单服务引擎包含一个服务器运行的所有功能,能单独运行并服务一部分玩家。单服务引擎运行后,客户端通过网络通信将请求发送到服务器中,服务器通过并发模型将请求交给逻辑模块处理,逻辑模块通过序列化解码参数数据并将请求数据交给服务注册的RPC函数处理。
程序语言
目前游戏服务器开发语言使用比较广泛的组合是C/C++和Lua。C/C++属于静态语言,拥有很高的运行性能,但因为C/C++语法更倾向于计算机的理解方式,对程序员编写业务逻辑并不够友好,降低了产品的开发效率,而且C/C++热更方法比较有限,线上出问题时不能快速且方便的修复,可能要时不时的停服关机修复,比较影响游戏体验,因此引入语法更简洁、更方便而且支持打补丁的高级动态解释语言Lua。引入Lua后,C/C++的分工有了变化,一些要求高性能的服务器模块用C/C++编写,比如网络库、数学计算库以及局内实时战斗逻辑等,Lua负责一些对性能要求不高的模块,但业务逻辑量比较大的模块,这样的模块其实占游戏业务的很大一部分,比如游戏的一些外围系统:等级系统,背包系统,聊天系统等等。相比于Lua,其实个人更喜欢Python,Python比Lua拥有更简洁的语法、更高的容错以及更完善的函数库,在开发产品业务时,拥有更高的开发效率,所以Wind的游戏业务逻辑语言使用Python开发。
使用C/C++编写一些模块,可以很好解决服务运行效率问题,但C/C++没有自动内存管理,写逻辑时很容易发生内存泄漏,而且C/C++语法复杂,程序员上手难度较高,开发成本大,因此引入Golang语言。Golang以高并发著称,拥有比C++更简明的语法特性,可提升开发效率,同时Golang提供自动内存管理机制,极大的简化了程序员开发的难度。因此Wind使用Golang来开发一些对效率有要求的模块,目前Wind的网络库是Golang写的。一些对性能要求高的游戏业务你也可以使用Golang来开发,比如战斗功能。
Python与Golang的交互
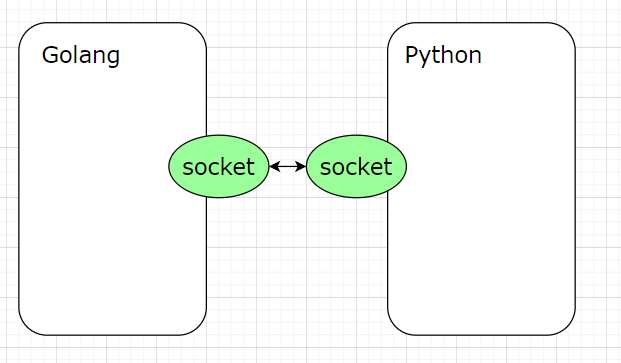
Wind的网络库由Golang编写,目前支持TCP,之后会支持多协议。每个客户端连接过来后,Golang会开一个线程去处理网络数据,有数据发过来后,Golang会将数据交给Python逻辑端处理。这里有个问题,就是Python线程和Golang线程是怎么进行交互的?Wind服务器引擎的主线程是在Python端,在起服务器时加载Golang编写的网络动态库(so文件或者DLL文件)并且开启Golang网络线程处理客户端数据,目前Python与Golang的数据交互使用Socket通信交互,Python端启用一个TCP端口,Golang连接这个端口并且将数据传送给Python端,同样的Python端也通过这个Socket来将数据传送给Golang端。当然你也可以换Python与Golang的交互方式,比如一些内存间的通信方法,内存间的通信可以加快Python与Golang的交互,目前已知的是ZMQ的管道通信。
并发模型
游戏客户端所做的工作基本上是将数据按一定逻辑显示在屏幕上,单个客户端并不需要与太多的服务器进行交互,多的也就两三个左右,所以客户端基本上对并发没有太多的要求。但是服务器就不一样了,同一个服务器要服务的客户端可能是上千个,甚至可能是上万个,这时候就需要并发模型来合理分配服务器的计算资源并正确的为客户端服务。
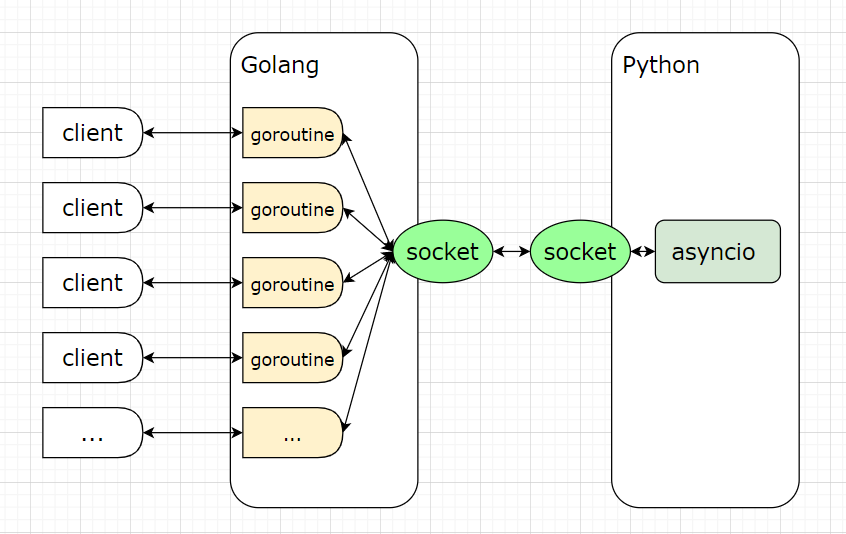
为了最大化利用物理机的多核资源,一般会有两种并发模型,一种是单进程多线程模型,这种模型通常是单个进程中存在多个游戏服务,每个服务分配一个核进行计算。游戏界应用这种并发模型比较成熟的是云风的Skynet,Skynet启用多个工作线程来处理服务的事件,各个线程间基于消息传递来通信。这种单进程多服务的缺点是,服务之间的隔离比较弱,服务之间共用了进程的数据,单个服务发生问题时可能影响其他服务,这样的设计也并不适合云部署,云部署所满足的一个基本要求就是服务间相互独立,每个服务是云调度的基本单位,每个服务可自由的被调度,因此更适合云部署的是多进程单线程模型,每个进程是一个服务,同一台机器可以起多个进程来利用多核优势,同时单线程中使用异步来处理数据I/O,提高服务器的并发。
那么Wind使用的是哪个模型了? Wind使用是的混合模型,Wind是一个进程一个服务,网络库利用Golang的高并发特性,每个客户端连接启用一个线程来读取数据,同时为了减低业务逻辑编写难度,避免多线程锁问题,Python端使用单线程异步协程来编写业务逻辑。Golang网络层的多线程消息数据会通过一个队列来发给Python协程(asyncio)。
Python协程
Python协程本质上是异步,只不过这个协程是语言层面上的支持,编写游戏业务时更清晰、更简单。Python启动线程时,会启动一个事件循环,这个循环会一直检测是否有事件可以处理,如果某个任务要进行I/O(磁盘I/O或者网络I/O),那么这个任务会被挂起,直到对应数据到来时,这个任务又会被事件循环处理。
import asyncioasync def main():print('Hello ...')await asyncio.sleep(1)print('... World!')loop = asyncio.get_event_loop()loop.create_task(main())loop.run_forever()
使用异步协程编写游戏业务逻辑时,同一个时刻只能有一个客户端请求被处理,降低了开发难度,与协程搭配使用的是各个模块的单例化
网络通信
实现游戏服务器时,主要会接触到的是传输层以上的一些网络协议,传输层协议包括UDP协议和TCP协议。UDP是一种无连接的协议,没有可靠性保证、顺序保证以及流量控制,但正是因为控制项比较少,UDP在数据传输过程中延迟小,速率高。游戏中一些对可靠性要求不高,但要求高速率的业务可以使用UDP传输,比如游戏语音服务。
TCP是面向连接的、可靠的、基于字节流的传输层通信协议,TCP通过序号确认机制、超时重传机制、重复累计确认机制和检验和机制来实现可靠性传输,同时提供流量控制和拥塞控制来控制源端的发送速率,以确保对端能正确接收。相对于UDP啥都没做来说,TCP什么事都做了,导致TCP传输速率低,延迟大。游戏是实时性应用,游戏的一些外围功能(背包功能、个人信息)时延要求不高,TCP够用了,但是对于游戏战斗这类高实时性功能,TCP的延迟太大了,会导致游戏战斗时体验会非常差。
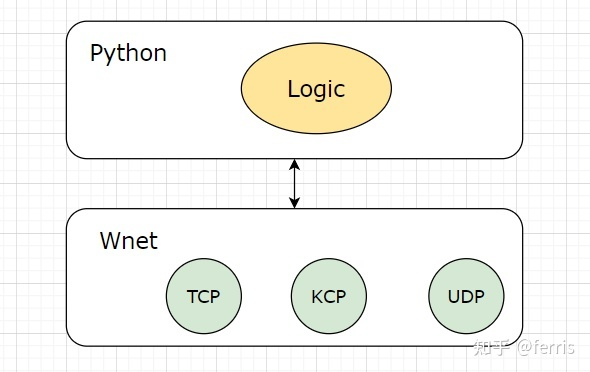
为了解决TCP传输延时大的问题,游戏界通常会在UDP之上实现一个延时更低的可靠性传输协议,比如KCP,Enet。KCP能以比TCP浪费10%-20%的带宽的代价、换取平均延迟降低30%-40%,且最大延迟降低三倍的传输效果。ENet是专门为多人第一人称射击游戏Cube开发的可靠性传输协议,Enet提供连接管理,Enet最大的特点是提供多通道机制,每个通道包传送独立,单个通道会确保前一个序号消息到达才会发送下一个序号消息,以保证可靠性。
通常游戏会集成好几个传输协议到网络层,以便在不同需求场景下切换,比如集成UDP、KCP和TCP到网络传输层。Wind的网络层也会集成多个网络协议,以便在不同游戏场景中进行切换。
远程函数调用(RPC)
在单机游戏中,如果你要实现某个游戏效果,你可以通过函数名字直接调用对应函数来实现效果,但在网络游戏中,有些游戏效果需要向远端的服务器请求计算或者数据(比如匹配,背包)来实现,这时就会需要远程函数调用。远程函数调用通常发生在同一个共享网络下的不同地址空间中,比如不同物理机。游戏的远程函数调用通常采用Request/Response通信模式,每个远程函数名字以Request/Response(也可以用其他结尾,比如Packet)结尾,以此来区分本地函数。
封装好远程函数调用库后,写代码时就像写本地函数调用一样,程序员并不需要关心与远端的交互细节。但与本地函数调用不同的是,远程函数调用需要经过网络传输,网络传输增加了调用的时延与不确定性,为了防止主线程逻辑卡死,远程函数调用一般设计成异步调用,Request包发出后,不会等待包的返回,而是Response包返回后在处理之前的逻辑。
实现远程函数调用需要两个功能支持,一个是序列化功能,一个是协议工厂功能。
序列化
序列化是一个将数据结构和对象信息转化成可以存储和传输形式的过程。我们在写代码时通常以对象的形式读取数据,因为对象更符合人类思维习惯,我们能更快编写程序代码。但是对象信息数据通常是不连续的内存,不能直接进行存储或者传输,所以序列化需要将对象数据转化成二进制或者连续的字符串。序列化技术有很多种,比较常见的是Json、Xml、Protobuf等。Json是直接将对象转化成字符串,拥有很强的可读性,但缺点也很明显,那就是序列化后的数据太大了,导致需要的网络带宽也会加大,而且Json不安全,没有错误处理机制,你可以将同一个字段值转化成其他类型的数据。现在比较大型的游戏通常采用的序列化是Protobuf,Protobuf是协议定义型的,在使用时你需要定义你的数据类型,而且因为Protobuf在序列化时是用ID作为标识符,而不是字段名来标识,所以序列化后的二进制数据很小。对于游戏来说,Protobuf支持函数引用定义,解决了函数重复定义的问题。使用Protobuf后也可以用协议定义文件来生成MD5,以次来标识不同游戏版本的网络协议接口,以防老版本的客户端连接新版本的服务器,造成数据错误。
协议工厂
Json序列化时可以将函数名序列化进去,数据包到达服务器后,服务器根据函数名调用注册的RPC函数,但Protobuf序列化时一般不会直接将函数名字符串序列化进去,因为函数名字符串占用空间太大了,为了减少传输的数据,一般会有一个映射关系,将函数名映射成一个int型的ID,网络传输数据时,使用ID来替代函数名进行网络传输。函数名与ID的相互映射就是协议工厂。定义好函数协议文件后,将函数协议文件转化成代码文件时,通常会给每个函数协议分配一个ID,然后生成一个协议工厂代码文件,这个协议工厂代码就用来根据ID转化成函数名并调用对应RPC函数。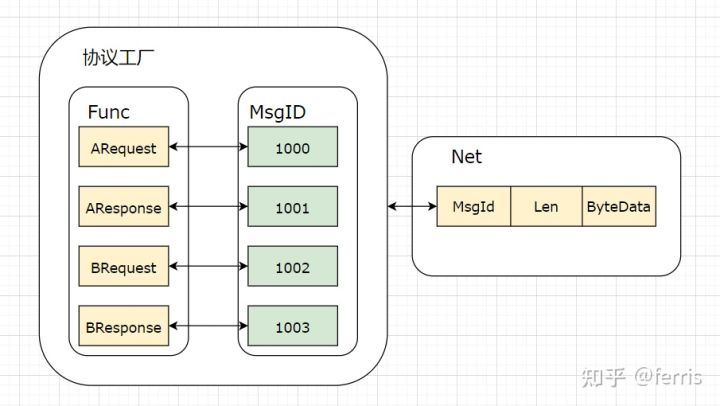

若有收获,就点个赞吧
0 人点赞
