两大利器—grep和tail
管道?
| 管道的作用就是将左边命令的输出变成右边命令的输入
grep
命令格式
grep [参数] “关键字” [文件]
常用参数
-E : 扩展的正则表达式
-A: 显示匹配到的字符串所在的行及其后n行
-B: 显示匹配到的所在的行及其前n行
-C: 显示匹配到的字符串所在的行及其前后各n行
-n: 显示行号
-o: 只显示匹配PATTERN 部分
-w: 只显示全字符合的列
-c: 计算符合的列数
-l: 列出文件内容符合指定的文件名称
-v: 显示不包含匹配文本的所有行
-d: 指定查找某个目录
常用匹配多个关键字
grep ‘test1’ | grep ‘test2’
tail
命令格式
tail [参数][文件]
参数
-f 循环读取
-n 显示文件的尾部n行内容
示例1
此命令显示info.log文件的最后10行,如果info.log文件有新内容进来,tail命令会继续显示,直到按下CTRL+C停止
tail -f info.log
示例2
显示info.log文件的所匹配到的关键字”zaygee小号”所在行及其后20行
grep zaygee小号 info.log -A 20
实例3:grep+tail
显示info.log文件所匹配到的关键字”员工”and “zaygee”及尾部后3行
tail info.log -n 3 | grep 员工 | grep zaygee
示例4
显示info.log文件所匹配到的关键字”员工”或者”zaygee”
grep -E '员工|zaygee' info.log
示例5
# 正则匹配cost_time=4位数 且 2022-06-02 19:33 的数据more square-server.log* | grep -iE "cost_time=[0-9]{4}" | grep "2022-06-02 19:33:*" --color
grep 逻辑匹配
and
grep cat.log | grep “test” | grep “zaygee “
or
grep cat.log | grep -E “test|zaygee”
排序、筛选sort、uniq
sort
将文本文件内容进行排序
uniq
用于检查文件中重复出现的行列
参数
-c:在每列旁边显示该行重复的次数
-d:仅显示重复出现的行列
应用
一般sort和uniq会结合使用,例如查找某个字符串出现的次数
# 方式一grep -o 'xx' info.log | sort |uniq -c#方式二grep -o 'xx' info.log | wc -l
文本分析awk
常用语法
awk -F ‘(command)’
参数
-F:指定分隔符
-f:调用脚本
应用
cat request.log | awk -F '(RequestLog|&结果)' '{print $2}'
awk命令中 -F指定每行的分隔符;
‘(RequestLog|&结果)’ 是一个分隔符,是正则表达式,即用’RequestLog’或者’&结果’作为分隔符;
‘{print $2}’表示将每行的第2个值打印出来,$0代表打印全部;
cat、awk、uniq、sed、more、less综合应用
cat test.txt | awk -F '(d|&s)' '{print $1}'|sort|uniq -c > testfile
tail info.log -n 3 | grep 员工 | grep zaygee | more
tail info.log -n 3 | grep 员工 | grep zaygee | less
cat -n info.log | tail -n +100 | head -n 20#tail -n +100 表示查100行之后的日志#head -n 20 表示在前面的查询结果再查20条记录
sed -n "100, 111p" info.log# 查看文件100行到111行的日志
cat test.txt:打开test.txt文件
awk -F ‘(d|&s)’ ‘{print $1}’:按规则分隔并打印第一行
sort|uniq -c:排序且计算重复
> testfile:将结果输出到文件testfile
more:可翻页查看,点击空格翻页
less:可上下翻页查看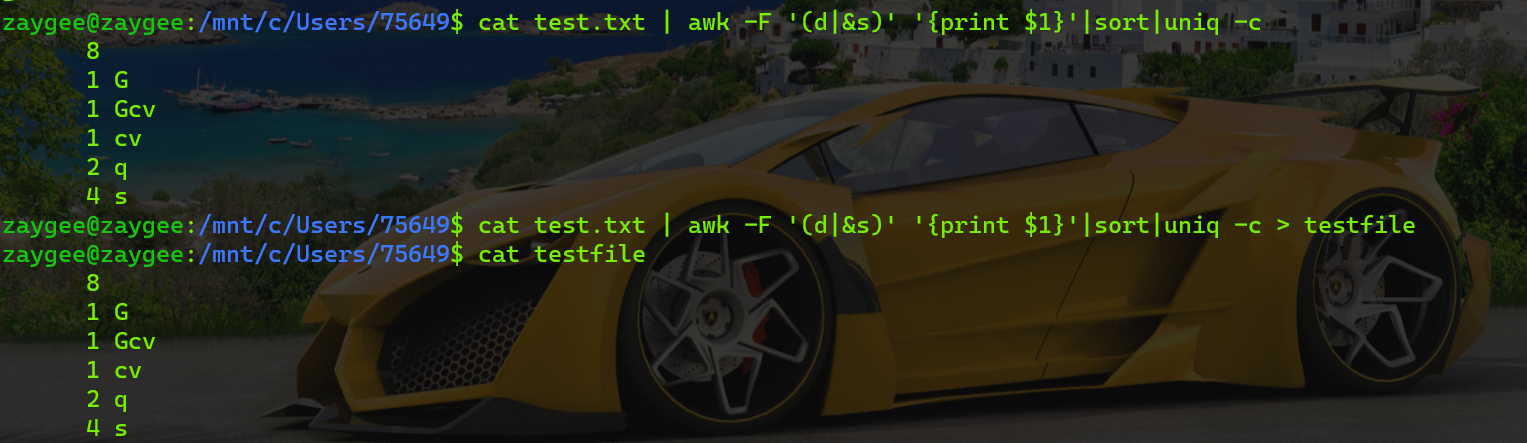

若有收获,就点个赞吧
0 人点赞
