下载
版本代码
0.9.0 版本请使用社区 release-0.9.0 分支
0.10.1 版本直接使用社区的 release-0.10.1 tag
0.11.1 https://github.com/apache/hudi/tree/release-0.11.1
版本适配
0.9.0 适配 flink 1.12.2
- 0.10.1 适配 flink 1.13.x
0.11.1 适配 flink 1.13.x 和 1.14.x
Hive 版本适配
参考 Hive 同步打包部分
0.11.1 Bugs
MOR 表 bootstrap index 丢失问题:https://github.com/apache/hudi/pull/5888 critical
流读/metadata table 极端 case 文件找不到问题:https://github.com/apache/hudi/pull/5866/files minor
file id 存在但是找不到文件问题:https://github.com/apache/hudi/pull/5917 critical
启动 rollback 极端 case 数据丢失:https://github.com/apache/hudi/pull/5950 minor
cow append 模式文件找不到: https://github.com/apache/hudi/pull/5988 major
Quick Start
参数设置
内存参数
Note:我们在内存调优的时候需要先关注 TaskManager 的数量和内存配置,以及 write task 的并发 即 write.tasks: 4 的值,确认每个 write task 能够分配到的内存,再考虑相关的内存参数设置。
Note:所有的内存参数单位都是 MB。
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| write.task.max.size | 一个 write task 的最大可用内存 | 1024 |
当前预留给 write buffer 的内存为write.task.max.size - compaction.max_memory当 write task 的内存 buffer 打到阈值后会将内存里最大的 buffer flush 出去 |
| write.batch.size | Flink 的写 task 为了提高写数据效率,会按照写 bucket 提前 buffer 数据,每个 bucket 的数据在内存达到阈值之前会一直 cache 在内存中,当阈值达到会把数据 buffer 传递给 hoodie 的 writer 执行写操作 | 256 |
一般不用设置,保持默认值就好 |
| write.log_block.size | hoodie 的 log writer 在收到 write task 的数据后不会马上 flush 数据,writer 是以 LogBlock 为单位往磁盘刷数据的,在 LogBlock 攒够之前 records 会以序列化字节的形式 buffer 在 writer 内部 | 128 |
一般不用设置,保持默认值就好 |
| write.merge.max_memory | hoodie 在 COW 写操作的时候,会有增量数据和 base file 数据 merge 的过程,增量的数据会缓存在内存的 map 结构里,这个 map 是可 spill 的,这个参数控制了 map 可以使用的堆内存大小 | 100 |
一般不用设置,保持默认值就好 |
| compaction.max_memory | 同 write.merge.max_memory: 100MB 类似,只是发生在压缩时。 |
100 |
如果是 online compaction,资源充足时可以开大些,比如 1GB |
并发参数
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| write.tasks | writer 的并发,每个 writer 顺序写 1~N 个 buckets | 4 |
增加并发对小文件个数没影响 |
| write.bucket_assign.tasks | bucket assigner 的并发 | 默认并发 | 增加并发同时增加了并发写的 bucekt 数,也就变相增加了小文件(小 bucket) 数 |
| write.index_bootstrap.tasks | Index bootstrap 算子的并发,增加并发可以加快 bootstrap 阶段的效率,bootstrap 阶段会阻塞 checkpoint,因此需要设置多一些的 checkpoint 失败容忍次数 | 默认并发 | 只在 index.bootstrap.enabled 为 true 时生效 |
| read.tasks | 读算子的并发(batch 和 stream) | 4 |
|
| compaction.tasks | online compaction 算子的并发 | 4 |
online compaction 比较耗费资源,建议走 offline compaction |
压缩参数
Note: 此为在线压缩的参数。
Note: 通过关闭 compaction.async.enabled 参数关闭在线压缩执行,但是调度compaction.schedule.enabled 仍然建议开启,之后通过离线压缩直接执行 在线压缩任务 阶段性调度的压缩 plan。
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| compaction.schedule.enabled | 是否阶段性生成压缩 plan | true | 建议开启,即使compaction.async.enabled 关闭的情况下 |
| compaction.async.enabled | 是否开启异步压缩 | true | 通过关闭此参数关闭在线压缩 |
| compaction.tasks | 压缩 task 并发 | 4 | |
| compaction.trigger.strategy | 压缩策略 | num_commits | 支持四种策略:num_commits、time_elapsed、num_and_time、 num_or_time |
| compaction.delta_commits | 默认策略,5 个 commits 压缩一次 | 5 | |
| compaction.delta_seconds | 3600 | ||
| compaction.max_memory | 压缩去重的 hash map 可用内存 | 100(MB) | 资源够用的话建议调整到 1GB |
| compaction.target_io | 每个压缩 plan 的 IO 上限,默认 5GB | 500(GB) |
文件大小
Note: 目前只有 log 文件的写入大小可以做到精确控制,parquet 文件大小按照估算值。
文件参数控制了文件的大小,目前支持的参数设置如下:
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| hoodie.parquet.max.file.size | 最大可写入的 parquet 文件大小 | 120 1024 1024 默认 120MB(单位 byte) |
超过该大小切新的 file group |
| hoodie.logfile.to.parquet.compression.ratio | log文件大小转 parquet 的比率 | 0.35 | hoodie 统一依据 parquet 大小来评估小文件策略 |
| hoodie.parquet.small.file.limit | 在写入时,hudi 会尝试先追加写已存小文件,该参数设置了小文件的大小阈值,小于该参数的文件被认为是小文件 | 104857600 默认 100MB(单位 byte) |
大于 100MB,小于 120MB 的文件会被忽略,避免写过度放大 |
| hoodie.copyonwrite.record.size.estimate | 预估的 record 大小,hoodie 会依据历史的 commits 动态估算 record 的大小,但是前提是之前有单次写入超过 hoodie.parquet.small.file.limit 大小,在未达到这个大小时会使用这个参数 |
1024 默认 1KB(单位 byte) |
如果作业流量比较小,可以设置下这个参数 |
内存优化
1. MOR
- state backend 换成 rocksdb (默认的 in-memory state-backend 非常吃内存)
- 内存够的话,
compaction.max_memory调大些 (默认是 100MB 可以调到 1GB) - 关注 TM 分配给每个 write task 的内存,保证每个 write task 能够分配到 write.task.max.size 所配置的大小,比如 TM 的内存是 4GB 跑了 2 个
StreamWriteFunction那每个 write function 能分到 2GB,尽量预留一些 buffer,因为网络 buffer,TM 上其他类型 task (比如BucketAssignFunction也会吃些内存) - 需要关注 compaction 的内存变化,
compaction.max_memory控制了每个 compaction task 读 log 时可以利用的内存大小,compaction.tasks控制了 compaction task 的并发
Note: write.task.max.size - write.merge.max_memory 是预留给每个 write task 的内存 buffer
2. COW
- state backend 换成 rocksdb (默认的 in-memory state-backend 非常吃内存)
write.task.max.size和write.merge.max_memory同时调大 (默认是 1GB 和 100MB 可以调到 2GB 和 1GB)- 关注 TM 分配给每个 write task 的内存,保证每个 write task 能够分配到
write.task.max.size所配置的大小,比如 TM 的内存是 4GB 跑了 2 个StreamWriteFunction那每个 write function 能分到 2GB,尽量预留一些 buffer,因为网络 buffer,TM 上其他类型 task (比如BucketAssignFunction也会吃些内存)
Note: write.task.max.size - write.merge.max_memory 是预留给每个 write task 的内存 buffer
类型映射
| Flink SQL Type | Hudi Type | Avro logical type |
|---|---|---|
| CHAR / VARCHAR / STRING | string | |
| BOOLEAN | boolean | |
| BINARY / VARBINARY | bytes | |
| DECIMAL | fixed | decimal |
| TINYINT | int | |
| SMALLINT | int | |
| INT | int | |
| BIGINT | long | |
| FLOAT | float | |
| DOUBLE | double | |
| DATE | int | date |
| TIME | int | time-millis |
| TIMESTAMP | long | timestamp-millis |
| ARRAY | array | |
| MAP (key must be string/char/varchar type) |
map | |
| MULTISET (element must be string/char/varchar type) |
map | |
| ROW | record |
CDC 数据同步
CDC 数据保存了完整的数据库变更,当前可通过两种途径将数据导入 hudi: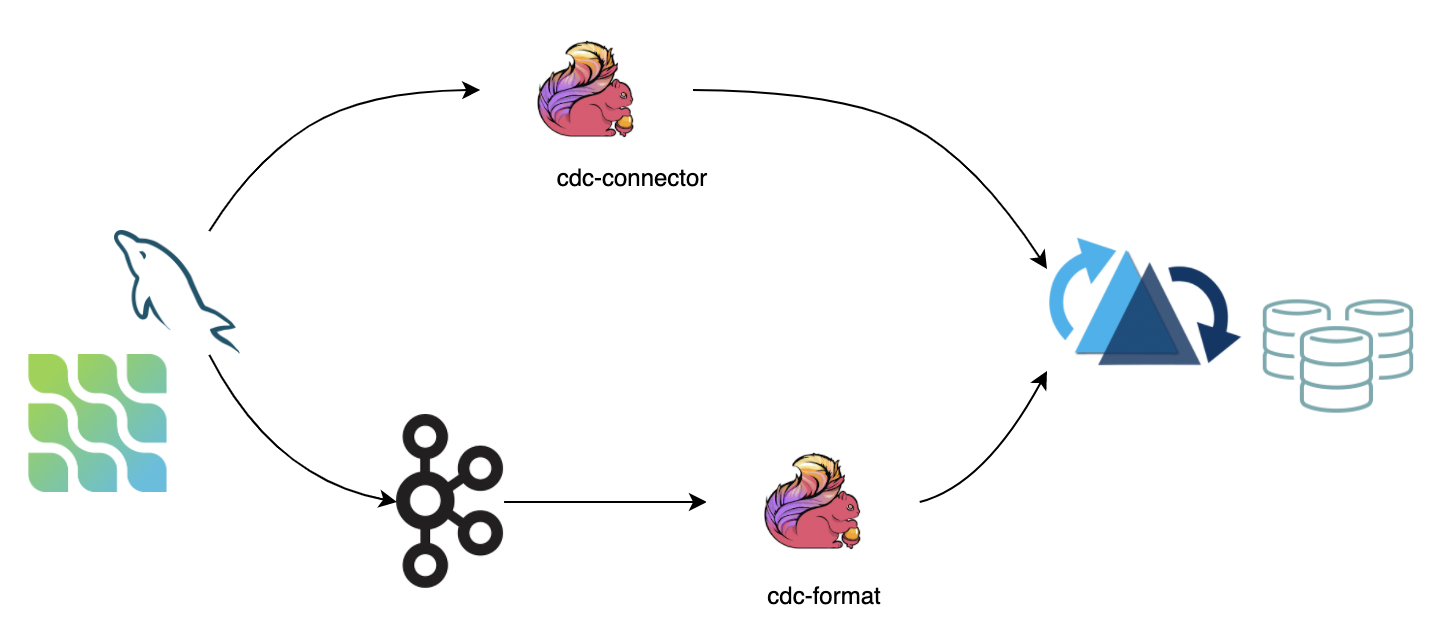
- 第一种:通过 cdc-connector 直接对接 DB 的 binlog 将数据导入 hudi,优点是不依赖消息队列,缺点是对 db server 造成压力
- 第二种:对接 cdc format 消费 kafka 数据导入 hudi,优点是可扩展性强,缺点是依赖 kafka
Note:
- 如果上游数据无法保证顺序,需要指定
write.precombine.field字段 另外当前 ~~**MOR**表处理 DELETE 事件有语义缺陷,最好开启 change log 模式:`changelog.enabled`~~设为 true。0.11 已经修复
离线批量导入
很多小伙伴有存量数据导入的需求,如果存量数据来源于其他数据源,可以使用批量导入功能,快速将存量数据导成 Hoodie 表格式。
Note: 批量导入省去了 avro 的序列化以及数据的 merge 过程,后续不会再有去重操作,数据的唯一性需要自己来保证。
Note: bulk_insert 需要在 Batch Execuiton Mode 下执行更高效,Batch 模式默认会按照 partition path 排序输入消息再写入 Hoodie,避免 file handle 频繁切换导致性能下降。
Note: bulk_insert write task 的并发通过参数 write.tasks 指定,并发的数量会影响到小文件的数量,理论上,bulk_insert write task 的并发数就是划分的 bucket 数,当然每个 bucket 在写到文件大小上限(parquet 120 MB)的时候会 roll over 到新的文件句柄,所以最后:写文件数量 >= bulk_insert write task 数。
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| write.operation | true | upsert | 配置 bulk_insert 开启该功能 |
| write.tasks | false | 4 | bulk_insert 写 task 的并发,最后的文件数 >= write.tasks |
write.bulk_insert.shuffle_input(从 0.11 开始) |
false | true | 是否将数据按照 partition 字段 shuffle 再通过 write task 写入,开启该参数将减少小文件的数量 但是可能有数据倾斜风险 |
write.bulk_insert.sort_input(从 0.11 开始) |
false | true | 是否将数据线按照 partition 字段排序再写入,当一个 write task 写多个 partition,开启可以减少小文件数量 |
| write.sort.memory | 128 | sort 算子的可用 managed memory(单位 MB) |
全量接增量
很多小伙伴有全量数据接增量的需求,如果已经有全量的离线 Hoodie 表,需要接上实时写入,并且保证数据不重复,可以开启 index bootstrap 功能。
Note:如果觉得流程冗长,可以在写入全量数据的时候资源调大直接走流模式写,全量走完接新数据再将资源调小(或者开启限流功能)。
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| index.bootstrap.enabled | true | false | 开启索引加载,会将已存表的最新数据一次性加载到 state 中 |
| index.partition.regex | false | * | 设置正则表达式进行分区筛选,默认为加载全部分区 |
使用流程
CREATE TABLE创建和 Hoodie 表对应的语句,注意 table type 要正确- 设置
index.bootstrap.enabled= true开启索引加载功能 flink conf 中设置 checkpoint 失败容忍 ~~`execution.checkpointing.tolerable-failed-checkpoints`= n(取决于checkpoint 调度次数)~~等待第一次 checkpoint 成功,表示索引加载完成索引加载完成后可以退出并保存 savepoint (也可以直接用 externalized checkpoint)- 重启任务将
index.bootstrap.enabled关闭,参数配置到合适的大小,如果
RowDataToHoodieFunction 和 BootstrapFunction 并发不同,可以重启避免 shuffle
Note:
索引加载是阻塞式,所以在索引加载过程中 checkpoint 无法完成索引加载由数据流触发,需要确保每个 partition 都至少有1条数据,即上游 source 有数据进来- 索引加载为并发加载,根据数据量大小加载时间不同,可以在log中搜索
finish loading the index under partition 和 Load records from file 日志来观察索引加载的进
第一次checkpoint成功就表示索引已经加载完成,后续从 checkpoint 恢复时无需再次加载索引
Note:在最新的 master 和 0.9 cherry pick 分支 以上划横线的部分已经不再需要了。
Changelog 模式
生产上不少同学希望 Hoodie 保留消息的所有变更(I/-U/U/D),之后接上 Flink 引擎的有状态计算实现全链路近实时数仓生产(增量计算),Hoodie 的 MOR 表通过行存原生支持保留消息的所有变更(format 层面的集成),通过流读 MOR 表可以消费到所有的变更记录。
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| changelog.enabled | false | false | 默认是关闭状态,即 UPSERT 语义,所有的消息仅保证最后一条合并消息,中间的变更可能会被 merge 掉;改成 true 支持消费所有变更。 |
批(快照)读仍然会合并所有的中间结果,不管 format 是否已存储中间状态。
开启 changelog.enabled 参数后,中间的变更也只是 Best Effort: 异步的压缩任务会将中间变更合并成 1 条,所以如果流读消费不够及时,被压缩后只能读到最后一条记录。当然,通过调整压缩的 buffer 时间可以预留一定的时间 buffer 给 reader,比如调整压缩的两个参数:compaction.delta_commits:5 和compaction.delta_seconds: 3600。
Note:
Changelog 模式开启流读的话,要在 sql-client 里面设置set sql-client.execution.result-mode=tableau; 或者set sql-client.execution.result-mode=changelog;
(参考:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sqlclient/#running-sql-queries),否则中间结果在读的时候会被直接合并。
流读 changelog
Note: 仅在 0.10.0 支持
Note: 本 feature 为实验性,处在快速迭代期,如有疑惑或者希望改进的点欢迎随时反馈 ~
开启 changelog 模式后,hudi 会保留一段时间的 changelog 供下游 consumer 消费,我们可以通过流读 ODS 层 changelog 接上 ETL 逻辑写入到 DWD 层,如下图的 pipeline: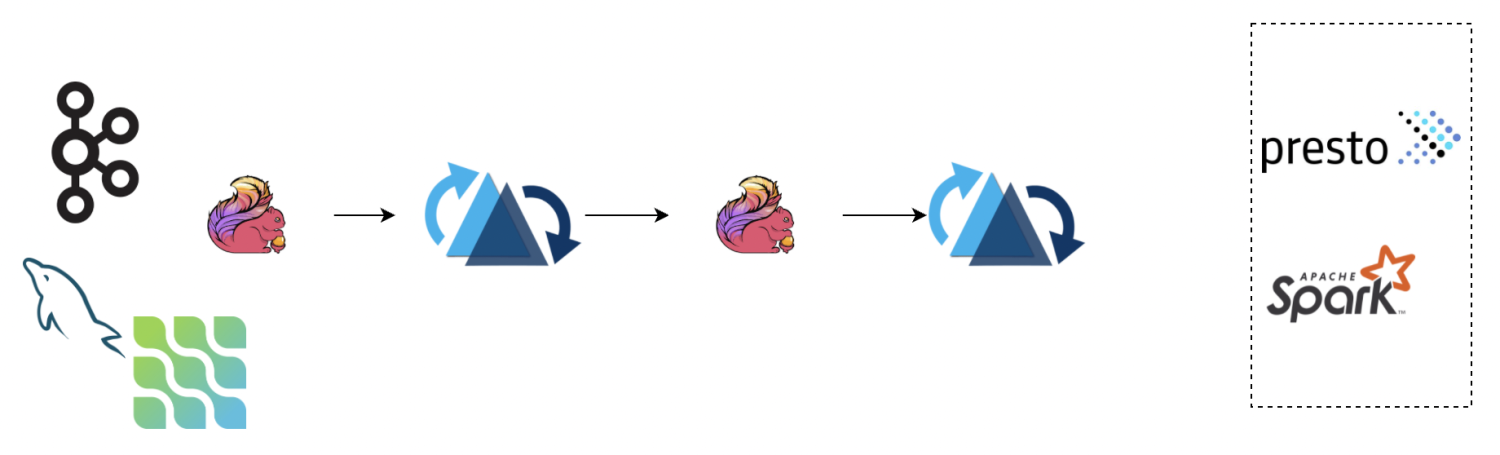
流读的时候我们要注意 changelog 有可能会被 compaction 合并掉,中间记录会消除,可能会影响计算结果,以下属性需要关注:
参考 流读 部分的注意事项
Append 模式
Note: 从 0.10 开始支持
对于 INSERT 模式
- MOR 默认会 apply 小文件策略: 会追加写 avro log 文件
- COW 每次直接写新的 parquet 文件,没有小文件策略
Hudi 支持丰富的 Clustering 策略,优化 INSERT 模式下的小文件问题:
Inline Clustering
Note: 只有 Copy On Write 表支持该模式
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| write.insert.cluster | false | false | 是否在写入时合并小文件,COW 表默认 insert 写不合并小文件,开启该参数后,每次写入会优先合并之前的小文件(不会去重),吞吐会受影响 |
Async Clustering
Note: 从 0.12 开始支持
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| clustering.schedule.enabled | false | false | 是否在写入时定时异步调度 clustering plan,默认关闭 |
| clustering.delta_commits | false | 4 | 调度 clsutering plan 的间隔 commits, clustering.schedule.enabled 为 true 时生效 |
| clustering.async.enabled | false | false | 是否异步执行 clustering plan,默认关闭 |
| clustering.tasks |
false | 4 | Clustering task 执行并发 |
| clustering.plan.strategy.target.file.max.bytes |
false | 1024 1024 1024 |
Clustering 单文件目标大小,默认 1GB |
| clustering.plan.strategy.small.file.limit | false | 600 | 小于该大小的文件才会参与 clustering |
| clustering.plan.strategy.sort.columns | false | N/A | 支持指定特殊的排序字段 |
| clustering.plan.partition.filter.mode | false | NONE | 支持 - NONE:不做限制 - RECENT_DAYS:按时间(天)回溯 - SELECTED_PARTITIONS:指定固定的 partition |
| clustering.plan.strategy.daybased.lookback.partitions | false | 2 | RECENT_DAYS 生效,默认 2 天 |
Clustering Plan Strategy
支持定制化的 clustering 策略
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| clustering.plan.partition.filter.mode | false | NONE | 支持 - NONE:不做限制 - RECENT_DAYS:按时间(天)回溯 - SELECTED_PARTITIONS:指定固定的 partition |
| clustering.plan.strategy.daybased.lookback.partitions | false | 2 | RECENT_DAYS 生效,默认 2 天 |
| clustering.plan.strategy.cluster.begin.partition | false | N/A | SELECTED_PARTITIONS 生效, 指定开始 partition(inclusive) |
| clustering.plan.strategy.cluster.end.partition |
false | N/A | SELECTED_PARTITIONS 生效, 指定结束 partition(incluseve) |
| clustering.plan.strategy.partition.regex.pattern� | false | N/A | 正则表达式过滤 partitions |
| clustering.plan.strategy.partition.selected � |
false | N/A | 显示指定目标 partitions,支持逗号 , 分割多个 partition |
Bucket 索引
Note: 从 0.11 开始支持
默认的 flink 流式写入使用 state 存储索引信息:primary key 到 fileId 的映射关系。当数据量比较大的时候,state的存储开销可能成为瓶颈,bucket 索引通过固定的 hash 策略,将相同 key 的数据分配到同一个 fileGroup 中,避免了索引的存储和查询开销。
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| index.type | false | FLINK_STATE | 设置 BUCKET 开启 Bucket 索引功能 |
| hoodie.bucket.index.hash.field | false | 主键 | 可以设置成主键的子集 |
| hoodie.bucket.index.num.buckets | false | 4 | 默认每个 partition 的 bucket 数,当前设置后则不可再变更。 |
和 state 索引的对比:
- bucket index 没有 state 的存储计算开销,性能较好
- bucket index 无法扩 buckets,state index 则可以依据文件的大小动态扩容
- bucket index 不支持跨 partition 的变更(如果输入是 cdc 流则没有这个限制),state index 没有限制
限流
有不少小伙伴将全量数据(百亿数量级) 和增量先同步到 kafka,再通过 flink 流式消费的方式将库表数据直接导成 hoodie 表,因为直接消费全量部分数据:量大(吞吐高)、乱序严重(写入的 partition 随机),会导致写入性能退化,出现吞吐毛刺,这时候可以开启限速参数,保证流量平稳写入。
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| write.rate.limit | false | 0 | 默认关闭限速 |
流读
当前表默认是快照读取,即读取最新的全量快照数据并一次性返回。通过参数 read.streaming.enabled 参数开启流读模式,通过 read.start-commit 参数指定起始消费位置,支持指定 earliest 从最早消费。
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| read.streaming.enabled | false | false | 设置 true 开启流读模式 |
| read.start-commit | false | 最新 commit | 指定 ‘yyyyMMddHHmmss’ 格式的起始 commit(闭区间) |
| read.streaming.skip_compaction | false | false | 0.11 开始,以上两个问题已经通过保留 compaction 的 instant time 修复 |
| clean.retain_commits | false | 10 | cleaner 最多保留的历史 commits 数,大于此数量的历史 commits 会被清理掉,changelog 模式下,这个参数可以控制 changelog 的保留时间,例如 checkpoint 周期为 5 分钟一次,默认最少保留 50 分钟的时间。 |
Note: 当参数 read.streaming.skip_compaction 打开并且 streaming reader 消费落后于clean.retain_commits 数时,流读可能会丢失数据。从 0.11 开始,compaction 不会再变更 record 的 instant time,因此理论上数据不会再重复消费,但是还是会重复读取并丢弃,因此额外的开销还是无法避免,对性能有要求的同学还是可以开启此参数。
增量读取
Note: 从 0.10.0 开始支持
有的小伙伴有增量读取 batch 数据的需求,增量读取包含三种场景:
- Stream 增量消费,通过参数
read.start-commit指定起始消费位置; - Batch 增量消费,通过参数
read.start-commit指定起始消费位置,通过参数read.end-commit指定结束消费位置,区间为闭区间,即包含起始、结束的 commit - TimeTravel:Batch 消费某个时间点的数据:通过参数
read.end-commit指定结束消费位置即可(由于起始位置默认从最新,所以无需重复声明)
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| read.start-commit | false | 默认从最新 commit | 支持 earliest 从最早消费 |
| read.end-commit | false | 默认到最新 commit |
Hive 同步
1. 打包
先在 $HUDI_HOME 目录下执行命令 mvn clean install -DskipTests,然后进入 packaging/hudi-flink-bundle 目录,按照如下操作打 bundle jar:
打包 bundle jar
hudi-flink-bundle_2.11 module pom.xml 默认将 Hive 相关的依赖 scope 设置为 provided,如果想打入 Hive 的依赖,需要显示指定 profile 为 flink-bundle-shade-hive 。执行以下命令打入 Hive 依赖:
mvn install -DskipTests -Drat.skip=true -Pflink-bundle-shade-hive2# 如果是 hive3 需要使用 profile -Pflink-bundle-shade-hive3# 如果是 hive1 需要使用 profile -Pflink-bundle-shade-hive1#注意1:hive1.x现在只能实现同步metadata到hive,而无法使用hive查询,如需查询可使用spark查询hive外表的方法查询。#注意2: 使用-Pflink-bundle-shade-hive x,需要修改profile中hive的版本为集群对应版本(只需修改profile里的hive版本)。修改位置为packaging/hudi-flink-bundle/pom.xml最下面的对应profile段,找到后修改profile中的hive版本为对应版本即可。
指定 flink 版本
0.11.0 默认的 Flink 适配版本为 Flink 1.14.x,如果想适配 Flink 1.13.x,打包时需加上 profile-Pflink1.13
2. Hive 环境准备
权限端口配置
Flink Client远程连接Hive的时候,要求Hive的 Hive-metastore 和 HiveServer2 两个服务都开启, 且需要记住端口号:
开启的命令: 在hive目录下执行:
// 按照需求选择合适的方式重启nohup hive --service metastore &nohup hive --service hiveserver2 &
在 Hive 服务器导入 Hudi 包
在 Hive 服务器下创建 auxlib/ 文件夹,并把hudi install后packaging/hudi-hadoop-mr-bundle/target目录下的hudi-hadoop-mr-bundle-0.x.x-SNAPSHOT.jar 放入其中,否则会报
FAILED: SemanticException Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
解法:
1.将 hudi-hadoop-mr-bundle-0.9.0-SNAPSHOT.jar 添加到hive 目录下,例如:
cp /opt/software/hudi-hadoop-mr-bundle-0.9.0-SNAPSHOT.jar $HIVE_HOME/auxlib/
2.重启 Hive:
// 按照需求选择合适的方式重启
nohup hive --service metastore &
nohup hive --service hiveservice2 &
3. Hive 配置模版
Flink hive sync 现在支持两种 hive sync mode, 分别是 hms 和 jdbc 模式。 其中 hms 只需要配置 metastore uris;而 jdbc 模式需要同时配置 jdbc 属性 和 metastore uris,具体配置模版如下:
## hms mode 配置
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' = 'hdfs://xxx.xxx.xxx.xxx:9000/t1',
'table.type'='COPY_ON_WRITE', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.table'='${hive_table}', -- required, hive 新建的表名
'hive_sync.db'='${hive_db}', -- required, hive 新建的数据库名
'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc
'hive_sync.metastore.uris' = 'thrift://ip:9083' -- required, metastore的端口
);
4. Hive 查询
请参考文档:《Hive On Hudi》
5. 与其他包冲突
当flink/lib下有~~flink-sql-connector-hive-xxx.jar~~时,会出现hive包冲突,解决方法是在install时,另外再指定一个profile:~~-Pinclude-flink-sql-connector-hive~~,同时删除掉flink/lib下的~~flink-sql-connector-hive-xxx.jar~~
Note: 该问题从 0.10 版本已经解决。
Presto 查询
用到的各软件版本:
hudi-0.9.0
hive-2.3.8
presto-server-0.2445 //下载地址 https://repo1.maven.org/maven2/com/facebook/presto/presto-server/
presto-cli-0.254.1-executable.jar //下载地址:https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.254.1/presto-cli-0.254.1-executable.jar
Prestodb 是通过读取 hive metastore 来读取hudi的数据的,所以需要先将 hudi 的数据同步到 hive 上,同步的流程参照 hive sync 功能。
1. 将hudi数据同步到 hive
参考 hive sync过程,完成同步。
2. 配置presto
- 配置hive的catalog
- 其他配置参考 https://www.jianshu.com/p/520722be209e
在 .../presto-server-0.2445/etc/catalog/hive.properties 配置hive catalog。
connector.name=hive-hadoop2
hive.metastore.uri=thrift://xxx.xxx.xxx.xxx:9083
hive.config.resources=.../hadoop-2.10.1/etc/hadoop/core-site.xml,.../hadoop-2.10.1/etc/hadoop/hdfs-site.xml
3. 开启查询
通过 presto-cli 连接 hive metastore 开启查询。 presto-cli 的设置参考 presto-cli 配置:
./presto --server xxx.xxx.xxx.xxx:9999 --catalog hive --schema default
通常 hive sync 后使用的是默认的schema,进入后, 通过 show schemas 查看有哪几个数据库,然后选择hive sync 的数据库:
Note:
- presto-server-0.2445 版本较低,在查 MOR 表的 rt 表时,会出现包冲突,正在fix中
- prestodb 版本小于 0.233 版本时,因为没有引入hudi解析的包,需要手动的引入
hudi-presto-bundlejar 到{presto_install_dir}/plugin/hive-hadoop2/中。大于该版本的 presto,hive-hadoop2 目录已经集成了 hudi-common.x.x.x.jar 和 hudi-hadoop-mr.x.x.x.jar,所以不需要自己引入。
Note:parquet_use_column_names
参数说明:对PARQUET文件,根据列名对应查找数据,不必保持表列名顺序与PARQUET文件一致。
1. SESSION级别【先以这个测试查询】:
set session hive.parquet_use_column_names=true;
2. 文件级别:
PRESTO的配置文件 hive.properties 新增下
hive.parquet.use-column-names=true
重启cordinator/worker生效
离线 Compaction
MOR 表的 compaction 默认是自动打开的,策略是 5 个 commits 执行一次压缩。 因为压缩操作比较耗费内存,和写流程放在同一个 pipeline,在数据量比较大的时候(10w+/s qps),容易干扰写流程,此时采用离线定时任务的方式执行 compaction 任务更稳定。
设置参数 compaction.async.enabled 为 false,关闭在线 compaction。另外参数compaction.schedule.enabled 仍然保持开启,由写任务阶段性触发压缩 plan。
一个 compaction 的任务的执行包括两部分:1. schedule 压缩 plan 2. 执行对应的压缩 plan
第一步 schedule plan 的过程推荐由写任务定时触发,写参数 compaction.schedule.enabled 默认开启。
离线 compaction 需要手动执行 Java 程序,程序入口:
hudi-flink-bundle_2.11-0.9.0-SNAPSHOT.jarorg.apache.hudi.sink.compact.HoodieFlinkCompactor
// 命令行的方式
./bin/flink run -c org.apache.hudi.sink.compact.HoodieFlinkCompactor lib/hudi-flink-bundle_2.11-0.9.0.jar --path hdfs://xxx:9000/table
参数配置
| 参数名 | required | 默认值 | 备注 |
|---|---|---|---|
| —path | true | — | 目标表的路径 |
| —compaction-tasks | false | -1 | 压缩 task 的并发,默认是待压缩 file group 的数量 |
| —compaction-max-memory | false | 100 (单位 MB) | 压缩时 log 数据的索引 map,默认 100MB,内存足够可以开大些 |
| —schedule | false | false | 是否要执行 schedule compaction 的操作,当写流程还在持续写入表数据的时候,开启这个参数有丢失查询数据的风险,所以开启该参数一定要保证当前没有任务往表里写数据, 写任务的 compaction plan 默认是一直 schedule 的,除非手动关闭(默认 5 个 commits 一次压缩) |
| —seq � |
false | LIFO | 执行压缩任务的顺序,默认是从最新的压缩 plan 开始执行,可选值: LIFO: 从最新的 plan 开始执行; FIFO: 从最老的 plan 开始执行 |
| —service | false | false | 是否开启 service 模式,service 模式会打开常驻进程,一直监听压缩任务并提交到集群执行(从 0.11 开始执行) |
| —min-compaction-interval-seconds | false | 600 (单位 秒) | service 模式下的执行间隔,默认 10 分钟 |
离线 Clustering
异步的 clustering 相对于 online 的 async clustering 资源隔离,从而更加稳定。
设置参数 clustering.async.enabled 为 false,关闭在线 clustering。另外参数clustering.schedule.enabled 仍然保持开启,由写任务阶段性触发 clustering plan。
一个 clustering 的任务的执行包括两部分:1. schedule plan 2. 执行对应的 plan
第一步 schedule plan 的过程推荐由写任务定时触发,写参数 clustering.schedule.enabled 默认开启。
离线 clustering 需要手动执行 Java 程序,程序入口:
${bundle_jar_name}.jarorg.apache.hudi.sink.clustering.HoodieFlinkClusteringJob
// 命令行的方式
./bin/flink run -c org.apache.hudi.sink.clustering.HoodieFlinkClusteringJob lib/${bundle_jar_name}.jar --path ${table_path}
参数配置
| 参数名 | required | 默认值 | 备注 |
|---|---|---|---|
| —path | true | — | 目标表的路径 |
| —clustering-tasks | false | -1 | Clustering task 的并发,默认是待压缩 file group 的数量 |
| —schedule | false | false | 是否要执行 schedule clustering plan 的操作,当写流程还在持续写入表数据的时候,开启这个参数有丢失查询数据的风险,所以开启该参数一定要保证当前没有任务往表里写数据, 写任务的 clustering plan 默认是一直 schedule 的,除非手动关闭(默认 4 个 commits 一次 clustering) |
| —seq � |
false | FIFO | 执行压缩任务的顺序,默认是从最老的 clustering plan 开始执行,可选值: LIFO: 从最新的 plan 开始执行; FIFO: 从最老的 plan 开始执行 |
| —target-file-max-bytes | false | 1024 1024 1024 |
最大目标文件,默认 1GB |
| —small-file-limit | false | 600 | 小于该大小的文件会参与 clustering,默认 600MB |
| —sort-columns | false | N/A | Clustering 可选排序列 |
| —service | false | false | 是否开启 service 模式,service 模式会打开常驻进程,一直监听压缩任务并提交到集群执行(从 0.11 开始执行) |
| —min-compaction-interval-seconds | false | 600 (单位 秒) | service 模式下的执行间隔,默认 10 分钟 |
基础问题
1. 存储一直看不到数据
如果是 streaming 写,请确保开启 checkpoint,Flink 的 writer 有 3 种刷数据到磁盘的策略:
- 当某个 bucket 在内存积攒到一定大小 (可配,默认 64MB)
- 当总的 buffer 大小积攒到一定大小(可配,默认 1GB)
- 当 checkpoint 触发,将内存里的数据全部 flush 出去
2. 数据有重复
如果您是 COW 写,需要开启参数 write.insert.drop.duplicates,COW 写每个 bucket 的第一个文件默认是不去重的,只有增量的数据会去重,全局去重需要开启该参数;MOR 写不需要开启任何参数,定义好 primary key 后默认全局去重。
Note: 从 0.10 版本开始,该属性改名 write.precombine 并且默认为 true。
如果需要多 partition 去重,需要开启参数: index.global.enabled 为 true。
Note: 从 0.10 版本开始,该属性默认为 true。
索引 index 是判断数据重复的核心数据结构,index.state.ttl 设置了索引保存的时间,默认为 1.5 天,对于长时间周期的更新,比如更新一个月前的数据,需要将 index.state.ttl 调大(单位天),设置小于 0 代表永久保存。
Note: 从 0.10 版本开始,该属性默认为 0。
3. Merge On Read 写只有 log 文件
Merge On Read 默认开启了异步的 compaction,策略是 5 个 commits 压缩一次,当条件满足参会触发压缩任务,另外,压缩本身因为耗费资源,所以不一定能跟上写入效率,可能会有滞后。
可以先观察 log,搜索 compaction 关键词,看是否有 compact 任务调度:After filtering, Nothing to compact for 关键词说明本次 compaction strategy 是不做压缩。
4. 如何开启 Checkpoint
集群级别
flink-conf.yaml 设置如下参数:
### set the interval as 5 minutes
execution.checkpointing.interval: 300000
state.backend: rocksdb
### state.backend: rocksdb
state.backend.incremental: true
state.checkpoints.dir: xxx
state.savepoints.dir: xxx
PerJob 级别
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new EmbeddedRocksDBStateBackend());
核心原理
数据去重
Hoodie 的数据去重分两步:1. 写入前攒 buffer 阶段;2. 写入过程中。
Hoodie 去重的核心接口有两个:HoodieRecordPayload#preCombine 和 HoodieRecordPayload#combineAndGetUpdateValue,HoodieRecordPayload#preCombine 对应攒 buffer 阶段的去重,HoodieRecordPayload#combineAndGetUpdateValue 对应写入过程中的去重。
消息版本新旧
相同 record key (主键)的数据通过write.precombine.field 指定的字段来判断哪个更新,即 precombine 字段更大的 record 更新,如果是相等的 precombine 字段,则后来的数据更新。
Note: 从 0.10 版本开始,write.precombine.field 字段为可选,如果没有指定,会看 schema 中是否有 ts 字段,如果有,ts 字段被选为 precombine 字段;如果没有指定,schema 中也没有 ts 字段,则为处理顺序:后来的消息默认较新。
攒消息阶段的去重
Hoodie 将 buffer 消息发给 write handle 之前可以执行一次去重操作,通过HoodieRecordPayload#preCombine 接口,保留 precombine 字段较大的消息,此操作为纯内存的计算,在同一个 write task 中为单并发执行。
Note: write.precombine 选项控制了攒消息的去重
写 parquet 增量消息的去重
了解 Hoodie 写入流程的小伙伴知道,Hoodie 每写一个 parquet 都会有 base + 增量 merge 的过程,增量的消息会先放到一个 spillable map 的数据结构构建内存 index,这里的增量数据如果没有提前去重,那么同 key 的后来消息会直接覆盖先来的消息。
Writer 接着扫 base 文件,过程中会不断查看内存 index 是否有同 key 的新消息,如果有,会走 HoodieRecordPayload#combineAndGetUpdateValue 接口判断保留哪个消息。
Note: MOR 表的 compaction 阶段和 COW 表的写入流程都会有 parquet 增量消息去重的逻辑。
跨 partition 的消息去重
默认情况下,不同的 partition 的消息是不去重的,即相同的 key 消息,如果新消息换了 partition,那么老的 partiiton 消息仍然保留。
开启 index.global.enabled 选项开启跨 partition 去重,原理是先往老的 partiton 发一条删除消息,再写新 partition。
问题排查

若有收获,就点个赞吧
0 人点赞
