本章是系列课程的第二章,讲了Node.js的一些基础知识。重点介绍了非阻塞I/O,异步编程规范,Http服务,RPC调用,以及Buffer模块对二进制的编码解码。
何为技术预研?
分析要做的需求,找出技术难点,针对每个技术难点设计 demo 进行攻克。
Node.js几个要点
全局变量
有些全局变量是浏览器中特有的,Node中没有的,比如:requestAnimationFrame,
有些是两种环境都有的,比如Date、Math、setTimout、setInterval…
有些是Node特有的
- __filename: 脚本的位置
- __dirname: 目录的位置
- process:
记录了很多信息,如图
hrtime统计时间用
env环境信息
process.argv 可以获得命令行参数:
const arg = process.argv[process.argv.length - 1]
process.stdin.on监听用户键盘输入:
// 比如监听用户输入process.stdin.on('data', e => {// e.toString().trim()})s
模块规范
script标签的问题:
- 脚本变多时,需要手动管理加载顺序
- 不同脚本之间逻辑调用,需要通过全局变量的方式
- 没有 html 怎么办?
CommonJS规范最早不是官方规范,是在JS社区中发起的,但最终被Node采用。
关于模块化我印象中这篇文章讲的好:
借用下文章中关于CJS的结论:
- CommonJS 模块由 JS 运行时实现。
- CommonJs 是单个值导出,本质上导出的就是 exports 属性。
- CommonJS 是可以动态加载的,对每一个加载都存在缓存,可以有效的解决循环引用问题。
- CommonJS 模块同步加载并执行模块文件。
包管理器
npm、yarn、pnpm…等都是包管理器,都是统一的,借助package.json声明文件。 包本质就是别人写的 Node.js 模块,可以说,没有 npm,也不会有现在这么繁荣的 JS 社区。
npm最近基本的操作,比如:
- npm init 初始化npm包
- npm install xxx
EventEmitter
观察者模式
- addEventListener
- removeEventListener
buffer
net
非阻塞I/O
啥是非阻塞I/O
I/O 即 Input/Output,一个系统的输入和输出。
所谓“阻塞 I/O” 和“非阻塞 I/O” 的区别就在于,系统接收输入再到输出期间,能不能接收其
他输入。
举个例子:系统 = 食堂阿姨 and 服务生,输入 = 点菜,输出 = 上菜
- 饭堂阿姨只能一份一份饭地打 -> 阻塞 I/O
- 服务生点完菜之后可以服务其他客人 -> 非阻塞 I/O
分析对象也很重要
NodeI/O架构: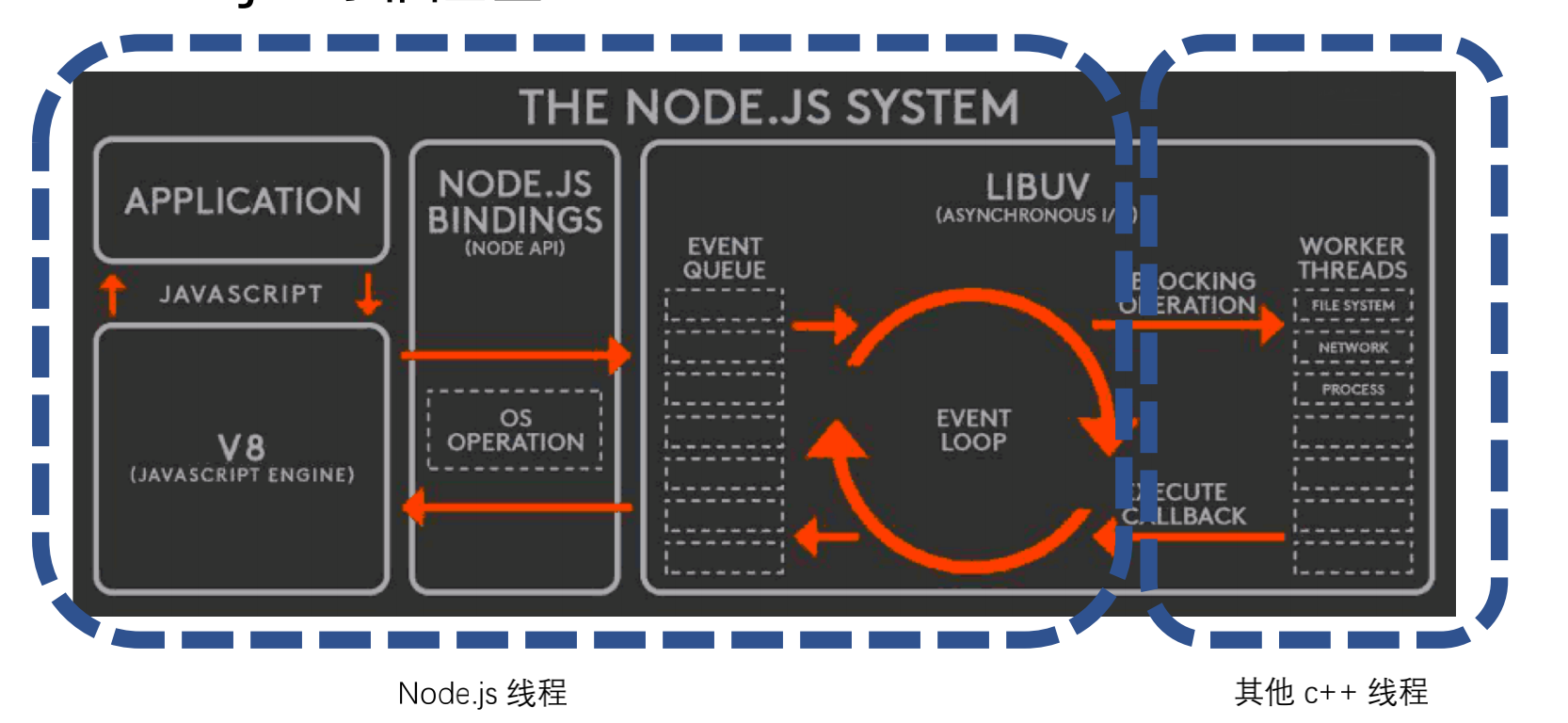
非阻塞I/O的异步编程
- 回调函数
node.js中的回调函数函数又参数格式规范:
- error-first callback
- node-style callback
第一个参数是 error,后面的参数才是结果。为啥这样的呢?
// 试图trytry {asyncAbc(callback)} catch (e) { /* ... */}function callback(data) { /* ... */}function asyncAbc (callback) {setTimout(() => { throw new Error('async error')} , 1000)}
上面代码试图用try-catch来捕获错误,但是异步函数执行产生的错误很大概率不在当前的调用栈,所以try-catch根本捕获不到。
所以,为了使能处理错误,才有了规范,第一个参数是 error,往后的参数是结果:
function asyncAbc (callback) {const data = 'jay chou'setTimout(() => { callback(new Error('async error'), data)} , 1000)}function callback(err, data) {if (!err) { /* ... */}}
callback的问题老生常谈了,所以解决方案就是promise,async-await….不赘述了。
HTTP服务
HTTP协议
大致就是红字这一层,不过意会一下,不是很准确感觉
一个网页请求,包含两次 HTTP 包交换:
• 浏览器向 HTTP 服务器发送请求 HTTP 包
• HTTP 服务器向浏览器返回 HTTP 包
http模块
Node.js中自带http模块,可以快速搭建一个http server
const http = require('http')http.createServer(function (req, res) {res.writeHend(200)res.end('hello')}).listen(3000)
再比如,返回本地文件
const http = require('http')const fs = require('fs')http.createServer(function (req, res) {const { url } = reqif (url === '/favicon.ico') {res.writeHead(200)res.end()return}response.writeHead(200)fs.createReadStream(__dirname, 'index.html').pipe(res)}).listen(3000)
这里if判断的原因是:浏览器请求一个地址的时候有一个默认行为就是同时发起一个请求请求路径是 /favicon.ico。
另外,httpserver是一个第三方包,可以在本地快速建立server访问本地文件。
express
提供 get post等方法分发路由 … 以及中间件的能力。
所谓中间件其实本质是函数的串联(洋葱圈模型)
express.get就可以接受多参数,比如:
app.get('/ddddd', function (req, rsp, next) { // 处理函数1// 进入逻辑1next() // 调用next就是调用下一个函数// 返回逻辑}, function(req, rsp) { // 处理函数2// 逻辑2})
不过express的中间件对异步处理是失效的,这是不完善的地方
koa
相比express,koa的特点有:
- 更极致的 request/response 简化,比如ctx.status = 200 、ctx.body = ‘hello world’
- 使用 async function 实现的中间件,有“暂停执行”的能力 ,在异步的情况下也符合洋葱模型
express 对比 koa
express 门槛更低,koa 更强大优雅
express 封装更多东西,开发更快速,koa 可定制型更高
code demo:koa石头剪刀布
RPC调用
简单说,其实就是Server to Server的通信。
RPC(Remote Procedure Call),远程过程调用。
RPC和Ajax的比较
相同点:
- 都是计算机间的通信
- 都需要双方约定数据格式
不同点:
- RPC可能不需要经过DNS寻址(内部)
- 一般不用HTTP协议,TCP或者UDP用的更多
上述要点解释下。
RPC一般不是HTTP协议,而是二进制协议。因为数据包小,解码更快。
TCP通信方式:
- 单工(只能固定一方向另一方);
- 半双工(轮番单工通信);
- 全双工(双方自由通信,意味着不能按照顺序去对应返回结果,所以需要带上序号来对应)
Ajax 请求的话是这么个过程:
域名 ->DNS解析IP -> IP返回给浏览器 -> 那IP访问Server -> Server Response Data
RPC可能也是需要寻址(内网的寻址服务器)
I5/VIP(虚拟IP) ->寻址服务器 -> IP返回Server Client -> 那IP访问Server -> Server Response Data
整体过程比较相似,主要差别就在寻址了。
说到二进制编解码,需要介绍下buffer模块。
buffer
buffer可以处理流数据。
- 创建
Buffer.from()
const buf1 = Buffer.from('hello')const buf2 = Buffer.from([1, 2, 3, 4])
Buffer.alloc()
const buf3 = Buffer.alloc(20)// 打印// <Buffer 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00>// 每一个00都可以表示16 * 16大小
- 读写
BE、LE就是高位、低位排布的区别,啥意思就是:
buf.writeInt16BE(512, 0) //大端, 第二个参数是偏移量buf.writeInt16LE(512, 0) //大端, 第二个参数是偏移量// BE LE区别const buf = Buffer.allocUnsafe(2);buf.writeInt16BE(256, 0)console.log(buf); // <Buffer 01 00>buf.writeInt16LE(256, 0)console.log(buf); // <Buffer 00 01>
读取的方法也类似:
位数固定且超过1个字节的: read{Double| Float | Int16 | Int32 | UInt16 | UInt32 }{BE|LE}(offset) 位数不固定的: read{Int | UInt}{BE | LE}(offset, byteLength) 位数固定是1个字节的: read{Int8 | Unit8}(offset) Double、Float、Int16、Int32、UInt16、UInt32既确定了表征数字的位数,也确定了是否包含负数,因此定义了不同的数据范围。同时由于表征数字的位数都超过8位,无法用一个字节来表示,因此就涉及到了计算机的字节序区分(大端字节序与小端字节序)
- 转字符串
const buf = Buffer.from('test');console.log(buf.toString('utf8')); // testconsole.log(buf.toString('utf8', 0, 2)); // te
二进制协议Protocol Buffers介绍
Protocol Buffers : google的语言不相干规范, 通过协议文件控制 Buffer 的格式,更直观 、更好维护 、更便于合作node 社区有 protocol-buffers,直接 npm install protocol-buffers。
code: protocol-buffers例子
net模块
net模块用来搭建TCP Server
const net = require('net');const socket = new net.Socket({});// 通过socket写入socket.connect({host: '127.0.0.1',port: 4000})socket.write('good morning geekbang');
const net = require('net');// 参数是socket,通过socket拿到数据const server = net.createServer((socket)=> {socket.on('data', function(buffer) {console.log(buffer, buffer.toString())})});server.listen(4000);
上面就是单工通信,就是说单向的通信,一方发送,另一方接收,那当然也可以半双工通信和全双工通信。
区别就是这样: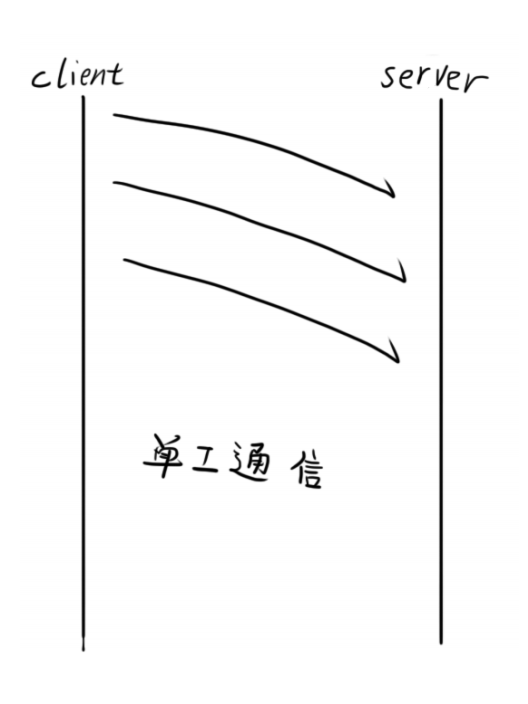

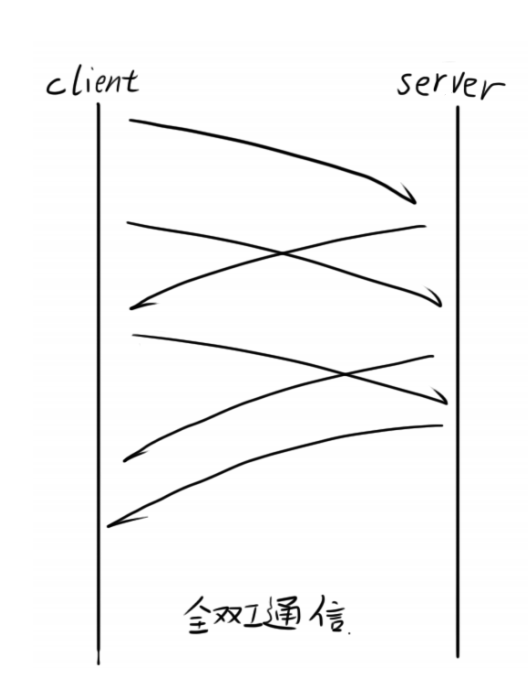
code demo:
code: net模块例子

若有收获,就点个赞吧
0 人点赞
