HashMap 与 ConcurrentHashMap 的实现原理是怎样的?ConcurrentHashMap 是如何保证线程安全的?
HashMap
实现原理
HashMap主要用于存放KeyValue键值对。
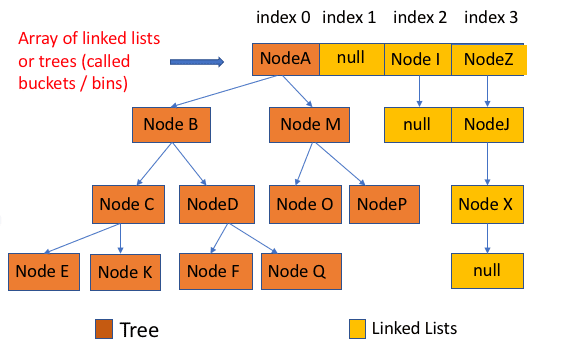
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用。
JDK1.8及之后,使用的是 数据+链表+红黑树 的数据结构。利用key使用put、get方法进行存取。
实现原理:
- key 经过hash函数处理过后得到 hash 值
- 通过 (n - 1) & hash 取模判断当前元素应该存放的位置(这里的 n 指的是数组的长度)
- 如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同
- 相同,直接覆盖
- 不相同,通过拉链法解决冲突
JDK1.8之后,当链表长度大于阈值(默认为 8)时,会首先调用 treeifyBin()方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 resize() 方法对数组扩容。
// 当桶(bucket)上的结点数大于这个值时会转成红黑树static final int TREEIFY_THRESHOLD = 8;// 当桶(bucket)上的结点数小于这个值时树转链表static final int UNTREEIFY_THRESHOLD = 6;// 桶中结构转化为红黑树对应的table的最小大小static final int MIN_TREEIFY_CAPACITY = 64;
put()方法
介绍put()方法的具体流程
参数介绍:
int hashK keyV valueboolean onlyIfAbsentboolean evict //
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
1、判断HashMap有没有被初始化
如果没有初始化,调用resize()方法进行初始化
2、根据Key计算得到hash值,再计算得到应该存放的桶的下标i
3-1、table[i]为空,(p = tab[i = (n - 1) & hash]) == null
直接插入,tab[i] = newNode(hash, key, value, null);
3-2、table[i]不为空
会首先创建临时变量Node<K,V> e; K k;
3-2-1、第一个node的key哈希值=这次put的key哈希值,if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
将该节点赋值给e,执行e=p;
3-2-2、树结构p instanceof TreeNodee = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
3-2-3、链表结构
在遍历查找的同时计算binCount
1、遍历到最后也没有找到相等的key,(e = p.next) == null,说明需要添加一个新的节点到链表,首先执行插入操作,p.next = newNode(hash, key, value, null);此时,需要检查是否存在binCount >= TREEIFY_THRESHOLD - 1,即插入链表第8个节点时需要修改链表结构为红黑树。
2、找到了相等的key,e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))),跳出遍历。
3-2-4、判断e是否为空值,即HashMap.put(key,value)这次的操作是插入还是更新。
e不为空,说明已经存在这个key的映射。
再进一步判断if (!onlyIfAbsent || oldValue == null),确认是否需要更新这个节点,(不管是否更新,如果是putIfAbsent就不更新)最后执行afterNodeAccess(e);方法,把更新后的节点放在链表的末尾(尾插法),return oldValue;结束流程。
4、e为空的情况,说明是插入了一个新的节点,++modCount (用于支持fail-fast)
5、++size>threshold,如果size大于threashold,需要进行扩容
threshold=Capacity*LoadFactor
6、执行afterNodeInsertion(evict);
默认evict=true,调用removeEldestEntry方法,但其实这个方法啥也没做
/*** <p>This implementation merely returns <tt>false</tt> (so that this* map acts like a normal map - the eldest element is never removed).*/protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}
7、return null,结束插入
Conccurent HashMap
实现原理
Java7 : 使用ReentrantLock ,结构是Segment 数组 + HashEntry 数组 + 链表
Java8 : 使用 Synchronized 锁加 CAS 的机制。结构进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
put()方法
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
有几个临时变量Node<K,V> f; int n, i, fh;
1、首先判断key,value是否为空值,如果是抛出空指针异常
2、计算key的hash值
3、如果table为空,初始化table,initTable();
4-1、table[i]==null,尝试使用 CAS 直接在该位置插入新值,如果失败会重新尝试casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null))
4-2、table[i]!=null,且(fh = f.hash) == _MOVED_,即头节点的hash值=-1,说明正在进行扩容操作,调用tab = helpTransfer(tab, f);,没有退出循环,之后会继续执行put。
4-3、table[i]!=null,且没有处在扩容状态,给数组第i个位置的节点加锁,synchronized (f)fh>=0,结构是链表,遍历的同时计算binCount,与HashMap不同的是,并没有把需要被修改的e暂存,而是在这个循环里面直接改掉并保存oldVal值。f instanceof TreeBin,fh=-2,结构是红黑树,不需要计算binCount。
5、如果binCount!=0(即进入了4-3),需要看下是否满足binCount >= TREEIFY_THRESHOLD,来决定是否需要修改链表结构为红黑树
6、如果oldVal!=null(即更新了节点值),return oldVal;,结束流程。
7、走到这里,说明是以下三种插入了新节点的情况
- table[i]==null,使用 CAS 直接在该位置插入新值,binCount=0
- table[i]!=null,遍历链表,在尾部插入新值,binCount=添加节点后链表长度
- table[i]!=null,遍历红黑树,插入新值,binCount=2
调用addCount(1L, binCount);方法,1L表示添加了1个,binCount=check,check大于0的情况下需要检查是否需要扩容(没太看懂)
8、return null;结束流程。

若有收获,就点个赞吧
0 人点赞
