1.Linux 上安装 DataX 软件
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gztar zxf datax.tar.gz -C /home/datax/rm -rf /home/datax/datax/plugin/*/._*
- 当未删除时,可能会输出:[/home/datax/datax/plugin/reader/._drdsreader/plugin.json] 不存在. 请检查您的配置文件.
验证:
cd /home/datax/datax/bin
python datax.py ../job/job.json
2.DataX 基本使用
查看 streamreader —> streamwriter 的模板:
python /home/datax/datax/bin/datax.py -r streamreader -w streamwriter
输出:
输出:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
根据模板编写 json 文件
cat END > test.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [ # 同步的列名 (* 表示所有)
{
"type":"string",
"value":"Hello."
},
{
"type":"string",
"value":"河北彭于晏"
},
],
"sliceRecordCount": "3" # 打印数量
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8", # 编码
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "2" # 并发 (即 sliceRecordCount * channel = 结果)
}
}
}
}
3.通过 DataX 实 MySQL 数据同步
1)生成 MySQL 到 MySQL 同步的模板:
python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriter
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader", # 读取端
"parameter": {
"column": [], # 需要同步的列 (* 表示所有的列)
"connection": [
{
"jdbcUrl": [], # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接用户
"username": "", # 连接密码
"where": "" # 描述筛选条件
}
},
"writer": {
"name": "mysqlwriter", # 写入端
"parameter": {
"column": [], # 需要同步的列
"connection": [
{
"jdbcUrl": "", # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接密码
"preSql": [], # 同步前. 要做的事
"session": [],
"username": "", # 连接用户
"writeMode": "" # 操作类型
}
}
}
],
"setting": {
"speed": {
"channel": "" # 指定并发数
}
}
}
}
2)编写 json 文件:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"activity_name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/lottery?useUnicode=true&characterEncoding=utf8"
],
"table": [
"activity"
]
}
],
"password": "root",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"preSql": [
"truncate t_test"
],
"session": [
"set session sql_mode='ANSI'"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/lottery?useUnicode=true&characterEncoding=utf8",
"table": [
"t_test"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
3)验证
python datax.py ./test.json
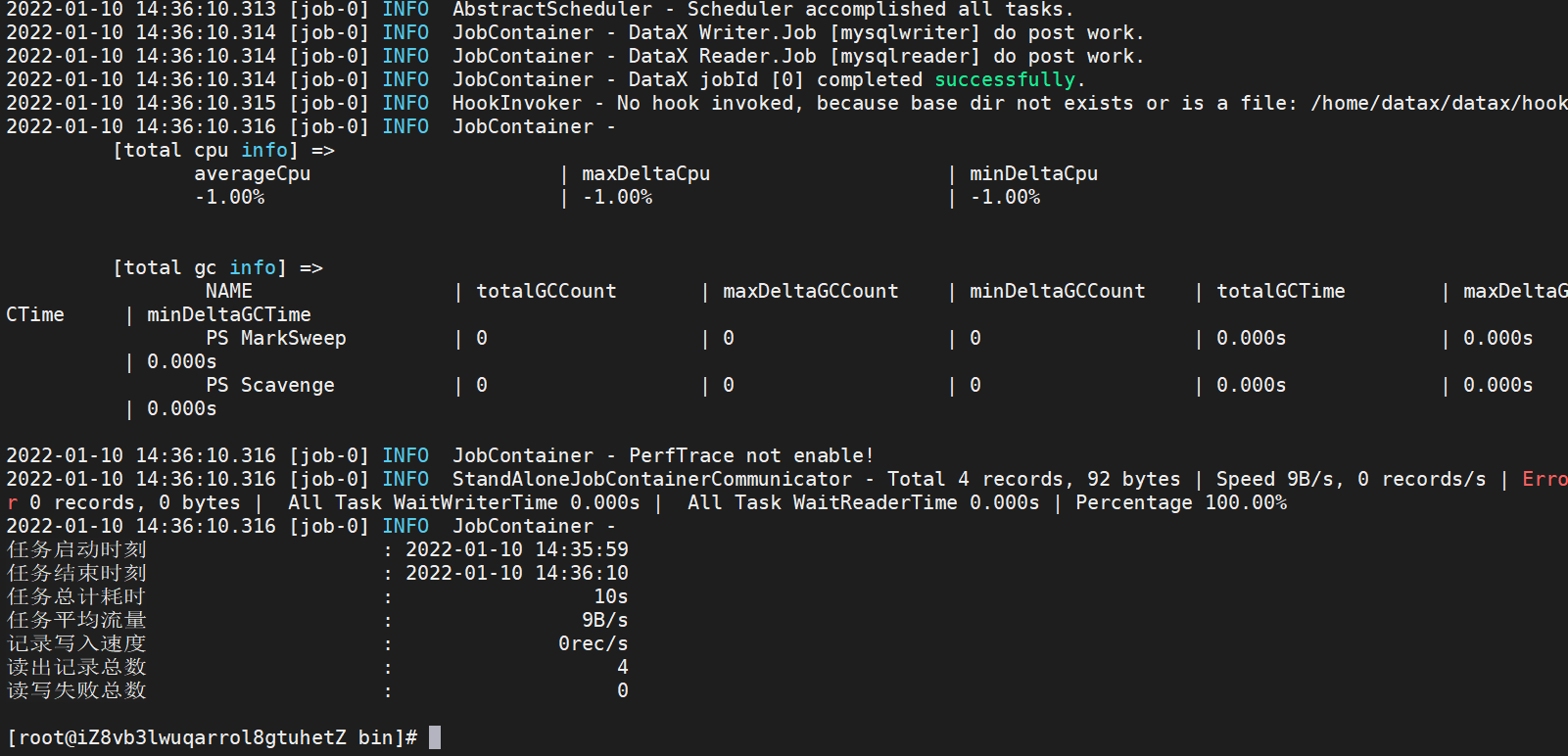
4.使用 DataX 进行增量同步
使用 DataX 进行全量同步和增量同步的唯一区别就是:增量同步需要使用 where 进行条件筛选。(即,同步筛选后的 SQL)
1)编写 json 文件:
vim where.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123123",
"column": ["*"],
"splitPk": "ID",
"where": "ID <= 1888" ,
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table": ["t_member"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table": ["t_member"]
}
],
"password": "123123",
"session": [
"set session sql_mode='ANSI'"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
- 需要注意的部分就是:where(条件筛选) 和 preSql(同步前,要做的事) 参数。
原文连接:
https://blog.csdn.net/weixin_46902396/article/details/121904705
bin 下的python 文件替换
datax.pydxprof.pyperftrace.py

若有收获,就点个赞吧
0 人点赞
