yum的rpm包安装法
从mysql官网找到mysql的rpm包地址使用wget下载wget 下载mysql.rpm 包wget https://dev.mysql.com/get/mysql80-community-release-el7-5.noarch.rpmrpm -ivh mysql80-community-release-el7-5.noarch.rpm #解包进入MySQL配置文件修改:配置MySQLyum源vim /etc/yum.repos.d/mysql-community.repo #修改配置文件如下mysql5.7配置nabled=1 #开启5.7的MySQLgpgcheck=0 #关闭密钥认证,如果开启必须修改密钥因为现在密钥过期了mysql8.0配置enabled=0 #关闭5.8的MySQLgpgcheck=1 #密钥认证可以不用管他安装mMySQL数据库:yum -y install mysql-community-server如果安装MySQL时没有关闭GPG密钥认证会安装失败;下载如下密钥即可解决:rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022修改完成后再执行一下mysql安装;----------------------------------------------------------------------------------------------------------------mysql --version #查询mysql版本信息systemctl start mysqld #启动mysql数据库systemctl enable mysqld #设置开机启动grep passswor /var/log/mysqld.log #查看mysql密码 (后期修改的密码过滤不到只能看到初始化的密码)----------------------------------------------------------------------------------------------------------------如果首次启动过滤不到密码,进行如下操作:systemctl stop mysqld #停掉MySQL数据库rm -rf /var/lib/mysql/* #删除MySQL数据库 (这种操作只能再刚安装好时使用其他情况谨慎操作)systemctl start mysqld #重启MySQL数据库
sql语句(增删改查)
SQL(Structured Query Language 即结构化查询语言)
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。
DDL语句Database Define Language 数据库定义语言:数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
DML语句Database Manage Language 数据库操纵语言(对记录的操作): 插入数据INSERT、删除数据DELETE、更新数据UPDATE
DCL语句Database Control Language 数据库控制语言(和权限有关): 例如控制用户的访问权限GRANT、REVOKE
DQL语句Database Query Language 数据库查询语言:查询数据SELECT
数据库命令
create database tt1 创建库
show databases; 查看所有数据库
use tt1 切换库
select database(); 查看当前在那个库
show tables; 查看库下的所有表格
创建表(详解):
create table 表名( 字段名1 类型[(宽度) 约束条件])
create table tt1(id int,name varchar(5),age int); 创建表格
在同一张表中,字段名是不能相同
宽度和约束条件可自选着
字段名和类型是必须写
id int name varchar (20) age int
字段 类型 字段 类型 (长度) 字段 类型
类型就代表设置了,只能写入对应设置的类型;
show tables; 查看全部表格
desc tt1; 查看表格类型
select 内容 from 表名; 语法使用
select from tt1; 查看表格全部内容 (代表全部)
select id,name from tt1; 查看表格指定字段内容
rename table 旧表名 to 新表名 修改表名语法
rename table tt1 to tt3; 修改表名
alter table tt3 rename tt1 修改表名
drop table tt1; 删除表
delete from tt1; 删除表内容(全部)
drop database tt1; 删除库
数据类型
在MySQL数据库管理系统中,可以通过存储引擎来决定表的类型。同时,MySQL数据库管理系统也提供了数据类型决定表存储数据的类型。
整型类型
作用:用于存储用户的年龄、游戏的等级、经验值等。
显示宽度:类型后面加的数字是显示的最小宽度,并不是显示限制数值的长度;
如果不设置让他默认都是11会占用太对的磁盘空间;设置数字不够他会自动添加
取值范围类型参数值:
| MySQL数据类型 | 最小值 | 最大值 |
|---|---|---|
| tinyint(n) | -128 | 127 |
| smallint(n) | -32,768 | 32,767 |
| mediumint(n) | -8388608 | 8388607 |
| int(n) | -2,147,483,648 | 2,147,483,647 |
| bigint(n) | -9,223,372,036,854,775,808 | 9,223,372,036,854,7 |
结论:
当数值超出选择范围就使用比它的类型(如:int超出范围值就选bifint的)
在 MySQL 中,int 数据类型是主要的整数数据类型。
int(n)里的n是表示SELECT查询结果集中的显示宽度,并不影响实际的取值范围,没有影响到显示的宽度
整型的宽度仅为显示宽度,不是限制。因此建议整型无须指定宽度。
案例操作:
create table yy1(id int(50),name int(200)); 创建表格
insert into yy1(id,name) values(100,500); 写入表格信息
整型的宽度不受宽度设置的限制;因此建议整型无须指定宽度
浮点数类型 FLOAT DOUBLE格式
作用:用于存储用户的身高、体重、薪水等
浮点类型的受宽度限制;如:一共5位,整数占3位.做限制;
5,2就相当于5-2=3整数不能大于三位点后面只显示两位其它数四舍五入
案例:
create table float1(tom float(5,2)) 创建表格
insert into float1(tom) values(458.45671) 写入把表格内数据
select * from tloat1
| tom |
| 458.46 | 查看显示如下
定点数类型 DEC格式
定点数在MySQL内部以字符串形式存储,比浮点数更精确,适合用来表示货币等精度高的数据。
作用:用于存储用户的姓名、爱好、电话,邮箱地址,发布的文章等
字符类型 char varchar:
char:长度设置时固定的,插入长度小于设定值会用户空格填充,因为长度固定所以占用磁盘多,但是它存取速度快
varchar:长度可变长,插入多长就按照多长储存,但也不超过设置的固定值;给char比它占用磁盘空间少但是读取也会慢;
char列长度固定位创建表时声明长度:0~255
varchar根据字符长度占用设置,最多设置10个;长度范围0~65535
案例
create table char1(c char(5),va varchar(12)); 创建表格
insert into char1(c,va) values(’dea’,’dadadr’); 写入表格内容
insert into char1(c,va) values(’dasdad’,’dadadr’); 超出会报错
char可以少于规定长度,不能大于规定长度
总结:
1.经常变化的字段用varchar
2.知道固定长度的用char
3.超过255字符的只能用varchar或者text
4.能用varchar的地方不用text
text:文本格式
枚举类型 enum格式
有字符限制,只能从设置的字内选择一个,有限制的时候用枚举
create table en1(tom enum(‘man’,’woman’)); 创建表格
insert into rn1(tom) values(‘man’); 写入内容
只能选设置的两个字选择其他会报错
日期类型
时间和日期设置测试类型有:
year 年
date 年月日
time 当前时间
datetime 年月日小时分钟秒
timestamp 年月日小时分钟秒
作用:用于存储用户的注册时间,文章的发布时间,文章的更新时间,员工的入职时间等
插入年份时,尽量使用4位值
插入两位年份时,<=69,以20开头,比如65, 结果2065
>=70,以19开头,比如82,结果1982
create table datime1(d date,t time,dt datetime); 创建表格
insert into datime1(d,t,dt)values(now(),now(),now()); 写入表格内容
select * from datime1 查看表格内容
表完整性约束(表约束条件)
约束条件分为:1·主键 2.自增 3.唯一约束 4.null与not null约束
作用:用于保证数据的完整性和一致性
约束条件 说明
primary KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录,不可以为空 UNIQUE + NOT NULL
foreign KEY (FK) 标识该字段为该表的外键,实现表与表之间的关联
NULL 标识是否允许为空,默认为NULL。
NOT NULL 标识该字段不能为空,可以修改。
UNIQUE KEY (UK) 标识该字段的值是唯一的,可以为空,一个表中可以有多个UNIQUE KEY
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号,正数
主键:primary key
每张表里只能有一个主键,不能为空,而且唯一,主键保证记录的唯一性,主键自动为NOT NULL。
一个 UNIQUE KEY 又是一个NOT NULL的时候,那么它被当做PRIMARY KEY主键。
添加方式分为2种:表存在时添加和不存在时添加
alter table 表名 add 约束条件(指定字符); 语法
alter table tt1 add primay key (id); 给指定表添加约束条件
create table tt2(id int,name varcha(5),primary key(id)); 创建表时添加约束条件(主键)
alter table tt1 drop primary key; 删除约束条件
主键约束条件被删除后,这个字段仍然不允许为空值;
给表添加了约束条件后,添加的字段不允许有空值,不写会报错;
auto_increment自增—-自动编号约束
自增约束默认情况要和主键组合使用,默认起始值为1,每次增加量为1;如插入时指定数值会有两种情况,插入重复数会报错因自增约束值是唯一的,要插入值大于已有编号,就会插入,并且从这个新值开始递增,这就表明,可以跳值插入编号;
如果在自增约束种删除最大数值,再插入新值是被删除的值不会再重用
每张表只能有一个字段为自增, 成了key才可以自动增长;
clter table tt2 change id id int auto_incerment; 有表时添加约束
create tabe tt2(id int primary key auto_increment,name varchar(5)); 创建表时设置主键自增
alter table tt2 change id id int not null 取消自增长约束
删除的字段自增号不会在启用,但是可以手动添加上;
unique唯一字段约束
字段添加约束后,改字段的值不能重复,也就是说一列种只能有一个不能相同;
alter table tt1 add unique key (id); 给指表添加指定字段约束
create table tt3(id int,name char(20) unique ); 创建表示给添加字段约束
alter table tt1 drop index name; 删除字段约束条件
null与not null 空值约束
null默认,允许为空,设置not null字段不允许为空;如没设置空值约束,插入时默认选择空值
要设置了不能为控制,又没自己选择就会默认选择提前设定好的其中一个
如:sex enum(‘x’,‘y’)not null default ‘x’ 两个都不选择默认选择‘x’
创建表时设置默认值不能为空,选择默认设置的字符:
create table tt4(id int,age varchar(10),sex enum(‘man’,‘x’)not null default‘man’);
删除不允许为空,和默认值:
alter table tt4 change sex sex enum(‘man’,x’);
创建表时不设置not null值,默认值就会为空值;
unsigned属性约束:
整说类型选项的属性unsigned属性,表示不允许使用负值数,而正数大概就可以提高一倍数值
可以使用的整数类型:
tinyint smallint mediumint int bigint 分别使用8 16 24 32 64位储存空间
它可用存储范围:从-2(n-1)到2(n-1)-1,n代表储存空的位数
-2^8-1=-128到2^8-1=127 数值算法
吧字段指定为unsignned后只能设置正数不能设置负数;一般情况下使用qq好手机号等;
指定字符级:
修改字符集:
在创建表最后加上:default charset=utf8 代表可以指定中文(只有char和varchar可以使用)
create table tt1(id int,name char) default charset=utf8; 创建表时指定可以输入中文
不指定插入中文时会报错;
默认约束
create table tt1(id int,name varchar(20),age int); 创建表默认值
修改默认值:
alter table tt1 change id id int not null default 3; 修改默认值不允许为空值
插入值:
alter table tt1 change id id int not null auto_increment; 添加自增约束值
alter table tt1 alter drop default; 删除默认值
表操作:
添加字段
alter table 表名 add 字段 类型; 语法
alter table tt2 add id int(10); 添加字段
alter table tt2 add (id int(10),tom char(8)); 添加多个字段
alter table 表名 add 添加字段和类型 after name; 语法
alter table tt2 add kun int(15) after tom; 吧kun字段添加到tom字段后面
alter table tt2 add nat int(5)first; 添加字段放在第一个
after代表吧字段放在某一个字段后面
first代表吧字段添加到第一个
修改字段和类型(change或者modify)
修改名称、数据、类型、约束、位置
alter table 表名 change 旧字段 新字段 类型;
alter table tt1 change id idx int; 吧id修改为idx类型不变
alter table tt2 change name name char(5) after id; 修改字段名字并修改位置
alter table tt3 change name name char(5) unique; 修改字段的约束条件
删除字段
alter table 表名 drop 字段名; 语法
alter table tt3 drop id; 删除表里的id字段
插入数据(添加记录)
创建表指定字段名和类型:
clter table tt4(id int,name char,gae int,sex enum(‘m’,’y’));
字符串必须用引号引起来;
添加数据(记录)要与表头对用,表头要与字段用逗号隔开;
添加一条记录:
insert into 表名(字段1,字段2,字段2) values(1,’tao’,’y’); 语法
insert into tt4(id,name,sex) values(1,’tao’,’y’);
添加多条记录:
insert table tt4(id,name,sex) values(2,’tom’,’m’),(10,’jaek’,’y’);
用set添加记录:
mysql> insert into t3 set id=4,name=”zhangsan”,sex=”m”;
更新记录:
update 表名 set 修改新字段名 where 给谁修改; 语法
update tt5 set id=5 where name=’xiao’; 吧id修改为5
update tt5 set name=’bak’ where name=’xiao’; 吧name字段里的xiao修改为bak
update tt5 set id=4 where name=’xiao’ and id=5; 吧有id=5和name=xiao的id修改为id=4
and 某字符和某个字符
or 某个符或某个字符
修改记录时可以用同一字段的名字修改,
如有相同的要修改写有指定id和指定名字才能被修改;
删除记录:
删除单条记录
delete from tt4 where id=6; 删除整行记录id=几就删除哪一行
删除所有记录
delete from t3; 删除整个表里的全部记录
单表查询
号代表查询全部
,查询单个输入指定字段多个用逗号隔开
where加条件查询
as临时设置别名查询
select from tt2; 简单查询(查询所有表)
select id,name from tt2; 多段查询(字段用逗号隔开)
select id,name from tt2 where id<=3; 查询大于等三的字符
select id,name from,jiak as “编号” from tt2 where jiak>5000; 查看小于五千的字段信息
count() 统计数量
distinct 不重复显示有相同数据
select count(*) from tt2; 统计表总行数(以最多行显示)
select count(id)from tt2; 查询id字段总数
select count(name) from tt2 where jiak>=5000; 统计出字段内大于等于五千的有多少人
select distinct tom from tt2; 查询字段信息不显示重复的
表复制 (key不会复制主键、外键和索引)
复制表:
复制表结构+记录 key不会复制主键、外键和索引
create table 新表名 select from 旧表名; 语法
create table tt1_new select from tt1; 复制出一个新表
create table tt2_new(select id,name from tt1) 复制单个字段和记录
多条件查询(and or)
and ——代表 和/与
or ——代表 或/或者
select 字段1,字段2 from 表名 where 条件1 and 条件2 语法
查询出名字时tom和数值大于1000的字符
select sex,name from tt2 where name=’tom’ and sex>1000;
查询出字符是tom和id等于5的字段
select id,name from tt2 where name=”tom” or id=5;
查询出字符为tom或者大于1000数和id等于10的字段
select id,sex,name from tt2 where name=’tom’ and sex>1000 or id=10;
关键字查询 什么和什么之间
between 某值和某值之简
not between 某值和某值之外
查出字段内5000到15000内的数值
select name,salary from tt5 where salary between 5000 and 15000;
查出字段5000和15000外的数值
select name,salary from tt5 where salary not between 5000 and15000;
关键字 is null 空的
is null 允许为空 (空值可以不显示出来)
is not null 不允许有空值(有空值也要显示出来)
NULL说明:
1、等价于没有任何值、是未知数。
2、NULL与0、空字符串、空格都不同,NULL没有分配存储空间。
3、对空值做加、减、乘、除等运算操作,结果仍为空。
4、比较时使用关键字用“is null”和“is not null”。
5、排序时比其他数据都小(索引默认是降序排列,小→大),所以NULL值总是排在最前。
关键字in集合查询
in 集合查询:
查询出包含指定字符的字段字或数值
select name,salary from tt5 where salary in(5000,4000,9000,15000);
查询出除指定字符的其他数值或字符
select name,salary from tt5 where salary not in(5000,4000,9000,15000);
排序查询 (order by desc)
order by 在mysql里是排序查询(默认升序)
desc 查询(降序)
select salary from tt5 orde by salary; 排序查询(默认升序)
select salary from tt5 orde by salary desc; 排序程序(降序查询)
限制查询 (limit)
select from tt5 limit 5; 查询前五行内容
select from tt5 limit 5,10; 查询从第几行开始到第几行结束
分组查询 group by
分组查询count计算里面有多少条
select count(name),post from tt6 group by post; 查询出同一不部门有各有多少人
select count(name),salary from tt6 group by salary; 查出同一薪资,都有多少人
select count(name),sex from tt6 group by sex; 查出男,女工共有多少人
select count(*) from tt7 group by name; 查出全部人共有多少条记录
WITH ROLLUP (组数总和)(侧重点)
with rollup 在分组查询基础上再进行相同统计
select 字段名,sum(要查字段名) from 表名 group by with rollup; 语法
select name,sum(age) from tt7 group by with rollup; 查出分组数再计算出总和
我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce
select coalesce(a,b,c);
参数说明:如果有空字就填写设置的a名字,要没有空值就不会选用设定好的字符
select coalesce(name,“总数”),sum(age) from tt7 group by with rollup;
如果name字段有空值就会使用设置好的”字符”填充上去;
group by和group_concat()函数一起使用
group_concat() ———-组链接
select dep_id,group_concat(name) from tt7 group by dep_id; 查出指定分组里都有谁
select id,grou_concat(name) as emp_tom from tt7 group by dep_id;
查询出分组都有谁并给名字表头设置一个别名;
统计出都有那些人分别都是谁:
select count(name),group_concat(name) from tt7 where sex=’male’;
查询出工资指定2200的都有那些人:
select count(name),group_concat(name) from employee5 where salary=2200;
函数
max() 最大值
mysql> select max(salary) from employee5;
查询薪水最高的人的详细信息:
select * from emp6 where age=(select max(age)from emp6);
min() 最小值
select min(salary) from employee5;
avg() 平均值
select avg(salary) from employee5;
now() 现在的时间
select now();
sum() 计算和
select sum(salary) from tt8 where post=’sale’
多表查询分为 (内链接、左外连接、右外连接、全外连接)
内链接查询:就时吧不同的表,有相同关联字组合的一条记录,进行匹配查询,内链接只能匹配到相同数据的行;
当查询时,数据不在一张表又要同时操作这些表,就为关联查询,(这种称为内连接);
内连接:可对多张表查出,查询时表种应存在,有关联的两个字段组成一条记录,但只能链接匹配到的行;
案例操作:
select 字段1,字段2,字段3,第二张表的字段 from 第一张表名,第二张表名 where 第一张表相同字段名 = 第二张表相同字段名; 语法使用
select emp6.emp_id,emp_name,age,kmp6.dept_name from emp6,kmp6 where emp6.emp_id=kmp6.emp_id; 多表内链接查询
也可吧表名成指定子字符代替如:表一为a 表二为b
就是吧表一的所有对应的表都写上对应的设置对应代替字符;
select a.emp_id,a.emp_name,a.age,b.dept_name from emp6 a inner join kmp6 b on a.emp_id= b.emp_id; 代替表名多表内链接查询
多表内链接查询:使用全名和带着字符要加参数 inner join on ;
不写加全表名只写字段表头只许加where即可;
外链接查询:在做多张表查询时,所需要的数据,除了满足关联条件的数据外,还有不满足关联条件的数据。此时需要使用外连接;外链接就是没有相同的也显示出来;
左外连接:表A left join 表B on 关联条件,表A是主表,表B是从表(显示出A主表不相同的)
右外连接:表A right join 表B on 关联条件,表B是主表,表A是从表(显示出B主表不相同的)
全外连接:表A full join 表B on 关联条件,两张表的数据不管满不满足条件,都做显示。
左链接: select emp_id,emp_name,dept_name from emp6 left join kmp6 on emp6.epm_id=kmp6.emp_id;
select 字段1,字段2,字段3,第二张表的字段 from 第一张表名 left join 第二张表名 on 第一张表相同字段名 = 第二张表相同字段名;
右连接: select emp_id,emp_name,dept_name from emp6 right join kmp6 on emp6.epm_id=kmp6.emp_id;
select 字段1,字段2,字段3,第二张表的字段 from 第一张表名 right join 第二张表名 on 第一张表相同字段名 = 第二张表相同字段名;
全连接: select emp_id,emp_name,dept_name from emp6 left join kmp6 on emp6.epm_id=kmp6.emp_id union select emp_id,emp_name,dept_name from emp6 right join kmp6 on emp6.epm_id=kmp6.emp_id;
破解mysql root的密码:
vim /etc/my.cnf 配置文件
#validate_password=off 这行注释打开
进入mysql数据库然后执行
mysql> UPDATE mysql.user SET authentication_string=password(‘QianFeng@123’) WHERE user=’root’ AND host=’localhost’;
user=’root’ 主机用户的名称
host=’localhost’ 主机时本地登录还是全部远程登录符号
FLUSH PRIVILEGES; 刷新配置
权限管理
用户管理
本地登录客户端命令:
mysql -uroot -pKuku@123
远程登录命令:
mysql -uroot -pKuku@123 -h192.168.211.130
-u 用户名 (要使用那个用户登录)
-p 密码 (使用登录的用户密码)
-P 指定端口 (默认指定端口时3306 (P是大写))
-h 指定IP地址 (要远程机器的IP地址)
# mysql -h192.168.246.253 -P 3306 -uroot -pqf123 -D mysql -e ‘select * from user’;
-D mysql为指定登录的数据库
-e 指定SQ语句(实现非交互式操作查询数据库内信息)
更换端口可以在配置文件内【mysqld】标签下面添加port=指定端口。重启服务
创建用户
create user 用户名@’可登录的主机范围’ identified by ‘密码’;
create user jack@’%’ identidied by ‘Jack@123’;
flush privileges; 更新授权表
主机登录选择:
% 本地机器可登录和全部主机都可远程登录
192.168.211.% 指定网段机器可登录(不可以使用本地登录)
192.168.211.130 指定主机可登录
localhost 只允许本地用户登录
grant 授权(给用户设置权限)
grant all on . to jack@’localhost’;
grant 权限 库名.表名 用户名@’可登录主机’
将允许本地登录修改为远程登录:
use mysql 切换用户
update user set host=’192.168.211.%’ where user=’jack’
flush privileges; 更新权限
刷新权限
修改表之后需要刷新权限;
flush privileges; 更新权限
方法二:创建用户
使用命令创建用户并授权:grant
也可创建新账户(不过后面的版本会移除这个功能,建议使用create user)
grant 权限列表 on 库名.表名 to ‘用户名’@’客户端主机’ IDENTIFIED BY ‘Qf@123’;
grant all on ku1.db1 to jack@’%’ identified by ‘Jack@123’;
——————————————————————————————————————————————————————-
all 所有权限 (不包括授权权限’grant’是授权权限命令)
#注意:root用授权时候grant授权权限不要给予其他用户(谨慎使用)
. 所有库下的所有表都有权限
wed. 指定库下的所有表都有权限
wed.t1 指定库下的指定表有权限
授权用指定权限:
grant 权限命令 on . to 指定用户
grant select,insert on .* to ‘tom’@’localhost’;
多个权限使用逗号分隔,给全部命令直接输入all;
权限介绍

查看权限
查看自己权限信息:
show grants\G
查看别人权限:
show grants for jcak’localhost’\G
查看所有表的权限信息:
select * from mysql.tables_priv\G
移除用户权限
REVOKE 权限 ON 数据库.数据表 FROM ‘用户’@’IP地址’; 语法
移除指定权限:
revoke select,delete on . from jack@’localhost’;
移除所有权限:
revoke all privileges on . from jack@’localhost’;
移除权限一定要要存在,不然会报错
整个数据库,使用 ON 库名.*;
特定的表:使用 ON 库名.指定表名;
修改数据库密码
不进入数据库修改密码:
mysqladmin -uroot -p’123’ password ‘new_password’
进入数据库修改密码:
修改自己密码:
password=’新密码’;
修改其他用户密码:
user mysql 先进入mysql用户里面
set password for user jack@’localhost’=’JACK@123’;
删除用户
DROP USER语句删除:
drop user jack@’localhost’;
DELETE语句删除:
delete from mysql.user where user=’tom’ and host=’localhost’;
flush privileges; 更新授权表
查看密码复杂度
MySQL 5.7默认启用了密码复杂度设置,插件名字叫做 validate_password,初始化之后默认是安装的如果没有安装执行下面的命令会返回空或者没有值,这时需要安装该插件
安装插件
mysql> INSTALL PLUGIN validate_password SONAME ‘validate_password.so’;
查看密码复杂程度:
show variables like ‘valdate%’;
+———————————————————+———————————-+
| Variable_name | Value |
+———————————————————+———————————-+
| validate_password_check_user_name | OFF |
| validate_password_dictionary_file | |
| validate_password_length | 8 |
| validate_password_mixed_case_count | 1 |
| validate_password_number_count | 1 |
| validate_password_policy | MEDIUM |
| validate_password_special_char_count | 1 |
+———————————————————+———————————-+
参数解释:
validate_password_length :#密码最少长度,默认值是8最少是0
validate_password_dictionary_file:#用于配置密码的字典文件,字典文件中存在的密码不得使用。
validate_password_policy: #代表的密码策略,默认是(MEDIUM 安全程度)
validate_password_number_count :#最少数字字符数,默认1最小是0
validate_password_mixed_case_count :#最少大写和小写字符数(同时有大写和小写),默认为1最少是0
validate_password_special_char_count :#最少特殊字符数,默认1最小是0
查看密码策略:
select @@validate_password_policy;
策略:
- 0 or LOW 设置密码长度(由参数validate_password_length指定)
- 1 or MEDIUM 满足LOW策略,同时还需满足至少有1个数字,小写字母,大写字母和特殊字符
- 2 or STRONG 满足MEDIUM策略,同时密码不能存在字典文件(dictionary file)中
查看密码的长度
select @@validate_password_length;
设置密码复杂度:
set global validate_password_length=1;
等于几密码长度就为几位
设置密码复杂性策略
set global validate_password_policy=LOW;
也可以是数字表示。#设置密码策略
flush privileges; #刷新授权
权限空置机制
四张表:user db tables_priv columns_priv
1.用户认证
查看mysql.user表
2.权限认证
以select权限为例:
1.先看 user表里的select_priv权限
Y:不会接着查看其他的表 拥有查看所有库所有表的权限
N:接着看db表
2.db表: #某个用户对一个数据库的权限。
Y:不会接着查看其他的表 拥有查看所有库所有表的权限
N:接着看tables_priv表
3.tables_priv表:#针对表的权限
tables_priv:如果这个字段的值里包括select 拥有查看这张表所有字段的权限,不会再接着往下看了
tables_priv:如果这个字段的值里不包括select,接着查看下张表还需要有column_priv字段权限
4.columns_priv:针对数据列的权限表
columns_priv:有select,则只对某一列有select权限
没有则对所有库所有表没有任何权限
mysql.user #全局授权
- mysql.db #数据库级别授权
- 其他 #表级,列级授权
日志管理
1 错误日志 :启动,停止,关闭失败报错。rpm安装日志位置
/var/log/mysqld.log #默认开启
2 通用查询日志:所有的查询都记下来。 #默认关闭,一般不开启
3 二进制日志(bin log):实现备份,增量备份。只记录改变数据,除了(select 查看信息)都记。
4 中继日志(Relay log):读取主服务器的binlog,在slave机器本地回放。保持与主服务器数据一致。
5 慢查询日志,指导调优,定义某一个查询语句,执行时间过长,通过日志提供调优建议给开发人员。
slow log 慢日志(就查询时间超出指定时间就会记录在慢日志里面)
6 DDL log: 定义语句的日志。
日志详解:
Error Log 错误日志
vim /etc/my.cnf
log-reeor=/var/log/mysqld.log
编译安装是在/usr/local/mysql/ (编译安装位置是自定义的一般都是安装在这个目录下)
Binary Log 二进制日志(前提需要开启)
vim /etc/my.cnf
log-bin=/var/log/mysql-bin/mylog #如果不指定路径默认在/var/lib/mysql
server-id=1 #AB复制的时候使用,为了防止相互复制,会设置一个ID,来标识谁产生的日志
创建日志目录
mkdir /var/log/mysql-bin
吧日志主和属组设置成mysql(不设置成mysql是没有权限写入内容的)
chown mysql.mysql /var/log/mysql-bin/
重启mysql
systemctl restart mysqld
查看binlog日志:开启之后等一会
查看这个日志要使用指定命令:
mysqlbinlog mylog.000001 -v
# at 4 #时间的开始位置
# end_log_pos 319 #事件结束的位置(position)
#190820 19:41:26 #时间点
查看出的格式如上;
重启mysqld 会截断日志
mysql> flush logs; 会截断日志
mysql> reset master; 删除所有binlog,不要轻易使用,相当于:rm -rf /(谨慎删除)
#删除mylog.000004之前的日志(不包括0004日志)
mysql> PURGE BINARY LOGS TO ‘mylog.000004’;
暂停 仅当前会话(当前会话生效)
SET SQL_LOG_BIN=0; #关闭
SET SQL_LOG_BIN=1; #开启
—————————————————————————————
解决binlog日志不记录insert语句
登录mysql后,设置binlog的记录格式:
mysql> set binlog_format=statement;
然后,最好在my.cnf中添加:
binlog_format=statement
修改完配置文件之后记得重启服务
—————————————————————————————-
Slow Query Log : 慢查询日志
slow_query_log=1 #开启
slow_query_log_file=/var/log/mysql-slow/slow.log
long_query_time=3 #设置慢查询超时间,单位是秒
# mkdir /var/log/mysql-slow/
# chown mysql.mysql /var/log/mysql-slow/
# systemctl restart mysqld
验证查看慢查询日志
mysql> select sleep(6);
# cat /var/log/mysql-slow/slow.log
expire_logs_days = 7 #binlog日志自动删除/过期的天数。默认值为0,表示不自动删除
数据备份与恢复
为什么备份
备份:能够防止由于机械故障以及人为误操作带来的数据丢失,例如将数据库文件保存在了其它地方。
冗余: 数据有多份冗余,但不等备份,只能防止机械故障带来的数据丢失,例如主备模式、数据库集群。
MySQL数据备份需要重视的内容
备份内容 databases Binlog my.cnf
所有备份数据都应放在非数据库本地,而且建议有多份副本。
测试环境中做日常恢复演练,恢复较备份更为重要。
备份过程中必须考虑因素:
数据的一致性
2. 服务的可用性
Mysql A (读写) 压力比较大
|
Mysql B (读) 压力比较小 从节点做备份MySQL 备份类型
物理备份分为:热备、冷备、温备
物理备份: 直接复制数据库文件,适用于大型数据库环境,不受存储引擎的限制,但不能恢复到不同的MySQL版本。
热备(hot backup):
就是在线备份,比较依赖数据库日志,对应用基本无影响(但是性能还是会有下降,所以尽量不要在主库上做备份,在从库上做)
冷备(cold backup):
备份数据文件,需要停机,是在关闭数据库的时候进行的;备份 datadir 目录下的所有文件
温备(warm backup):
针对myisam的备份(myisam不支持热备),备份时候实例只读不可写,数据库锁定表格(不可写入但可读)的状态下进行的
对应用影响很大,通常加一个读锁
逻辑备份: 备份的是建表、建库、插入等操作所执行SQL语句(DDL DML DCL),适用于中小型数据库,效率相对较低。
物理和逻辑备份的区别:
| | 逻辑备份 | 物理备份
| ——————— | ————————————————————————- | ———————————
| 备份方式 | 备份数据库建表、建库、插入sql语句 | 备份数据库物理文件
| 优点 | 备份文件相对较小,只备份表中的数据与结构 | 恢复速度比较快
| 缺点 | 恢复速度较慢(需要重建索引,存储过程等) | 备份文件相对较大(备份表空间,包含数据与索引)
| 对业务影响 | I/O负载加大 | I/O负载加大
| 代表工具 | mysqldump | ibbackup、xtrabackup,mysqlbackupmysqk备份工具
ibbackup 官方备份工具 收费 物理备份
xtrabackup 开源社区备份工具 物理备份
开源免费,上面的免费版本(老版本有问题,备份出来的数据可能有问题)
mysqldump 官方自带备份工具 开源免费
逻辑备份(速度慢)
mysqlbackup mysql 官方备份工具
innodb 引擎的表mysqlbackup可以进行热备
非innodb表mysqlbackup就只能温备
物理备份,备份还原速度快
适合大规模数据使用物理备份方式:
回滚数据前尽量先吧数据打包一个包,防止恢复失败导致数据丢失;打个包可以恢复失败再解出来原本数据;
完整备份:备份整个数据库所有内容;还是增量备份与差异备份的基础
优点:备份与恢复操作简单方便,恢复时一次恢复到位,恢复速度快
缺点:占用空间大,备份速度慢
增量备份:从上次备份的时间备分到这次备修改或添加数据;
优点:备份数据小,空间占用少,速度快,恢复时要从第一完整备份起按时间顺序恢复,恢复时间长,如中间某一个数据损坏,会导致数据丢失;
差异备份:只备份跟完整备份不一样的
每次备份都时从第一完整备份开始备份到被修改过文件;备份数据量会越来越大
特点:占用空间比增量备份大,比完整备份小,恢复时仅需要恢复第一个完整版本和最后一次的差异版本,恢复速度介于完整备份和增量备份之间。
简单讲:完整备份不管有没有变化都会全部备份一遍,增量备份只会备份上一次时间到这次被修改过的内容,差异备份是将完整备份后被修改过内容进行备份;安装xtrabackup
wget http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
解包:
rpm -ivh percona-release-0.1-4.noarch.rpm
修改下面内容:
vim percona-release.repo
gpqcheck = 1 改为0
gpqcheck = 1 改为0
第一个区块和第二个区块修改
一定要下载这个版本,其他版本不一定能对mysql5.7做备份,不兼容;
yum -y install percona-xtrabackup-24.x86_64
安装报错解决办法:
yum install mysql-community-libs-compat -y #安装包
yum -y install percona-xtrabackup-24.x86_64
方式二安装:
百度搜索:Centos1 yum安装percona
https://zhuanlan.zhihu.com/p/140414143
wget https://repo.percona.com/yum/percona-release-latest.noarch.rpm
rpm -ivh percona-release-latest.noarch.rpm
yum -y install percona-xtrabackup-24.x86_64 #一定要下载这个版本
innobackupex -v 查看版本号(能查到就安装成了)完整备份流程
创建一个备份存放目录
mkdir -p /xtrabackup/full
进入mysql写入数据
完整备份:
innobackupex —user=root —password=’Kuku@123’ /xtrabackup/full
数据回滚:
innobackupex —apply-log /xtrabackup/full/2022-05-10_18-04-59
数据恢复前查看是否有数据库指定恢复目录
cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
没有指定目录添加上指定目录
恢复内容:
innobackupex —copy-back /xtrabackup/full/2022-05-10_18-04-59
————————————————————————————————————————————————————————————-
修改主和属组为mysql.mysql
chown -R mysql.mysql /var/lib/mysql
重启mysql
进入查看是否恢复成功;增量备份
先备份一个完整备份:
innobackupex —user=root —password=’Kuku@123’ /root/back/
增量备份一:
innobackupex —user=root —password=’Kuku@123’ —incremental /root/back/ —incremental-basedir=/root/back/2022-05-10_18-04-59/
—incremental-basedir 参数是给基于哪个增量
增量备份二:
innobackupex —user=root —password=’Kuku@123’ —incremental /root/back/ —incremental-basedir=/root/back/2022-05-10_18-09-49/
恢复数据前要先停止数据库;
systemctl stop mysqld
删除mysql目录下的所有数据
rm -rf /var/lib/mysql/
————————————————————————————————————————————————————————————-
回滚完整备份数据:
先吧完整备份回滚;
然后按时间顺序吧数据回滚到完整备份里面;
一定要按时间顺序不然会造成数据恢复失败;
innobackupex —apply-log —redo-only /root/back/2022-05-10_18-04-59/
回滚增量备份一:
innobackupex —apply-log —redo-only /root/back/2022-05-10_18-04-59/ —incremental-dir=/root/back/2022-05-10_18-09-49/
—incremental-dir 增量目录
回滚增量备份二:
innobackupex —apply-log —redo-only /root/back/2022-05-10_18-04-59/ —incremental-dir=/root/back/2022-05-10_18-20-02/
数据恢复: 恢复完整备份目录
innobackupex —copy-back /root/back/2022-05-10_18-04-59/
设置主和属组:
chown -R mysql.mysql /var/lib/mysql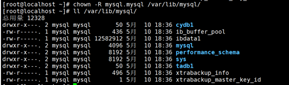
重启mysql数据库
进入数据库查看下数据有没有恢复成功;
差异备份流程:
完整备份
innobackupex —user=root —password=’Kuku@123’ /root/cyback (备份目录可自定义)
差异备份:周二 — 周三 …………
innobackupex —user=root —password=’Kuku@123’ —incremental /root/cyback —incremental-basedir=/root/back/2022-05-10_18-45-33
innobackupex —user=root —password=’Kuku@123’ —incremental /root/cyback/ —incremental-basedir=/root/cyback/2022-05-10_18-45-33
*回滚备份数据:
先吧完整数据回滚;
然后吧要想要恢复到指定某天的数据回滚到完整备份里面;
回滚完整备份数据:
innobackupex —apply-log —redo-only /root/cyback/2022-05-10_18-45-33/
回滚周三差异备份数据:
innobackupex —apply-log —redo-onl /root/cyback/2022-05-10_16-50-20/ —incremental-dir=/root/cyback/2022-05-10_18-51-23
恢复差异备份数据:
innobackupex —copy-back /root/cyback/2022-05-10_18-45-33
吧数据的主和属组修改为mysql.mysql:
chown -R mysql.mysql /var/lib/mysql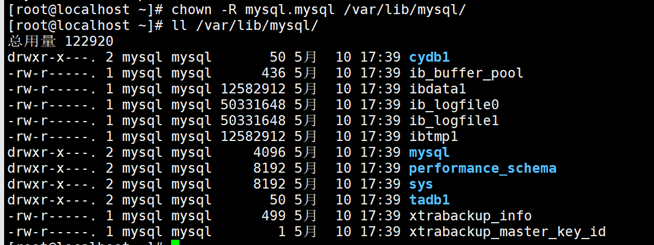
启动数据查看数据是否恢复成功;mysqldump逻辑备份 —推荐优先使用
mysqldump 是 MySQL 自带的逻辑备份工具。可以保证数据的一致性和服务的可用性。
如何保证数据一致?在备份的时候进行锁表会自动锁表。锁住之后在备份。
远程备份语法:mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql
本地备份语法:mysqldump -u用户名 -p密码 数据库名 > 备份文件.sql
常用备份选项:
-A —all-databases #备份所有库
-B —databases #备份多个数据库
-F —flush-logs #备份之前刷新binlog日志
-d —no-data #不导出任何数据,只导出数据库表结构。
-f —force #即使在一个表导出期间得到一个SQL错误,继续。
—lock-tables #备份前,锁定所有数据库表
—single-transaction #保证数据的一致性和服务的可用性
—default-character-set
指定导出数据时采用何种字符集,如果数据表不是采用默认的latin1字符集的话,那么导出时必须指定该选项,否则再次导入数据后将产生乱码问题。
注意事项:
使用 mysqldump 备份数据库时避免锁表:
对一个正在运行的数据库进行备份请慎重!! 如果一定要 在服务运行期间备份,可以选择添加 —single-transaction选项,
类似执行: mysqldump —single-transaction -u root -p123456 dbname > mysql.sql
备份表:
备份一个表:
mysqldump -u root -p’Kuku@123’ db1 t1 > /root/db1-t1.sql
备份多张表:
mysqldump -u root -p’Kuku@123’ db1 t1 t2 > /root/db1-t1-t2.sql
备份多张表或库用空格隔开;
备份表结构:
mysqldump -u root -p’Kuku@123’ -d db1 t1 > /root/db1-t1-t2.sql
备份库:
备份一个库:
mysqldump -u root -p’Kuku@123’ db1 > /root/db1.sql
备份多个库:
mysqldump -u root -p’Kuku@123’ -B db1 tes1 > /root/db1-tes1.sql
备份所有库:
mysqldump -u root -p’Kuku@123’ -A > /root/allku.sql
恢复数据和表:
为保证数据一致性,应在恢复数据之前停止数据库对外的服务,停止binlog日志 因为binlog使用binlog日志恢复数据时也会产生binlog日志。
恢复库:
先进入数据库创建一个库:
create database db1;
mysql -u root -p’Kuku@123’ db1 < /root/db1.sql
恢复表:
恢复所有表或表结构都需要有库,如果没有库恢复数据时就会报错;
mysql> set sql_log_bin=0; #停止binlog日志
source /root/db1.t1 db1-t1.sql 数据库内恢复表
数据库外恢复:
mysql -u root -p’Kuku@123’ db1 t1 < /root/db1-t1.sql
备份表结构及恢复表结构
备份表结构:
mysqldump -uroot -p’Kuku@123’ -d db1 t1 > /root/db1-t1jg.sql
恢复表结构:
登陆数据库创建一个库
mysqldump -uroot -p’Kuku@123’ -D t1 < /root/db1-t1jg.sql
数据导入导出:
数据的导出和导入只备份表内记录,不会备份表结构,需要通过mysqldump备份表结构,恢复时先恢复表结构,再导入数据。
mysql> show variables like “secure_file_priv”; 查询导入导出的目录在那个目录
修改导出和导入目录:
创建一个目录:
mkdir /sql
修改目录的权限为mysql:
chown mysql.mysql /sql
在配置文件内添加:
vim /etc/my.cnf
在[mysqld]这个标签下添加
secure_file_priv=/sql
重新加载mysql配置:
systemctl restart mysqld
导出数据:
mysql内导出数据
select * from t3 into outfile ‘/sql/db1-t3.sql’;
mysql内导入数据
如果将数据导入别的表,需要创建这个表并创建相应的表结构
load data infile ‘/sql/db1-t3.sql’ into table t3;binlog恢复数据
vim /etc/my.cnflog-bin=/var/log/sql-bin/mylogserver-id=1
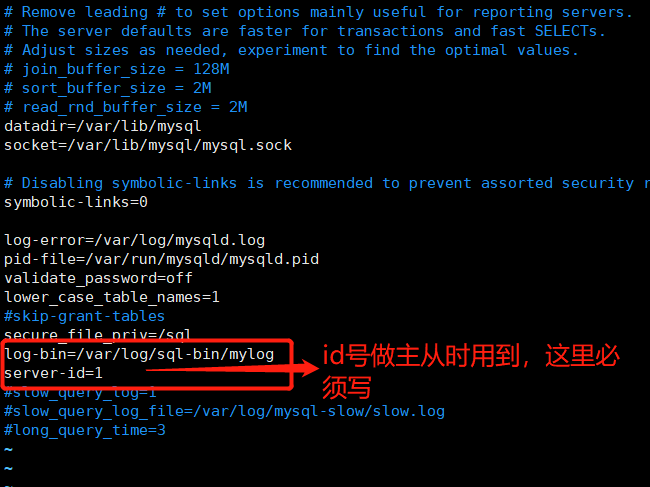
mkdir /var/log/sql-binchown mysql.mysql /var/log/sql-binsystemctl resatart mysqld
刷新binlog日志会截断产生新的日志文件
mysql>flush logs;
刷新日志后会产生出一个新的日志,新的信息会记录在新日志内;
查看binlog日志需要使用指定命令查看;
mysqlbinlog mylog.000002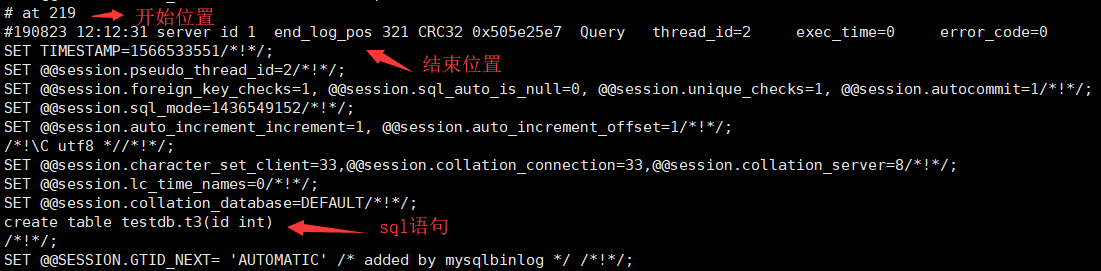
mysqlbinlog —start-position 开始位置号 —stop-position 结束位置号 mylog.000002 | mysql -uroot -p’qf123’
mysqlbinlog —start-position 219 —stop-position 321 mylog.000002 | mysql -uroot -p’qf123’AB复制|主从复制
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。
```git 做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。 架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。 读写分离,使数据库能支撑更大的并发。 在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)。 在从服务器进行备份,避免备份期间影响主服务器服务;(确保数据安全)。
主节点 写 从节点1 从节点2 读 备份
从节点过多,导致数据同步较慢 总结:降低主服务器的I/O的负载率,提高单个机器的I/O(读写)性能,防止数据主数据库故障造成无法恢复;
<a name="PM0pq"></a>### 主从复制的原理```git原理:实现整个主从复制,需要由slave服务器上的IO进程和Sql进程共同完成.要实现主从复制,首先必须打开Master端的binary log(bin-log)功能,因为MySQL主从复制过程实际上就是Slave从Master端获取相应的二进制日志,然后再在自己slave端完全按照顺序执行日志中所记录的各种操作。===========================================1. 在主库上把数据更改(DDL DML DCL)记录到二进制日志(Binary Log)中。2. 从库I/O线程将主库上的日志复制到自己的中继日志(Relay Log)中。3. 从库SQL线程读取中继日志中的事件,将其执行到从数据库之上。===========================================master 负责写 -----Aslave relay-log -----BI/O 负责通信读取binlog日志SQL 负责写数据主数据库吧执行过的sql语句记录进(binlog)日志中,传输给从服务器,从服务器再把sql语句记录在中继日志中,再开启一个sql进程读取中继日志的sql语句,将内容写入自己的数据库中
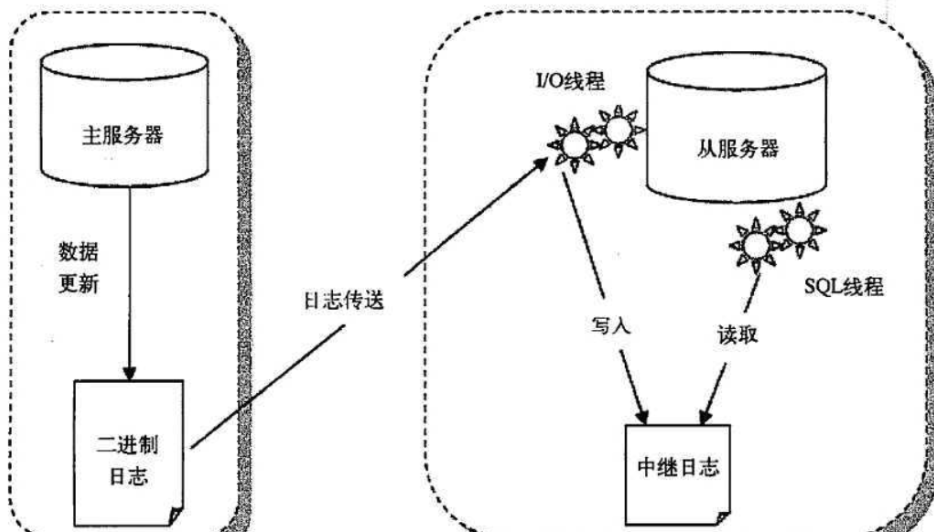
1.主从复制延迟大比较慢原因:主服务器配置高,从服务器的配置低。并发量大导致主服务器读的慢。从服务器写的慢网络延迟比较高从服务器的读写速度慢从节点过多2.从数据库的读的延迟问题了解吗?如何解决?解决方法:半同步复制—解决数据丢失的问题并行复制—-解决从库复制延迟的问题
M-S 架构GTID 基于事务ID复制
全局事务标识:global transaction identifiers是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置。
1、master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。2、slave端的i/o 线程将变更的binlog,写入到本地的relay log中。3、sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。4、如果有记录,说明该GTID的事务已经执行,slave会忽略。5、如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
添加机器互相解析解析/etc/hosts192.168.246.129 mysql-master192.168.246.128 mysql-slave
vim /etc/my.cnf #在[mysqld]下添加如下内容server-id=1 #定义server id master必写log-bin = mylog #开启binlog日志,master比写gtid_mode = ON #开启gtidenforce_gtid_consistency=1 #强制gtidsystemctl restart mysqld #重启数据库主服务器创建用户:并给用户设置权限mysql> grant replication slave,reload,super on *.* to 'jack'@'%' identified by 'Jack@123';#注:生产环境中密码采用高级别的密码,实际生产环境中将'%'换成slave的ipflush privileges; #刷新下配置注意:如果不成功删除以前的binlog日志;replication slave:拥有此权限可以查看从服务器,从主服务器读取二进制日志。super权限:允许用户使用修改全局变量的SET语句以及CHANGE MASTER语句reload权限:必须拥有reload权限,才可以执行flush [tables | logs | privileges]
vim /etc/my.cnf #添加如下配置server-id=2 #定义ID (每一台机器的号都不能相同)gtid_mode = ON #开启GTIDenforce_gtid_consistency=1 #强制开启GTIDmaster-info-repository=TABLE #保存到指定的库内(可不写,这样会保存到磁盘内)relay-log-info-repository=TABLEsystemctl restart mysqldmysql -uroot -p'qf123' #登陆mysqlmysql> \e #进入像vim一样的编辑器内(写入命令执行)change master tomaster_host='master1', #主ip 地址 最好用域名master_user='授权用户', #主服务上面创建的用户master_password='授权密码', #登录密码master_auto_position=1; #主服务器的GTID号-> ;start slave; #启动slave角色show slave status\G #查看状态,验证sql和IO是不是yes。
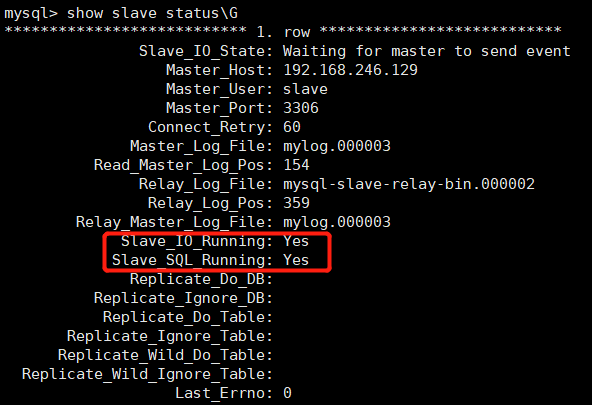
登录主数据库写入新的内容,在从服务上查看是否相同;
如果同步效果不正常,进行以下操作:在2台机器数据保持一致的情况下。从节点:stop slave; #停止同步reset slave; #清除主节点信息主节点:reset master; #清除binlog日志再来到从节点:change master to
主从同步完成。
关闭数据库要按顺序关闭,先关闭从服务再关主服务器,启动要先启动主再启动从;
mysql主从,master宕机,如何进行切换?主机故障或者宕机:1)在salve执行:mysql> stop slave;mysql> reset master;2)查看是否只读模式:show variables like 'read_only';只读模式需要修改my.cnf文件,注释read-only=1并重启mysql服务。或者不重启使用命令关闭只读,但下次重启后失效:set global read_only=off;3)查看show slave status \G;4)在程序中将原来主库IP地址改为现在的从库IP地址,测试应用连接是否正常
主从复制binlog日志方式
先配置机器会相解析;
关闭机器的防火墙和selinux;
在主服务上开启二进制日志记录配置唯一的服务器ID,重mysql;
vim /etc/my.cnf[mysqld] #在这个标签下添加log-bin=/var/log/mysql/mysql-binserver-id=1
mkdir /var/log/mysqlchown -R mysql.mysql /var/log/mysqlsystemctl restart mysqld
GRANT REPLICATION SLAVE ON *.* TO 'jack'@'%' identified by 'Jack@123';flush privileges;
在主服务器上面操作
mysql> show master status\G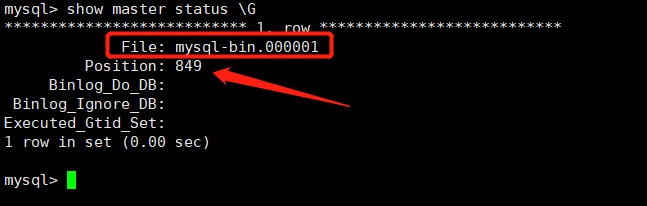
vim /etc/my.cnf[mysqld]server-id=2systemctl restart mysqld进入从数据库执行命令:mysql> \eCHANGE MASTER TOMASTER_HOST='mysql-master',MASTER_USER='repl',MASTER_PASSWORD='Qf@12345!',MASTER_LOG_FILE='mysql-bin.000001', #binlog日志文件名称MASTER_LOG_POS=849; #日志位置-> ;start slave;show slave status\G
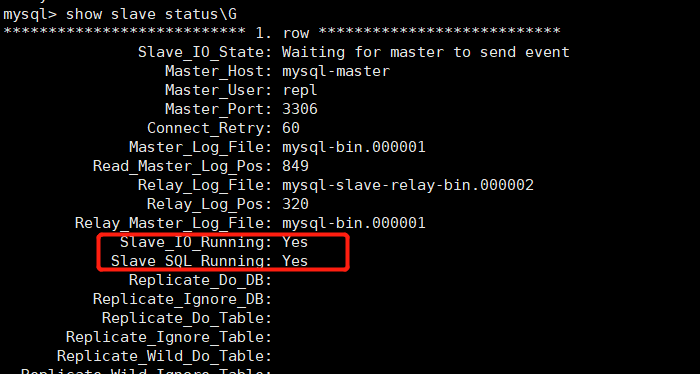
故障排错:
致命错误:由于master和slave具有相同的mysql服务器uuid,导致I/O线程不进行;
这些uuid必须不同才能使复制工作。
一组双从必须使用同样的方式,不能一个使用binlog日志方式一个使用GTID的;
如果已经开启一个主从了也更新信息了,只许要吧主服务更新的库备份发送大到新的服务器上然后恢复数据相同即可;
vim /etc/my.cnfserver-id=3 #每台机器的id不一样gtid_mode = ONenforce_gtid_consistency=1master-info-repository=TABLErelay-log-info-repository=TABLE进入服务执行命令:\eCHANGE MASTER TOMASTER_HOST='mysql-master',MASTER_USER='repl',MASTER_PASSWORD='Qf@12345!',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=849;-> ;start slave; #将slave启动起来show slave status\G #查看一下状态
读写分离
1.什么是读写分离在数据库集群架构中,让主库负责处理写入操作,而从库只负责处理select查询,让两者分工明确达到提高数据库整体读写性能。**当然,主数据库另外一个功能就是负责将数据变更同步到从库中,也就是写操作。2. 读写分离的好处1. 分摊服务器压力,提高机器的系统处理效率。2. 在写入不变,大大分摊了读取,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了。3. 增加冗余,提高服务可用性,当一台数据库服务器宕机后可以调整另外一台从库以最快速度恢复服务。
Mycat 是一个开源的数据库系统,但是由于真正的数据库需要存储引擎,而 Mycat 并没有存储引擎,所以并不是完全意义的数据库系统。 那么 Mycat 是什么?**Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务是实现对主从数据库的读写分离、读的负载均衡。**

MyCAT 是使用 JAVA 语言进行编写开发,使用前需要先安装 JAVA 运行环境(JRE),由于 MyCAT 中使用了 JDK7 中的一些特性,所以要求必须在 JDK7 以上的版本上运行。
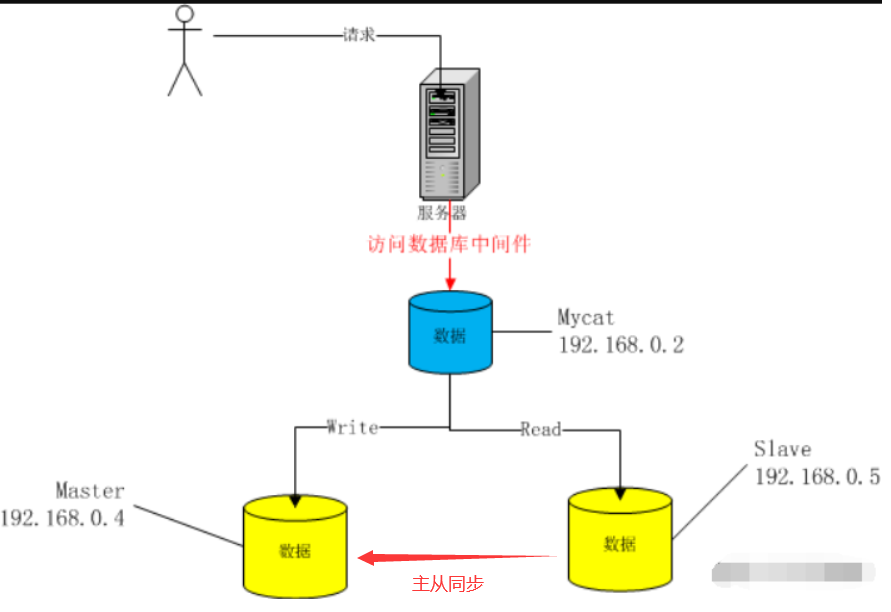
这里是在mysql主从复制实现的基础上,利用mycat做读写分离,架构图如下
配置mycat和主从服务主机解析vim /etc/hosts192.168.118.128 mycat(自定义域名)写入解析IP地址和自定义域名部署环境:安装jdk将jdk包上传到服务器中解包到/usr/local/mv jdk1.8.0_221/ java #移动并修改名称设置环境变量:vim /etc/profile #添加如下内容,JAVA_HOME=/usr/local/javaPATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarsource /etc/profile #刷新环境变量配置
下载mycat包:wget http://dl.mycat.io/1.6.5/Mycat-server-1.6.5-release-20180122220033-linux.tar.gz解包:解到指定目录tar xf Mycat-server-1.6.5-release-20180122220033-linux.tar.gz -C /usr/local/配置mycat信息:MyCAT 目前主要通过配置文件的方式来定义逻辑库和相关配置#定义用户以及系统相关变量,如端口等。其中用户信息是前端应用程序连接 mycat 的用户信息。/usr/local/mycat/conf/server.xml#定义逻辑库,表、分片节点等内容。/usr/local/mycat/conf/schema.xml
cd /usr/local/mycat/confvim server.xml<user name="mycat"> #定义的虚拟数据库名称<property name="password">mycat@123</property> #虚拟数据库密码<property name="schemas">testdb1</property> #定义的虚拟库名</user>这里配置的虚拟库名要和下面schema.xml配置中的虚拟库名一样,不然会启动mycat失败;

<schema name="testdb1" // 逻辑库名称,与server.xml的一致checkSQLschema="false" // 不检查sqlsqlMaxLimit="100" // 最大连接数dataNode="dn1"> // 数据节点名称(定义的数据节点名要下面的一样)<!--这里定义的是分表的信息--></schema><dataNode name="dn1" // 此数据节点的名称dataHost="localhost1" // 主机组虚拟的database="testdb" // 真实的数据库名称/><dataHost name="localhost1" // 主机组maxCon="1000" minCon="10" // 连接balance="0" // 负载均衡writeType="0" // 写模式配置dbType="mysql" dbDriver="native" // 数据库配置switchType="1" slaveThreshold="100"><!--这里可以配置关于这个主机组的成员信息,和针对这些主机的健康检查语句--></dataHost><heartbeat>select user()</heartbeat> #对后端数据进行检测,执行一个sql语句,user()内部函数<writeHost host="hostM1" url="master:3306" user="mycat" password="Jack@123"><readHost host="hostS1" url="slave1:3306" user="mycat" password="Jack@123" /><readHost host="hostS2" url="slave2:3306" user="mycat" password="Jack@123" /></writeHost>url:可以写IP地址也可以写域名(但是要配置解析域名了才可以),端口号可不写,但是如果更换端口号了必须写;
balance 属性负载均衡类型,目前的取值有 3 种:1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。2. balance="1", 全部的 readHost 与 writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。3. balance="2", 所有读操作都随机的在 writeHost、readhost 上分发。4. balance="3", 所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力, #注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。writeType 属性负载均衡类型1. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切换到还生存的第二个writeHost,重新启动后已切换后的为准.2. writeType="1",所有写操作都随机的发送到配置的 writeHost,#版本1.5 以后废弃不推荐。

grant all on test1.* to jack@'%' identified by 'Jack@123';flush privileges;给用权限可以指定一些也可全部(全部但是不包括GRANT的权限)给指定库下所有权限可以,也可给全部库和表权限
启动Mycat
cd conf/vim wrapper.conf #在设置JVM哪里添加如下内容wrapper.startup.timeout=300 //超时时间300秒wrapper.ping.timeout=120启动:/usr/local/mycat/bin/mycat start #需要稍微等待一会Starting Mycat-server...jps #查看mycat是否启动13377 WrapperSimpleApp13431 Jps (显示两个就启动成功)netstat -lntp | grep java如果启动不成功查看错误日志,看是否内存过小启动不来还是配置问题
用一台新机器登录mycat查看是否能查看:
mysql -umycat -p’mycat@123’ -h mycat -P 8066
mycat默认端口是:8066
如果在show table报错:
mysql> show tables;
ERROR 3009 (HY000): java.lang.IllegalArgumentException: Invalid DataSource:0
解决方式:
登录master服务将mycat的登录修改为%
mysql> update user set Host = ‘%’ where User = ‘mycat’ and Host = ‘localhost’;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> flush privileges;
或者在授权用户mycat权限为.

若有收获,就点个赞吧
0 人点赞
