对象
Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,而每种对象又通过不同的编码映射到不同的底层数据结构。
一、Redis对象类型和编码
Redis中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的三个属性分别是type属性、 encoding属性和ptr属性:<br /> Redis使用对象来表示数据库中的键和值,每次当我们在Redis的数据库中新创建一个键值对时,我们至少会创建两个对象,一个对象用作键值对的健(key),另一个对象用作键值对的值(value)。<br />Copy
typedef struct redisObiect{//类型unsigned type:4;//编码unsigned encoding:4;//指向底层数据结构的指针void *ptr;}
其中Redis的键对象(key)都是字符串对象,而Redis的值对象(value)主要有字符串、哈希、列表、集合、有序集合几种。其分别对应的内部编码和底层数据结构如下图所示:<br />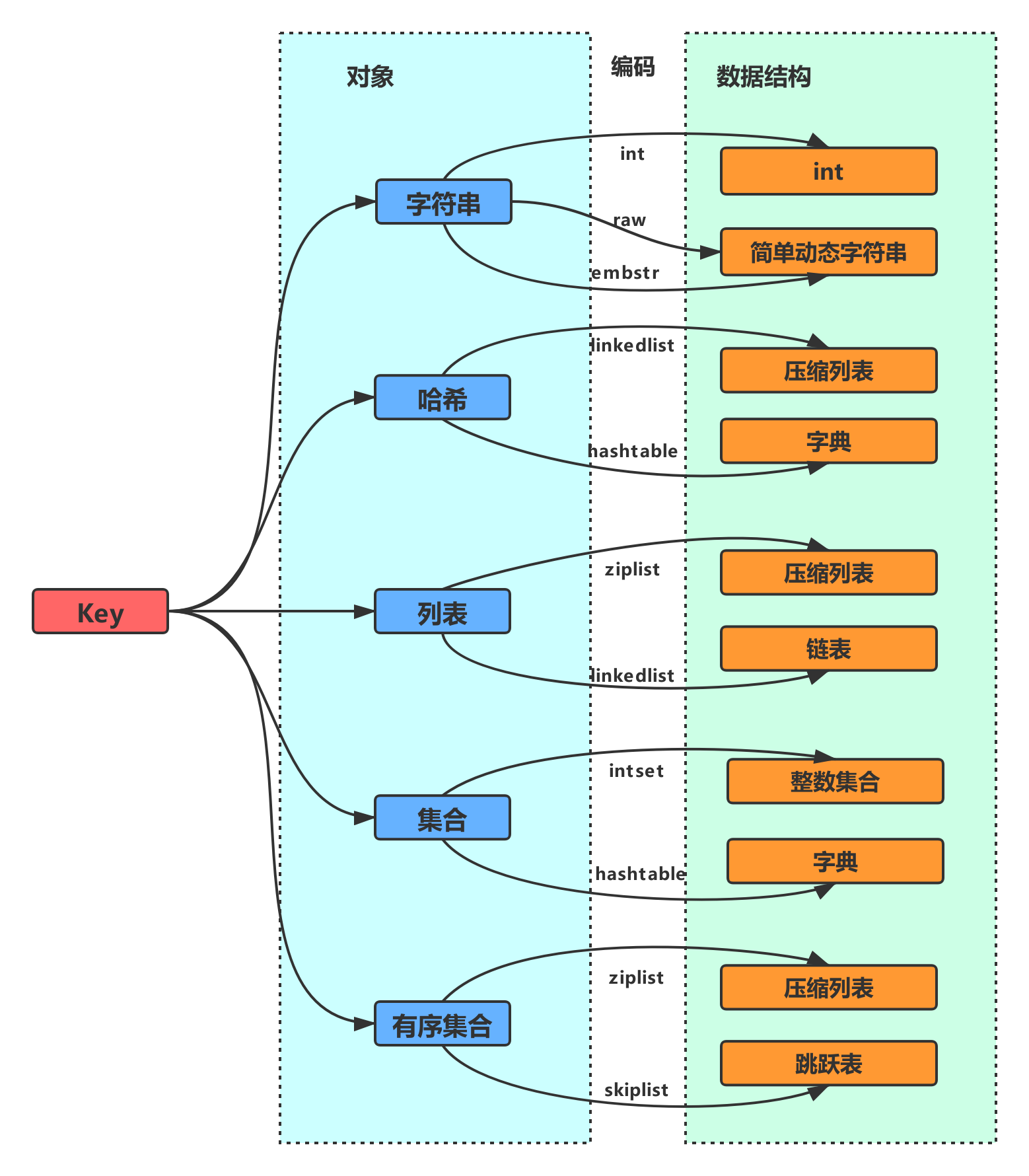
二、思考一个问题
Redis中的对象,大都是通过多种数据结构来实现的,为什么会这样设计呢?用一种固定的数据结构来实现,不是更加简单吗?<br />Redis这样设计有两个好处:
- 可以自由改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出更优秀的内部编码,无需改动外部数据结构和命令,例如Redis3.2提供了quicklist,其结合了ziplist和linkedlist两者
的优势,为列表类型提供了一种更为优秀的内部编码实现,而对外部用户来说基本感知不到。 这一点比较像程序设计中的分层架构。 - 多种内部编码实现可以在不同场景下发挥各自的优势,从而优化对象在不同场景下的使用效率。例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降,这时候Redis会根据配置选项将列表类型的内部实现转换linkedlist。 (后续文章将根据具体对象介绍)
本文重点
- Redis基于底层的一些数据结构创建了一个对象系统以供用户使用
- 这个系统主要包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象
- Redis的键对象都是字符串对象
- Redis的值对象主要有字符串、哈希、列表、集合、有序集合几种
- 为了可以自由改进内部编码,以及在不同场景下发挥其最大优势,Redis中的对象,大都是通过多种数据结构来实现
字符串
另外,因为 Redis没有为embstr编码的字符串对象编写任何相应的修改程序(只有int编码的字符串对象和raw编码的字符串对象有这些程序),所以embstr编码的字符串对象实际上是只读的。当我们对embstr编码的字符串对象执行任何修改命令时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。因为这个原因,embstr编码的字符串对象在执行修改命令之后,总会变成一个raw编码的字符串对象。
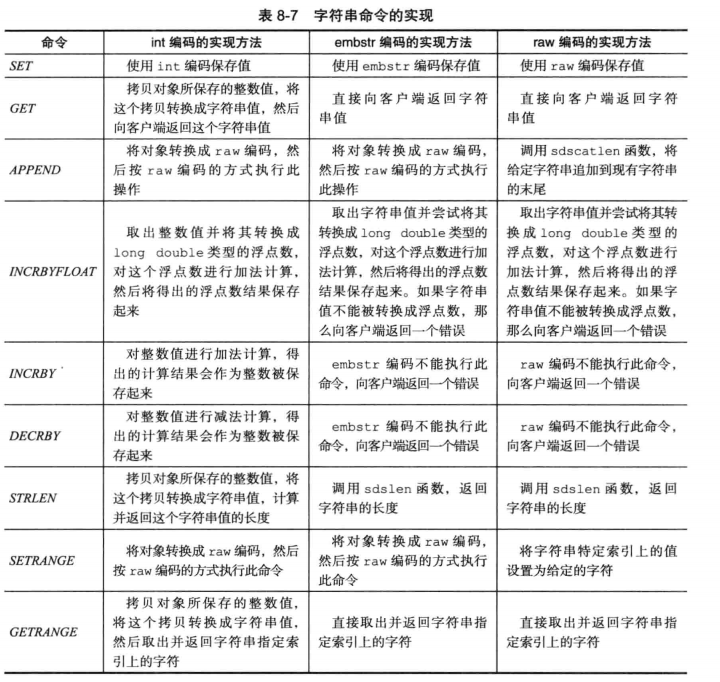
列表
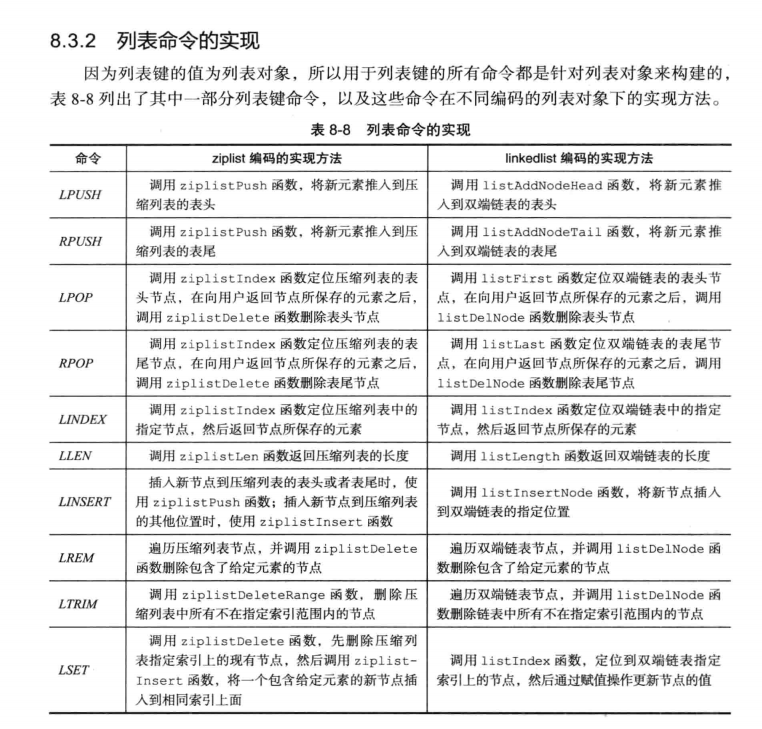
哈希
当哈希对象可以同时满足以下两个条件时,哈希对象使用ziplist编码:哈希对象保存的所有键值对的键和值的字符串长度都小于64字节;
哈希对象保存的键值对数量小于512个;不能满足这两个条件的哈希对象需要使用hashtable编码。

集合对象
当集合对象可以同时满足以下两个条件时,对象使用intset编码:
- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过512个;
不能满足这两个条件的集合对象需要使用hashtable编码。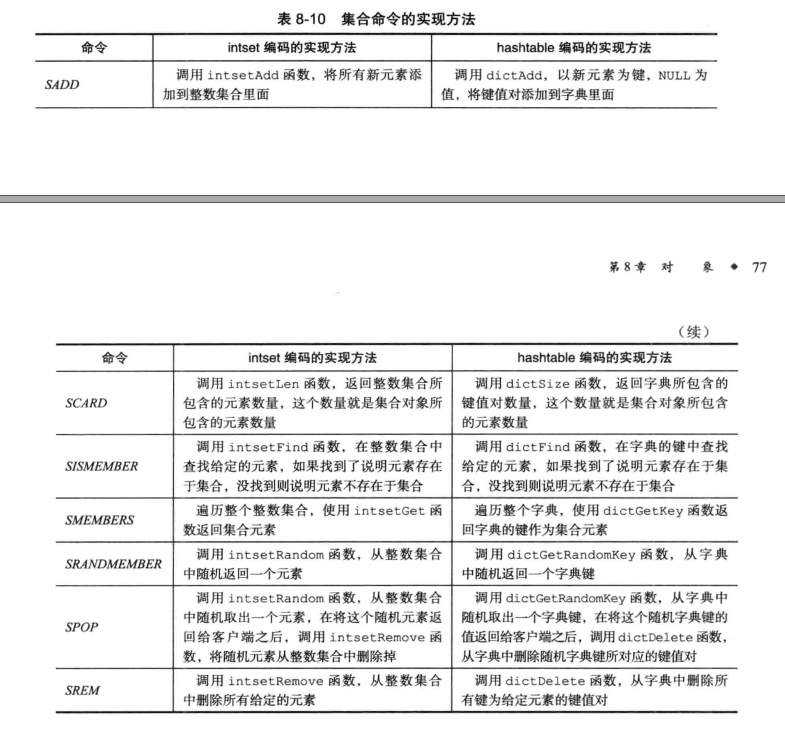
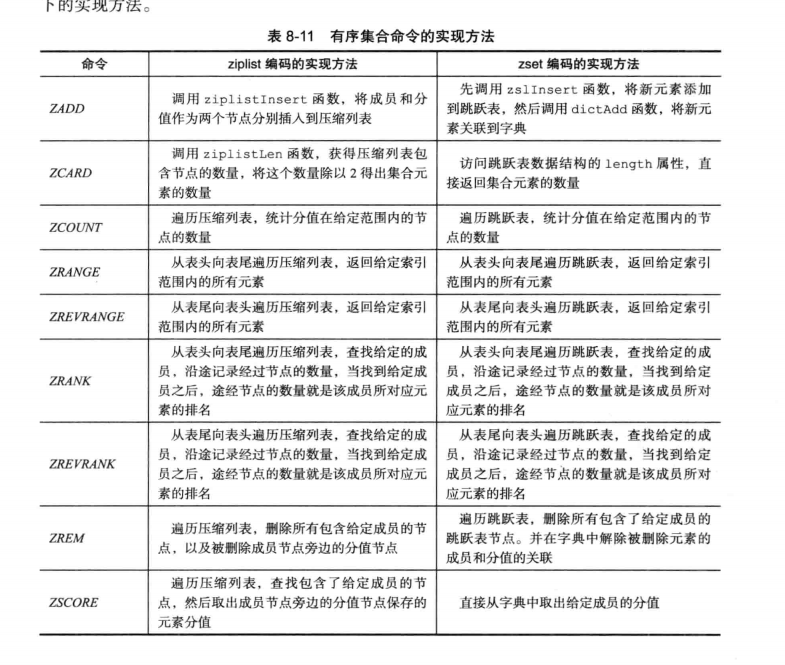
有序集合
当有序集合对象可以同时满足以下两个条件时,对象使用ziplist编码:
- 有序集合保存的元素数量小于128个;
- 有序集合保存的所有元素成员的长度都小于64字节;
不能满足以上两个条件的有序集合对象将使用skiplist编码。
为什么有序集合需要同时使用跳跃表和字典来实现?
在理论上,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在性能上对比起同时使用字典和跳跃表都会有所降低。举个例子,如果我们只使用字典来实现有序集合,那么虽然以o(1)复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作——比如ZRANK、ZRANGE等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少o(NlogN)时间复杂度,以及额外的o(N)内存空间(因为要创建一个数组来保存排序后的元素)。
另一方面,如果我们只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从o(1)上升为o(logN)。因为以上原因,为了让有序集合的查找和范围型操作都尽可能快地执行,Redis 选择了同时使用字典和跳跃表两种数据结构来实现有序集合。

若有收获,就点个赞吧
0 人点赞
