一、Hive内容补充
1、with… as
with as 也叫做子查询部分,hive 可以通过with查询来提高查询性能,因为先通过with语法将数据查询到内存,然后后面其它查询可以直接使用。
with t as (select *, row_number()over(partition by id order by salary desc) ranking from tmp_learning_mary)select * from t where ranking = 1;
with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以!
其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标。
使用注意事项:
1.with子句必须在引用的select语句之前定义,而且后面必须要跟select查询,否则报错。
2.with as后面不能加分号,with关键字在同级中只能使用一次,允许跟多个子句,用逗号隔开,最后一个子句与后面的查询语句之间只能用右括号分隔,不能用逗号。
create table a aswith t1 as (select * from firstTable),t2 as (select * from secondTable),t3 as (select * from thirdTable)select * from t1,t2,t3;
3.前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句。
with t1 as (select * from firstTable),t2 as (select t1.id from t1) #第二个子句t2中用了第一个子句的查询t1select * from t2
2、hive的多维分析(mysql 8.0也开始支持)
先看数据:在/root/hivedata/duowei01.txt
A|3|男|45B|3|女|55C|2|女|74D|3|男|90E|1|男|80F|2|女|92G|1|女|95H|1|男|95I|3|女|99J|3|男|99
create table tmp_student(name string,class int,sex string,score int)row format delimited fields terminated by '|';
load data local inpath '/root/hivedata/duowei01.txt' into table tmp_student;
hive> select * from tmp_student;OKA 3 男 45B 3 女 55C 2 女 74D 3 男 90E 1 男 80F 2 女 92G 1 女 95H 1 男 95I 3 女 99J 3 男 99Time taken: 0.377 seconds, Fetched: 10 row(s)
数据表有4个字段:姓名、班级、性别、分数。如果我想按照以下3个粒度汇总:1、每个班级的平均分数2、每个性别的平均分数3、每个班级下不同性别的平均分数则使用多个sql分别汇总的方案为:select class, avg(score) from tmp_student group by class;select sex, avg(score) from tmp_student group by sex;select class, sex, avg(score) from tmp_student group by class, sex;修改,添加多维分析select class, sex, avg(score) from tmp_student group by class, sex grouping sets(class,sex,(class,sex));
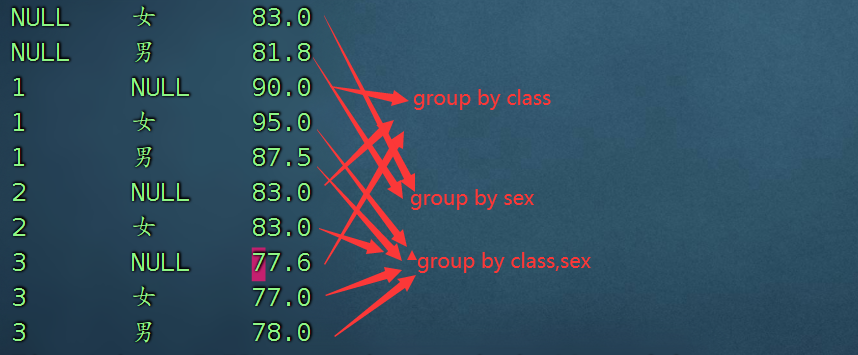
selectgrouping__id, -- 内置变量,只要使用grouping sets就可以调用class,sex,avg(score) as avg_scorefromtmp_studentgroup byclass,sexgrouping sets(class,sex,(class, sex))
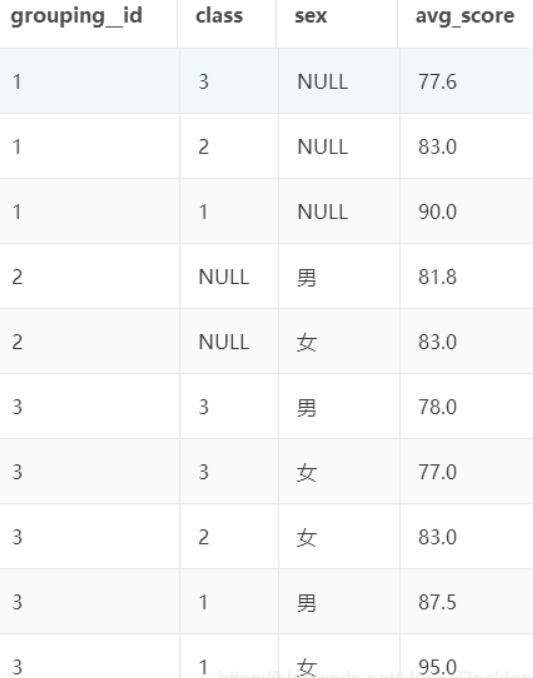
可以看到,使用 grouping sets 同时汇总出了 3 种不同粒度的平均分数。注意:1、grouping sets 只能用于 group by 之后。2、grouping sets 中可以包含多种粒度,粒度之间用逗号连接。3、grouping sets 中的所有字段,都必须出现在 group by 中,相当于 group by 后面的字段是最细粒度。4、如果 select 中的字段,没有包含在某个 grouping set 中,那么这个粒度下的这个字段值为 NULL。4、不同的粒度,可以使用内置变量 grouping__id 进行区分。
grouping_id计算方法
grouping sets 中的每一种粒度,都对应唯一的 grouping__id 值,其计算公式与 group by 的顺序、当前粒度的字段有关。
具体计算方法如下:
将 group by 的所有字段 倒序 排列。
对于每个字段,如果该字段出现在了当前粒度中,则该字段位置赋值为1,否则为0。
这样就形成了一个二进制数,这个二进制数转为十进制,即为当前粒度对应的 grouping__id。
以上述对 tmp_student 的3种粒度的统计结果为例:
1、group by 的所有字段倒序排列为:sex class
2、对于 3 种 grouping sets,分别对应的二进制数为:
序号 grouping set 给倒序排列的字段(sex class)赋值 对应的十进制(grouping__id 的值)
| 维度 | sex | class | 对应的十进制 |
|---|---|---|---|
| class | 0 | 1 | 1 |
| sex | 1 | 0 | 2 |
| class,sex | 1 | 1 | 3 |
1 class 0 1 => 1
2 sex 1 0 => 2
3 class,sex 1 1 => 3
这就是上面 grouping sets 的结果中 grouping__id 值的由来。
官网介绍:
再看一个案例:
[whalex@hadoop102data]$ vim test.txt1001 John male sale beijing1002 Tom female sale shanghai1003 Bob male sale beijing1004 Alex male product shanghai
create table test_duowei(id string,name string,sex string,dept_name string,addr string) row format delimited fields terminated by '\t';load data local inpath '/root/hivedata/duowei02.txt' overwrite into table test_duowei;
需求:
按照性别分组计算每种性别的人数按照部门和性别分组计算每个部门每种性别的人数按照地区和性别分组计算每个地区每种性别的人数
解答:
select sex,count(*) ct from test group by sex;select dept_name,sex,count(*) ct from test group by dept_name,sex;select addr,sex,count(*) ct from test group by addr,sex;
多维分析:
select dept_name,addr,sex,count(*) ct from test group by dept_name,addr,sex grouping sets((sex),(dept_name,sex),(addr,sex)) order by dept_name,addr,sex;+------------+-----------+---------+-----+| dept_name | addr | sex | ct |+------------+-----------+---------+-----+| NULL | NULL | female | 1 || NULL | NULL | male | 3 || NULL | beijing | male | 2 || NULL | shanghai | female | 1 || NULL | shanghai | male | 1 || product | NULL | male | 1 || sale | NULL | female | 1 || sale | NULL | male | 2 |+------------+-----------+---------+-----+
HQL中的order by只是为了让输出结果更好看一些,没有其他意义。
With Cube解决计算所有维度组合问题:
此时需要计算地区、部门以及性别三个维度所有组合的聚合数据
我们当然还可以使用Grouping Sets来解决问题,HQL如下:
select dept_name,addr,sex,count(*) ct from test group by dept_name,addr,sex grouping sets((addr,dept_name,sex),(addr,dept_name),(addr,sex),(dept_name,sex),(addr),(dept_name),(sex),()) order by dept_name,addr,sex;+------------+-----------+---------+-----+| dept_name | addr | sex | ct |+------------+-----------+---------+-----+| NULL | NULL | NULL | 4 || NULL | NULL | female | 1 || NULL | NULL | male | 3 || NULL | beijing | NULL | 2 || NULL | beijing | male | 2 || NULL | shanghai | NULL | 2 || NULL | shanghai | female | 1 || NULL | shanghai | male | 1 || product | NULL | NULL | 1 || product | NULL | male | 1 || product | shanghai | NULL | 1 || product | shanghai | male | 1 || sale | NULL | NULL | 3 || sale | NULL | female | 1 || sale | NULL | male | 2 || sale | beijing | NULL | 2 || sale | beijing | male | 2 || sale | shanghai | NULL | 1 || sale | shanghai | female | 1 |+------------+-----------+---------+-----+
此时我们也可以使用With Cube来解决问题:
GROUP BY a, b, c WITH CUBE 等同于GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (b, c), (a, c), (a), (b), (c), ( )).
所以我们的HQL语句是这样的:
select dept_name,addr,sex,count(*) ct from test_duowei group by dept_name,addr,sex with cube order by dept_name,addr,sex;+------------+-----------+---------+-----+| dept_name | addr | sex | ct |+------------+-----------+---------+-----+| NULL | NULL | NULL | 4 || NULL | NULL | female | 1 || NULL | NULL | male | 3 || NULL | beijing | NULL | 2 || NULL | beijing | male | 2 || NULL | shanghai | NULL | 2 || NULL | shanghai | female | 1 || NULL | shanghai | male | 1 || product | NULL | NULL | 1 || product | NULL | male | 1 || product | shanghai | NULL | 1 || product | shanghai | male | 1 || sale | NULL | NULL | 3 || sale | NULL | female | 1 || sale | NULL | male | 2 || sale | beijing | NULL | 2 || sale | beijing | male | 2 || sale | shanghai | NULL | 1 || sale | shanghai | female | 1 |+------------+-----------+---------+-----+
With Rollup解决计算层级维度组合问题:
数据:
1 2020 12 31 562 2020 12 31 893 2021 01 01 784 2021 01 01 675 2021 01 02 56
create table test_rollup(order_id int,year string,month string,day string,order_amount int) row format delimited fields terminated by '\t';
load data local inpath "/root/hivedata/duowei03.txt" overwrite into table test_rollup;
现在需要按照时间统计销售总额,注意按照时间聚合数据的时候,单独的月份、单独的天、月份和天以及年和天的维度聚合出来的指标是没有意义的,也就是说按照时间维度聚合指标时只有“年月日”、“年月”、“年”以及不添加维度信息计算总和时才是有意义的。
这种像年月日维度的可以称为层级维度,同样可以使用Grouping Sets来解决该需求,HQL如下:
select year,month,day,sum(order_amount) from test_rollup group by year,month,day grouping sets((year,month,day),(year,month),(year),()) order by year,month,day;+-------+--------+-------+------+| year | month | day | _c3 |+-------+--------+-------+------+| NULL | NULL | NULL | 346 || 2020 | NULL | NULL | 145 || 2020 | 12 | NULL | 145 || 2020 | 12 | 31 | 145 || 2021 | NULL | NULL | 201 || 2021 | 01 | NULL | 201 || 2021 | 01 | 01 | 145 || 2021 | 01 | 02 | 56 |+-------+--------+-------+------+
此时我们还可以使用With Rollup来解决该需求:
GROUP BY a, b, c, WITH ROLLUP 等同于GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( )).
所以HQL语句为:
select year,month,day,sum(order_amount) from test_rollup group by year,month,day with rollup order by year,month,day;+-------+--------+-------+------+| year | month | day | _c3 |+-------+--------+-------+------+| NULL | NULL | NULL | 346 || 2020 | NULL | NULL | 145 || 2020 | 12 | NULL | 145 || 2020 | 12 | 31 | 145 || 2021 | NULL | NULL | 201 || 2021 | 01 | NULL | 201 || 2021 | 01 | 01 | 145 || 2021 | 01 | 02 | 56 |+-------+--------+-------+------+
总结:
Hive中提供了grouping sets、with cube以及with rollup来解决多维分析的问题,当维度特别多时,我们根据具体情况可以使用对应的函数来解决问题。我们可以将结果输出到一张表中方便后续查询,比如我们是a,b,c三个维度使用with cube计算的结果集,当我们只需要group by a的结果时,我们可以使用select a,ct from result_table where a is not null and b is null and c is null;这样的HQL获取需要的结果,避免了我们在开头提到了多条HQL需要使用多张表来保存数据给最后查询带来麻烦的问题。
3、复习hive函数
1)hive中解析url的parse_url函数解析url
举例:
https://www.baidu.com/hzy?user_id=10000&platform=ios
例子:
protocol(协议):https,一种可以通过安全的 HTTPS 访问该资源的传输协议select parse_url('https://www.baidu.com/hzy?user_id=10000&platform=ios','PROTOCOL') ;https解析主机名:hostname(主机名)select parse_url('https://www.baidu.com/hzy?user_id=10000&platform=ios','HOST');www.baidu.compath(路径):由零或多个“/”符号隔开的字符串,一般用来表示主机上的一个目录或文件地址select parse_url('https://www.baidu.com/hzy?user_id=10000&platform=ios','PATH');/hzyquery(查询):可选,用于给动态网页传递参数,可有多个参数,用“&”符号隔开,每个参数的名和值用“=”符号隔开select parse_url('https://www.baidu.com/hzy?user_id=10000&platform=ios','QUERY');user_id=10000&platform=ios解析QUERY部分的value值:select parse_url('https://www.baidu.com/hzy?user_id=10000&platform=ios','QUERY','user_id');10000select parse_url('https://www.baidu.com/hzy?user_id=10000&platform=ios','QUERY','platform');ios
2)get_json_object 函数
[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]
获取一个json对象:
select get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]','$[0]');结果是:{"name":"大郎","sex":"男","age":"25"}
获取age:
hive (gmall)>SELECT get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]',"$[0].name");结果是:25如果数据直接是一个json对象,获取时使用$.字段名字 即可获取。SELECT get_json_object('{"name":"大郎","sex":"男","age":"25"}',"$.name");
4、动态分区
动态分区是分区在数据插入的时候,根据某一列的列值动态生成.
往hive分区表中插入数据时,如果需要创建的分区很多,比如以表中某个字段进行分区存储,则需要复制粘贴修改很多sql去执行,效率低。因为hive是批处理系统,所以hive提供了一个动态分区功能,其可以基于查询参数的位置去推断分区的名称,从而建立分区。
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。详细来说,静态分区的列实在编译时期,通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
例如:
hive> insert overwrite table partition_test partition(stat_date='20110728',province='henan')selectmember_id,namefrompartition_test_inputwherestat_date='20110728' and province='henan';
insert overwrite table partition_test partition(stat_date='20110728',province)selectmember_id,name,provincefrompartition_test_inputwherestat_date='20110728';
案例:
[root@zjj101 soft]# cat order_created.txt10703007267488 usa 2014-05-0110101043505096 usa 2014-05-0110103043509747 china 2014-05-0210103043501575 china 2014-05-0210104043514061 china 2014-05-01
-- 创建普通表create table order_partition(order_no string,type string,order_time string)row format delimited fields terminated by '\t';-- 装载数据load data local inpath '/root/hivedata/order_created.txt' into table order_partition;-- 查询数据是否装载成功select * from order_partition;
创建分区表:
create table order_dynamic_partition(order_no string)PARTITIONED BY (type string,`time` string)row format delimited fields terminated by '\t';
动态分区表的属性使用动态分区表必须配置的参数 :set hive.exec.dynamic.partition =true(默认false),表示开启动态分区功能set hive.exec.dynamic.partition.mode = nonstrict(默认strict),表示允许所有分区都是动态的,否则必须有静态分区字段动态分区相关的调优参数:set hive.exec.max.dynamic.partitions.pernode=100 (默认100,一般可以设置大一点,比如1000) 表示每个maper或reducer可以允许创建的最大动态分区个数,默认是100,超出则会报错。set hive.exec.max.dynamic.partitions =1000(默认值) 表示一个动态分区语句可以创建的最大动态分区个数,超出报错set hive.exec.max.created.files =10000(默认) 全局可以创建的最大文件个数,超出报错。
set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nostrick;insert overwrite table order_dynamic_partitionpartition (type, `time`)select order_no, type, order_timefrom order_partition;
show partitions order_dynamic_partition;
二、DWD层数据构建
先创建数据库:
create database dwd_nshop;use dwd_nshop;
1、用户主题
一定要理解这个码表(这个是理解整个SQL的核心部分):
action行为种类:INSTALL("01", "install","安装"),LAUNCH("02", "launch","启动"),LOGIN("03", "login","登录"),REGISTER("04", "register","注册"),INTERACTIVE("05", "interactive","交互行为"),EXIT("06", "exit","退出"),PAGE_ENTER_H5("07", "page_enter_h5","页面进入"),PAGE_ENTER_NATIVE("08", "page_enter_native","页面进入")eventtype事件类型:VIEW("01", "view","浏览"),CLICK("02", "click","点击"),INPUT("03", "input","输入"),SLIDE("04", "slide","滑动")
1)用户启动日志表
create external table if not exists dwd_nshop.dwd_nshop_actlog_launch(user_id string comment '用户id',device_num string comment '设备号',device_type string comment '设备类型',os string comment '手机系统',os_version string comment '手机系统版本',manufacturer string comment '手机制造商',carrier string comment '电信运营商',network_type string comment '网络类型',area_code string comment '地区编码',launch_time_segment string comment '启动时间段',-- 启动时间段分为四个阶段(0-6、6-12、12-18/18-24)每个阶段用 1 2 3 4表示ct bigint comment '产生时间') partitioned by (bdp_day string)stored as parquetlocation '/data/nshop/dwd/user/dwd_nshop_actlog_launch/';
表创建好了,数据如何导入?
insert overwrite table dwd_nshop.dwd_nshop_actlog_launch partition(bdp_day='20220509')selectcustomer_id ,device_num ,device_type ,os ,os_version ,manufacturer ,carrier ,network_type,area_code ,casewhen from_unixtime(cast(ct/1000 as int),'HH') > 0and from_unixtime(cast(ct/1000 as int),'HH') <=6 then 1when from_unixtime(cast(ct/1000 as int),'HH') > 6and from_unixtime(cast(ct/1000 as int),'HH') <=12 then 2when from_unixtime(cast(ct/1000 as int),'HH') > 12and from_unixtime(cast(ct/1000 as int),'HH') <=18 then 3else 4end,ctfrom ods_nshop.ods_nshop_01_useractlogwhere bdp_day='20220509' and action='02';
总结:
根据我们给定的dwd的表结构,拿着我们之前的ods表结构,然后编写对应的SQL语句,将查询出来的数据,导入到dwd的表中。
2、用户产品浏览表
create external table if not exists dwd_nshop.dwd_nshop_actlog_pdtview(user_id string comment '用户id',device_num string comment '设备号',device_type string comment '设备类型',os string comment '手机系统',os_version string comment '手机系统版本',manufacturer string comment '手机制造商',carrier string comment '电信运营商',network_type string comment '网络类型',area_code string comment '地区编码',target_id string comment '产品ID',duration int comment '停留时长',ct bigint comment '产生时间') partitioned by (bdp_day string)stored as parquetlocation '/data/nshop/dwd/user/dwd_nshop_actlog_pdtview/'
编写对应的SQL语句插入表数据
insert overwrite table dwd_nshop.dwd_nshop_actlog_pdtview partition(bdp_day='20220509')selectcustomer_id ,device_num ,device_type ,os ,os_version ,manufacturer ,carrier ,network_type,area_code ,get_json_object(extinfo,'$.target_id') as target_id,duration,ctfrom ods_nshop.ods_nshop_01_useractlogwhere bdp_day='20220509' and action in ('07','08')and event_type ='01';
3、用户产品查询表
create external table if not exists dwd_nshop.dwd_nshop_actlog_pdtsearch(user_id string comment '用户id',device_num string comment '设备号',device_type string comment '设备类型',os string comment '手机系统',os_version string comment '手机系统版本',manufacturer string comment '手机制造商',carrier string comment '电信运营商',network_type string comment '网络类型',area_code string comment '地区编码',target_order string comment '查询排序方式',target_keys string comment '查询内容',target_id string comment '查询商品ID',ct bigint comment '产生时间') partitioned by (bdp_day string)stored as parquetlocation '/data/nshop/dwd/user/dwd_nshop_actlog_pdtsearch/';
根据查询出来的结果数据,我们看到原始数据:
{"target_type":"4","target_keys":"","target_order":"20","target_ids":"[\"4320901202801\",\"4320901118101\",\"4320901823501\",\"4320901106001\"]"}get_json_object(extinfo,'$.target_ids')["4320901202801","4320901118101","4320901823501","4320901106001"]regexp_replace(get_json_object(extinfo,'$.target_ids'),'[\\[\\]]','')"4320901202801","4320901118101","4320901823501","4320901106001"split(regexp_replace(get_json_object(extinfo,'$.target_ids'),'[\\[\\]]',''),',')4320901202801,4320901118101,4320901823501,4320901106001
insert overwrite table dwd_nshop.dwd_nshop_actlog_pdtsearch partition(bdp_day='20220509')selectcustomer_id ,device_num ,device_type ,os ,os_version ,manufacturer ,carrier ,network_type,area_code ,get_json_object(extinfo,'$.target_order') as target_order,get_json_object(extinfo,'$.target_keys') as target_keys,target_id,ctfrom ods_nshop.ods_nshop_01_useractloglateral view explode(split(regexp_replace(get_json_object(extinfo,'$.target_ids'),'[\\[\\]\"]',''),',')) t as target_idwhere bdp_day='20220509' and action ='05'and event_type in ('01','04');
4、用户关注店铺表
create external table if not exists dwd_nshop.dwd_actlog_product_comment(user_id string comment '用户id',device_num string comment '设备号',device_type string comment '设备类型',os string comment '手机系统',os_version string comment '手机系统版本',manufacturer string comment '手机制造商',carrier string comment '电信运营商',network_type string comment '网络类型',area_code string comment '地区编码',target_id string comment '产品ID',ct bigint comment '产生时间') partitioned by (bdp_day string)stored as parquetlocation '/data/nshop/dwd/user/dwd_actlog_product_comment/'
编写SQL语句:
with t1 as (selectcustomer_id,device_num ,device_type ,os ,os_version ,manufacturer ,carrier ,network_type,area_code ,get_json_object(extinfo,'$.target_type') as target_type,get_json_object(extinfo,'$.target_action') as target_action,get_json_object(extinfo,'$.target_id') as target_id,ctfrom ods_nshop.ods_nshop_01_useractlogwhere bdp_day='20220509' and action='05' and event_type='02')insert overwrite table dwd_nshop.dwd_actlog_product_comment partition(bdp_day='20220509')selectcustomer_id,device_num ,device_type ,os ,os_version ,manufacturer ,carrier ,network_type,area_code ,target_id,ct from t1 where target_action='01' and target_type = 3;
2、交易主题
交易明细表(ods_nshop.ods_02_orders,ods_nshop.ods_02_order_detail,dim_nshop.dim_pub_product,ods_nshop.ods_02_orders_pay_records)
create external table if not exists dwd_nshop.dwd_nshop_orders_details(order_id string comment '订单ID',order_status int comment '订单状态:5已收货(完成)|6投诉 7退货',supplier_code VARCHAR(20) COMMENT '店铺ID',product_code VARCHAR(20) COMMENT '商品ID',customer_id string comment '用户id',consignee_zipcode string comment '收货人地址',pay_type string comment '支付类型:线上支付 10 网上银行 11 微信 12 支付宝 | 线下支付(货到付款) 20 ',pay_nettype varchar(1) COMMENT '支付网络方式:0 wifi | 1 4g | 2 3g |3 线下支付',pay_count int comment '支付次数',product_price DECIMAL(5,1) COMMENT '购买商品单价',product_cnt INT COMMENT '购买商品数量',weighing_cost DECIMAL(2,1) COMMENT '商品加权价格',district_money DECIMAL(4,1) COMMENT '优惠金额',shipping_money DECIMAL(8,1) COMMENT '运费金额',payment_money DECIMAL(10,1) COMMENT '支付金额',is_activity int COMMENT '1:参加活动|0:没有参加活动',order_ctime bigint comment '创建时间') partitioned by (bdp_day string)stored as parquetlocation '/data/nshop/dwd/order/dwd_nshop_orders_details/'
with t1 as (selectcount(1) as pay_count,order_idfrom ods_nshop.ods_02_orders_pay_recordswhere from_unixtime(cast(pay_ctime/1000 as int),'yyyyMMdd') = '20191102'group by order_id),t2 as (selectorder_id,order_status,customer_id,consignee_zipcode,pay_type,pay_nettype,district_money,shipping_money,payment_money,order_ctimefrom ods_nshop.ods_02_orderswhere from_unixtime(cast(order_ctime/1000 as int),'yyyyMMdd') = '20191102'),t3 as (selecta.order_id,a.product_id,a.product_cnt,a.product_price,a.weighing_cost,a.is_activity,b.supplier_codefrom ods_nshop.ods_02_order_detail ajoin ods_nshop.dim_pub_product bon a.product_id = b.product_codewhere from_unixtime(cast(order_detail_ctime/1000 as int),'yyyyMMdd') = '20191102')insert overwrite table dwd_nshop.dwd_nshop_orders_details partition(bdp_day='20220509')selectt2.order_id,t2.order_status,t3.supplier_code,t3.product_id,t2.customer_id,t2.consignee_zipcode,t2.pay_type,t2.pay_nettype,t1.pay_count,t3.product_price,t3.product_cnt,t3.weighing_cost,t2.district_money,t2.shipping_money,t2.payment_money,t3.is_activity,t2.order_ctimefrom t1 join t2on t1.order_id = t2.order_idjoin t3on t2.order_id = t3.order_id;
3、营销主题
广告投放数据表:
create external table if not exists dwd_nshop.dwd_nshop_releasedatas(customer_id string comment '用户id',device_num string comment '设备号',device_type string comment '设备类型',os string comment '手机系统',os_version string comment '手机系统版本',manufacturer string comment '手机制造商',area_code string comment '地区编码',release_sid string comment '投放请求id',release_ip string comment '投放方ip',release_session string comment '投放会话id',release_sources string comment '投放渠道',release_category string comment '投放浏览产品分类',release_product string comment '投放浏览产品',release_product_page string comment '投放浏览产品页',ct bigint comment '创建时间') partitioned by (bdp_day string)stored as parquetlocation '/data/nshop/dwd/release/dwd_nshop_releasedatas/'
with t1 as (selectb.customer_id,a.device_num,a.device_type ,a.os ,a.os_version ,a.manufacturer ,a.area_code ,a.release_sid ,parse_url(concat("http://127.0.0.1:8888/path?",a.release_params),'QUERY','ip') as release_ip,a.release_session,a.release_sources,parse_url(concat("http://127.0.0.1:8888/path?",a.release_params),'QUERY','productPage') as release_product_page,a.ctfrom ods_nshop.ods_nshop_01_releasedatas ajoin ods_nshop.ods_02_customer bon a.device_num = b.customer_device_numwhere a.bdp_day='20220509')insert overwrite table dwd_nshop.dwd_nshop_releasedatas partition(bdp_day='20220509')selectt1.customer_id,t1.device_num,t1.device_type ,t1.os ,t1.os_version ,t1.manufacturer ,t1.area_code ,t1.release_sid,t1.release_ip,t1.release_session,t1.release_sources,c.category_code,b.page_target,t1.release_product_page,t1.ctfrom t1join ods_nshop.dim_pub_page bon t1.release_product_page = b.page_code and b.page_type = '4'join ods_nshop.dim_pub_product con b.page_target = c.product_code;
由于这个任务比较大,有可能出现内存溢出的情况,可以将本地模式关闭,使用集群模式运行该任务。
set hive.exec.mode.local.auto=false;

若有收获,就点个赞吧
0 人点赞
