
Disruptor :
持有 RingBuffer、消费者线程池 Executor、消费者集合 ConsumerRepository 等引用
RingBuffer:
实质基于环形数组的缓存实现,也是创建 sequencer 与定义 WaitStrategy 的入口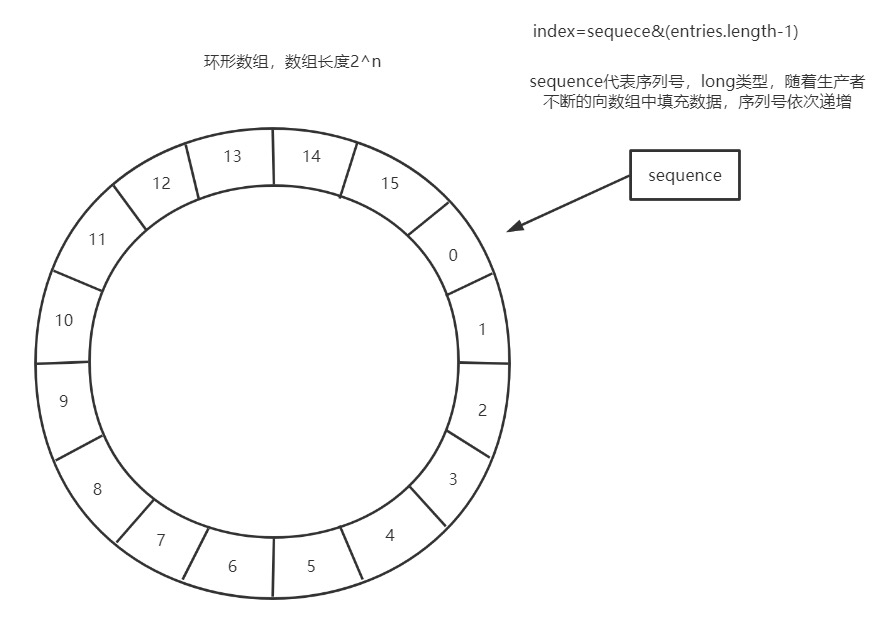
要找到数组中当前序号指向的元素,可以通过 mod 操作:(sequence 序号值) mod 环形数组长度,例如 RingBuffer 为长度为 6,序号值为 20,则当前会取出索引为 2 的数据
Sequence:
可以看做是一个 AtomicLong 原子类用于标识进度,通过顺序递增的序号来编号,管理进行交换的数据(事件),内部解决了不同 Sequence 之间 CPU 缓存伪共享问题
对数据(事件)的处理过程总是沿着序号在环形数组( RingBuffer )中逐个递增处理
一个 Sequence 用于跟踪标识某个特定的事件处理者( RingBuffer / Producer / Consumer )的处理进度
Sequencer:
内部包含 Sequence , 有两个重要实现类 SingleProducerSequencer 与 MultiProducerSequencer
主要实现生产者与消费者之间快速、正确地传递数据的并发算法
SequenceBarrier:
用于保持对 RingBuffer 的 Main Published Sequence ( Producer ) 和 Consumer 之间的平衡关系
还定义了决定 Consumer 是否还有可处理的事件的逻辑
WaitStrategy:
决定一个消费者将如何等待生产者将 Event 置入 Disruptor,主要包括三种实现,通常情况下业务逻辑使用 BlockingWaitStrategy 即可,YieldingWaitStrategy 虽然性能高效但非常占用CPU性能,在高峰期使用该策略执行业务逻辑可能会造成系统异常卡顿
| 名称 | 类型 | 说明 |
|---|---|---|
| BlockingWaitStrategy | 阻塞策略 | 效率最低,但对CPU消耗最小 在各种不同部署环境中能提供更加一致的性能表现 |
| SleepingWaitStrategy | 睡眠策略 | 性能表现与 BlockingWaitStrategy 类似,但对生产者线程影响最小 适用于类似异步日志的场景 在 32 位 Linux 系统上,源码中的 LockSupport.parkNanos() 实现代价相当昂贵,不推荐使用 |
| YieldingWaitStrategy | 竞争策略 | 性能最好,适用于低延迟系统 在要求极高且事件处理线程数小于CPU逻辑核心数的场景中适用该策略(CPU具有超线程能力) |
Event:
需要放入到 Disruptor 的数据单元(实体类),由用户创建
EventProcessor:
主要事件循环,处理 Disruptor 中的 Event,拥有消费者的 Sequence
单消费者模式下实现类为 BatchEventProcessor,包含了 event loop 有效的实现, 通过 run 方法不断轮训获取数据对象,将数据对象交给消费者进行处理,并且将回调一个 EventHandler 接口的实现对象
多消费者模式下实现类为 WorkProcessor
EventHandler:
由用户实现并且代表了 Disruptor 中的一个消费者的接口,消费者逻辑都需要写在这里
WorkProcessor:
确保每个 Sequence 只被一个 processor 消费,在同一个 WorkPooI 中处理多个 WorkProcessor 不会消费同样的 Sequence

若有收获,就点个赞吧
0 人点赞
