数据库操作:
查看所有数据库:
show dbs
创建&切换数据库:
只有数据库有集合之后,创建的数据库才会持久化到磁盘,不然会在内存中
use 数据库名称
数据库删除:
用来删除持久化的数据库
db.dropDatabase()
集合操作:
显示创建:
创建一个集合
db.createCollection(集合名)
命名规范:
- 集合的命名规范: 集合名不能是空字符串””。
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以”system.”开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除 非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
隐式创建:
当文档插入的时候集合不存在,将会自动创建集合,该过程为隐式创建
查看集合:
查看当前数据库中的所有集合
show collections 查看集合
集合删除:
删除指定名称的集合, 删除成功返回 true,否则返回 false。
db.集合名.drop()
文档操作:
保存:
使用 save() 或 insert() 或 insertOne() 命令将JSON数据保存到集合中
db.集合名.insert(JSON) 保存单个或则批量db.集合名.save(JSON) 单个保存方法1db.集合名.insertOne(JSON) 单个保存方法2
例如对 userInfo 集合保存一个文档:
db.userInfo.save({"articleid": "100000","content": "今天天气真好,阳光明媚","userid": "1001","nickname": "Rose","createdatetime": new Date(),"likenum": NumberInt(10),"state": null})
提示:
- comment集合如果不存在,则会隐式创建
- mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字)
- 插入当前日期使用 new Date()
- 插入的数据没有指定 _id ,会自动生成 _id 主键值,主键值支持除数组外的任意数据类型
- 如果某字段没值,可以赋值为null,或不写该字段
- 可通过 Objectid(“生成值”).getTimestamp() 返回对象ID创建的时间
- 将数据本身保存为主键,被称为复合主键,如果要保存相同的数据,复合主键的字段顺序要不同
批量保存:
使用 insertMany 或 insert 批量插入文档
db.集合名.insertMany(JSON集合)db.集合名.insert(JSON集合)
例如对comment集合批量保存5条数据:
db.comment.insertMany([{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"},{"address":"bejjing","phone":112233}]);
提示:
- 插入时指定了 _id ,则主键就是该值
- 如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。 因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理
例如批量插入两条ID重复的数据,最终只会保存前三条:
try{db.comment.insertMany([{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},{"_id":"3","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。",userid:"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}]);}catch(e){print (e);}
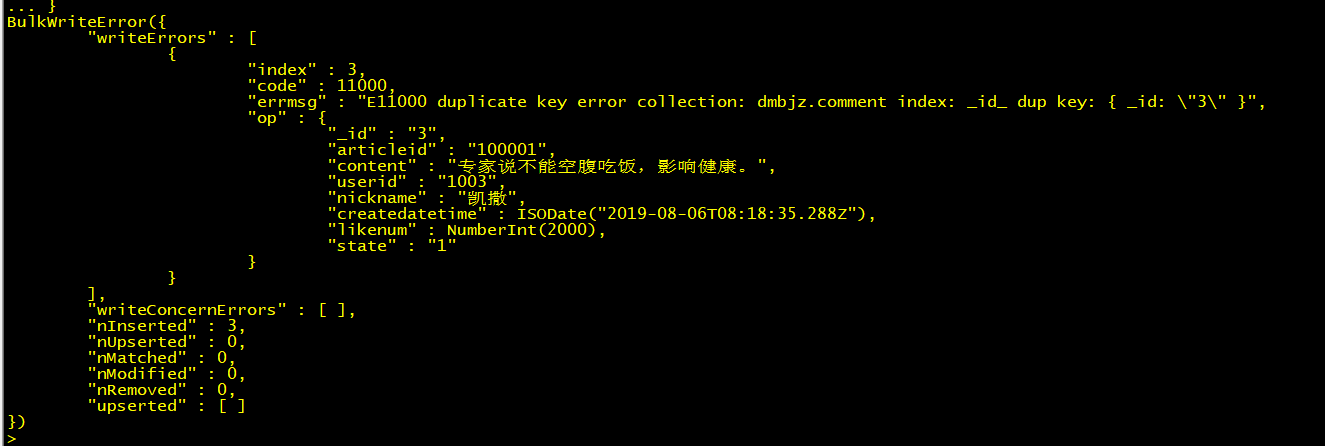
捕捉到ID重复插入异常信息
查询:
查询文档:
指定显示字段中除 _id 可以任意填写外,其他参数的值只能为同一个值,值为1时为显示,值为0时意为屏蔽,_id 字段默认显示,末尾添加 pretty() 可进行格式化
当数据为复合主键时,可通过筛选复合主键的字段类型进行查询
使用 find 可以返回一个变量,使用变量默认只会返回前20条数据,只有指定具体下标才会返回具体数据;遍历完游标中的所有文档或10分钟无操作,游标将自动关闭,但可以使用 noCursotTimeout()函数保证一直有效,缺点是需要调用close()方法进行手动关闭
db.集合名.find(JSON条件,指定结果显示的JSON字段是否出现) 查询符合条件的所有记录db.集合名.findOne(JSON条件,指定结果显示的JSON字段是否出现) 查询符合条件的第一条记录db.集合名.find().limit(数量) 相当于MySQL里的Limit
查询所有数据:
格式化显示所有数据: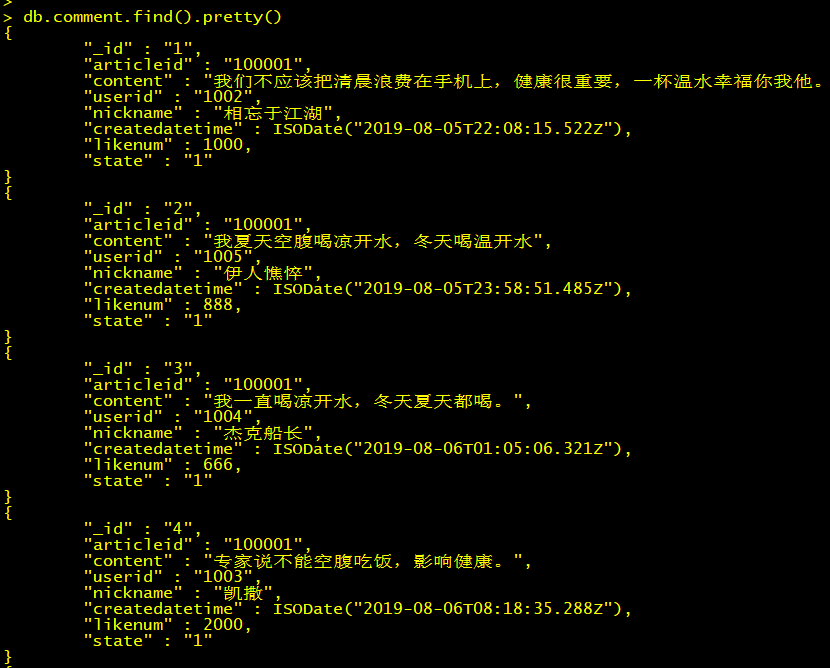
查询 userid为1003的数据:
查询 userid为1003,且只显示 content 字段:
查询 userid为1003,显示 content 和 nickname字段,隐藏 _id字段:
如果有显示和屏蔽同时出现的情况,MongoDB将报错:
读取复合主键中类型为 savings 的数据:
返回变量并指定下标:
使用下标返回具体数据
关闭时间限制需要手动关闭游标
总数查询:
与MySQL中的 count() 含义一致,返回符合条件的文档总数,没有筛选条件时将从 Matedata提供筛选结果,缺点是在分布式系统中返回的文档数量可能不准确,使用count()需要添加查询条件
*和 limit 、skip 搭配使用时默认参数 applySkipLimit,值是false,会忽略 limit 和 skip 的效果,需要改为true才能正常显示
db.集合名.count(JSON或JSON条件)db.集合名.limit().skip().count(true)
例如统计集合中文档的所有数量:
db.comment.count()
例如统计集合中 likenum 大于900 的数量:
db.comment.count({likenum:{$gt:900}})
例如统计集合中 state为1的文档数量:
db.comment.count({state:"1"})
与 limit 和 skip 搭配使用要指定为true才能正确返回:
不添加Ture将会忽略 limit 和 skip
分页查询:
使用 limit() 方法来读取指定数量的数据,但 limit(0) 相当于没有limit
使用 skip() 方法来跳过指定数量的数据
db.集合名.find().skip(NUMBER).limit(NUMBER)
例如每页显示5条数据的分页语句:
db.comment.find().skip(0).limit(5) 第一页db.comment.find().skip(5).limit(5) 第二页db.comment.find().skip(10).limit(5) 第三页
排序查询:
使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关。
db.集合名.find().sort(JSON)
例如对 likenum 进行降序,对 userid 进行升序,且只显示三个字段:
db.comment.find({},{likenum:1,userid:1,_id:1}).sort({likenum:-1,userid:1})
比较查询:
$ne会筛选出不包含查询字段的文档,需要配合字段查询 $exists 进行限制
db.集合名.find({ 字段名 : { $gt: value }}) 大于: field > valuedb.集合名.find({ 字段名 : { $lt: value }}) 小于: field < valuedb.集合名.find({ 字段名 : { $gte: value }}) 大于等于: field >= valuedb.集合名.find({ 字段名 : { $lte: value }}) 小于等于: field <= valuedb.集合名.find({ 字段名 : { $ne: value }}) 不等于: field != valuedb.集合名.find({ 字段名 : { $ge: value }}) 等于方法1: field == valuedb.集合名.find({ 字段名 : { $eq: value }}) 等于方法2: field == value
例如查询 likenum 大于 700 的文档:
db.comment.find({likenum:{$gt:NumberInt(700)}}) 查询方法1db.comment.find({likenum:{$gt:700}}) 查询方法2
查询 userid 小于等于 1003 的文档:
db.comment.find({ userid: {$lte:"1003"} })
当某个字段在数据中不存在的时候使用 $ne 进行筛选,将会查出所有的数据:
db.comment.find({aaaa:{$ne:"111"}}) 指定一个 comment 文档中不存在的字段
包含查询:
与MySQL中关键字 in 的含义一致
db.集合名.find({字段名:{$in:["参数1","参数2"]}}) 查询字段名为参数1、参数2的文档db.集合名.find({字段名:{$nin:["参数1","参数2"]}}) 查询字段名不为参数1、参数2的文档
例如查询 likenum 为 2000 和 3000 的数据:
db.comment.find({likenum:{$in:[2000,3000]}})
条件连接查询:
如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联(相当于SQL的and)
当筛选条件应用在不同字段或相同字段上,可以省略 $and 操作符
$and:[{},{},{}] 且$or:[{},{},{}] 或$nor:[{},{},{}] 不
查询评论集合中likenum大于等于700 并且小于2000的文档:
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})
查询评论集合中userid为1003,或者点赞数小于1000的文档记录:
db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})
查询userid为1003且likenum大于2000的数据(省略 $and):
db.comment.find( { userid:{$eq:"1003"},likenum:{$eq:2000} } )
查询likenum大于2000且小于3000的数据(省略 $and):
db.comment.find( { likenum:{$eq:2000,$lt:3000} } )
查询likenum既不属于2000也不属于3000的数据:
db.comment.find( { $nor:[{likenum:2000},{likenum:3000} ] })
字段限制查询:
使用 $exists 查询文档中是否包含某个字段的数据
db.comment.find({"字段名":{$exists:布尔值}}) 返回是否需要包含该字段的数据
查询包含 address字段的文档数据:
db.comment.find({"address":{$exists:true}})
筛选出必须要有aaaa字段的数据,且值必须不为111:
db.comment.find({aaaa:{$ne:"111",$exists:true}})
字段类型查询:
使用 $field 指定字段类型进行文档数据查询
db.comment.find({"字段名":{$type:数据类型}}) 指定字段名和数据类型进行查询
查询address字段数据类型是string的文档:
db.comment.find({address:{$type:"string"}})
数组查询:
$all 匹配数组字段中包含所有查询值的文档
$elemMatch 匹配数组字段中至少存在一个值满足筛选条件的文档
db.comment.find( {字段名:{$all:["数据1","数据2"...]}} ) 查询数组中包含数据1、数据2的文档db.comment.find( { 字典名:{$all:[ [集合1],[集合2]....]} }) 查询数组中包含组合数组的文档
保存带有数组的文档数据:
db.comment.insert([{name: "jack",balance: 2000,contact: [" 11111111"," Alabama","US"]},{name: "karen",balance: 2500,contact: [["22222222","33333333"],"Beijing","China"]},{name: "lundun",balance: 3000,contact: [["555","666"],["888","999"],"Beijing"]}{name:"karen",contact:[["22222222","33333333"],"Beijing","China",{"primaryEmail":"xxx@gmail.com","secondaryEmail":"yyy@gmail.com"}]},{ "_id" : 1, "grades" : [ 85, 82, 80 ] },{ "_id" : 2, "grades" : [ 88, 90, 92 ] },{ "_id" : 3, "grades" : [ 85, 100, 90 ] }])
查询contact中包含china和Beijing的数据:
db.comment.find( {contact:{$all:["China","Beijing"]}} )
查询contact中包含有22222222和33333333数据的数组文档:
db.comment.find( {contact:{$all:[["22222222","33333333"]] }} )
查询contact中字段范围在1000到2000范围的文档数据:
db.comment.find({contact:{$elemMatch:{$gt:"100",$lt:"2000"}}})
查询contact中大于22小于30的文档数据:
db.comment.find( { contact: { $elemMatch: { $gt: 22, $lt: 30 } } } )
模糊查询:
通过 JS 的正则表达式进行模糊查询,使用 $options指定是否区分大小写
db.集合名.find({字段:/正则表达式/})db.集合名.find({字段/正则表达式/})
例如查询包含“开水”的所有文档:
db.comment.find({content:/开水/})
例如查询以 “研究”开头的文档数据:
db.comment.find({content:/^研究/})
查询用户信息以C或J开头的数据:
db.comment.find({name:{$in:[/^c/,/^j/]}})
查询姓名包含 JAC 且不区分大小写的文档数据:
db.comment.find({name:{$regex:/JAC/,$options:'i'}})
更新:
用于更新文档数据,包含覆盖更新和部分更新,options为额外参数,默认只修改符合条件的第一个数据
由于MongoDB只保证单个文档更新的原子性,当 update 配合 multi 做批量更新时虽然是在单个线程中执行,但执行过程中可能被挂起,挂起期间其他线程也可能处理目标数据,因此数据准确性可能出现误差,如果非常在意安全,多文档更新需要使用事务功能(4.0+版本)进行操作
db.集合名.update(query, update, options) 更新符合条件的第一个文档数据db.集合名.updateOne(query, update, options) 更新符合条件的第一个数据db.集合名.replaceOne(query, update, options) 替换符合条件的第一个数据db.集合名.updateMany(query, update, options) 无需额外参数的批量更新
| 参数 | 类型 | 含义 |
|---|---|---|
| query | document | 查询条件 |
| update | documentor 或者 pipeline | 要修改的值或者管道操作 |
| upsert | boolean | 是否在查询不到结果时创建新文档。默认为false |
| multi | boolean | 是否更新符合条件的所有文档,默认false |
| writeConcern | document | 写问题的文档抛出异常的级别 |
| collation | document | 指定要用于操作的校对规则 |
| arrayFilters | array | 一个筛选文档数组,用于确定要为数组字段上的更新操作修改哪些数组元素 |
| hint | document or string | 指定用于支持查询谓词的索引的文档或字符串。可以采用索引规范文档或索引名称字符串。如果指定的索引不存在,则说明操作错误 |
覆盖修改:
将目标数据修改为指定数据,例如修改 _id为1的记录,文档数据只有点赞记录为1001:
db.comment.update({_id:"1"},{likenum:NumberInt(1001)}) 覆盖修改方法1db.comment.replaceOne({_id:"1"},{likenum:NumberInt(1001)}) 覆盖修改方法2
局部修改:
使用 $set 进行指定字段的局部修改或新增,在现有数值范围以外的位置添加新值,数组字段长度会扩大,扩容且未被赋值的数组成员将会赋值为 null
db.comment.update({_id:"2"},{$set:{likenum:NumberInt(1001)}}) 修改 _id为2的记录,文档数据中点赞记录修改为1001db.comment.update({"name":"lundun"},{$set:{"contact.0":["111","222"]}}) 修改数组中下标为0的字段
批量修改:
使用额外参数 multi 对所有符合条件的数据进行修改,例如修改state为1的数据的nickname为小明:
db.comment.update({state:"1"},{$set:{nickname:"小明"}},{multi:true}) 批量更新方法1db.comment.updateMany({state:"1"},{$set:{nickname:"小明"}}) 批量更新方法2
删除字段:
使用 $unset 删除字段,如果字段不存在将不做任何操作,但如果是数组,只会将对应下标的数据被重置为null
db.集合名.update({条件},{$unset:字段名:""}) 字段名后的字符串是否有值与删除结果并无关系
重命名字段:
使用 $rename 进行字段重命名,如果该字段不存在将不做修改;
原理是先执行 $unset 然后再 $set,因此新名称如果在原数据中存在,将会抹去该名称的数据,然后再进行改名操作。旧字段名和新字段名都无法指向数组元素
db.集合名.update({条件},{$rename:{"旧字段名":"新字段名"}})
将姓名为 jack 的文档中contact重命名为blance:
db.comment.update({name:"jack"},{$rename:{"contact":"blance"}})
字段增减/乘:
使用 $inc 对数字类型的数据进行增减(正数/负数),如果字段不存在将会创建,且值为语句中的值
使用 $mul 进行字段值相乘,如果字段不存在将会创建并赋予0
这两个方法都只能应用于数字字段上
db.comment.updateOne({"_id":"3"},{$inc:{likenum:NumberInt(999)}}) 对 _id为3的文档的 likenum 增加 999db.comment.update({name:"lundun"},{$mul:{"balance":0.5}}) 对name为lundun的文档将balance值乘以0.5
比较减少/增大:
$min 将新值和旧值进行对比,将值更新为最小的那个,$max 为更新成最大的那个值
如果被更新字段和更新类型不一致,将会按照 BSON 数据类型排序规则进行排序比较更新

db.comment.update({name:" lundun"},{$min:{"num2":300}}) 对比num2的值,保存较小的db.comment.update({name:" lundun"},{$max:{"num2":300}}) 对比num2的值,保存较大的
数组更新操作符:
添加:
$addToSet:如果添加值已存在将不会再次添加(不区分大小写),添加多个数据时需要使用$each,否则会被认为成数组
$push:添加一个数组元素,如果添加值已存在将不会再次添加
db.comment.update({name:"karen"},{$addToSet:{字段名:"新数据"}}) 添加一个新字段db.comment.update({name:"karen"},{$addToSet:{字段名:{ $each:["新数据1","新数据2"] } } }) 添加两个新字段数据db.comment.update({name:"karen"},{$push:{字段名:"新数组元素"}}) 添加一个新数组元素db.comment.update({name:"karen"},{$push:{字段名:{ $each:["新数组元素1","新数组元素2"] } } }) 添加多个新数组元素
移除:
$pop:用来删除数组字段中的第一个(值为-1)或最后一个元素(值为1),删除掉数组的最后一个元素,将会留下空数组
$pull:从数组字段中删除特定元素
如果要删除的是一个数组,$pull 则只删除数组中完全匹配的元素 ,包括顺序
如果要删除的是文档,$pull 仅删除数组中具有完全相同字段和值的元素。字段的顺序可以不同
$pullAll:从数组字段中删除特定元素,相当于 $pull + $in,只有与数组中的数据完全匹配才删除
db.comment.update({name:"karen"},{$pull:{字段:{$in:["数据1","数据2"]} }}) 批量删除指定字段中的数据db.comment.update({name:"karen"},{$pullAll:{字段:["数据1","数据2"]}}) 使用pullAll进行批量删除指定字段中的数据db.comment.update({name:"karen"},{$pop:{contact:1}} ) 删除karen用户中的contact字段中的最后一个元素db.comment.update({name:"karen"},{$pull:{contact:{$regex:/hi/}}}) 删除karen用户中包含hi的字段db.comment.update({"name":"karen"},{$pullAll:{contact:[ ["22222222","33333333"] ]}}) 删除karen用户中contact中的内嵌数组数据
全更新:
在数组字段后添加 $[],让指定条件的数组字段内的所有数据进行覆盖更新
db.comment.update( {筛选条件}, {操作:{"数组字段名.$[]":更新值}} )
让 _id为1的文档中的grades集合值全部更新为 [10,200,30] 的数组:
db.comment.update( { _id:1}, {$set:{"grades.$[]": [10,200,30] }} )
其他参数例子:
修改state为100的文档的nickname为小明,如果没有就创建:
db.comment.update({state:"100"},{$set:{nickname:"小明"}},{upsert:true})
删除:
如果要清空集合内的所有数据,传入 {} 即可
db.集合名.remove(JSON或条件,额外参数) 移除所有匹配的数据db.集合名.deleteOne(JSON或条件) 移除匹配的第一条数据db.集合名.deleteMany(JSON条件) 移除匹配的所有数据
例如删除 likenum大于1000的第一条数据:
db.comment.deleteOne({likenum:{$gt:1000}}) 移除方法db.comment.remove({likenum:{$gt:1000}},true) 旧版移除方法
例如删除集合内的所有文档:
db.comment.deleteMany({}) 新版移除方法db.comment.remove({}) 旧版移除方法
例如删除 likenum 大于500的所有数据:
db.comment.deleteMany({likenum:{$gt:500}}) 新版移除方法db.comment.remove({likenum:{$gt:500}}) 旧版移除方法

若有收获,就点个赞吧
0 人点赞
