python爬虫,所以也了解过一点正则。
在我看来,正则表达式就是用一些符号编写出我们想要的“匹配模式”
从而找到我们想要的数据。
.除空格之外的”任意单个字符”*匹配前面字符零次或多次+匹配前面字符一次或多次[abc]匹配a,b和c中的任意一个(RX1|RX2)任何能够匹配RX1或RX2的结果

贪婪匹配
这里我使用python来写一个mode: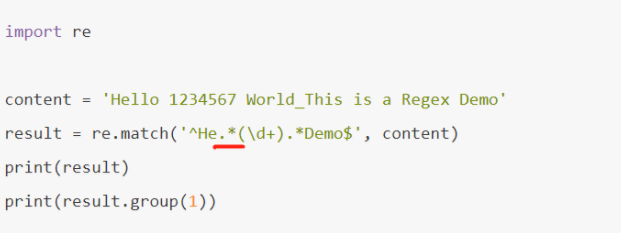
首先,我们想获取中间的数字,所以中间我们写的是 (\d+)
然后两侧我们想省略来写,都写 .*(随意的匹配掉不想要的内容)
结果:
但是!
奇怪的事情发生了,我们只得到了 7 这个数字,这是怎么回事?
这里就涉及一个贪婪匹配与非贪婪匹配的原因了,贪婪匹配下,.* 会匹配尽可能多的字符,我们的正则表达式中 . 后面是 \d+,也就是至少一个数字,并没有指定具体多少个数字,所以 . 就尽可能匹配多的字符,所以它把 123456 也匹配了,给 \d+ 留下一个可满足条件的数字 7,所以 \d+ 得到的内容就只有数字 7 了。
这时候我们只要在第一个 .* 改成 .*? 即可。
得到了我们想要的结果:
awk文本处理<br />
awk 其实是一种编程语言,它非常善于处理文本。
搭配正则表达式
模式类型可以为正则表达式,正则表达式的规则需要写在//中
实例:
查询当前目录下包含se或者sh的记录:
ll ~ | awk '/s[eh]/{print $0}'
编程格式

一个awk脚本通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块3部分组成
第一步:执行BEGIN{ }语句块中的语句;
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ }语句块
第三步:执行END{ }语句块。
后记
总的来说,这一篇文章介绍的知识有些杂,主要是学习他处理数据的思想吧。

若有收获,就点个赞吧
0 人点赞
