一、绪论
1.1、数据结构三要素
- 逻辑结构(集合、线性、树形、图状) 定义
- 数据运算 操作
- 存储结构(顺序、链式、索引、散列) 实现
1.2、算法及计算
算法:有穷、确定、可行、输入输出
好算法:正确、可读、健壮、高效率低储存
二、线性表(算法大题重点)
2.1、线性表的基本操作
InitList(&L) // 初始化Length(L) // 表长LocateElem(L,e) // 按值查找GetElem(L,i) // 按位查找ListInsert(&L,i,e) // 插入ListDelete(&L,i,&e) // 删除PrintList(L) // 打印Empty(L) // 判空DestroyList(&L) // 销毁
2.2、顺序表
特点:
- 随机访问
- 存储密度高
- 拓展容量不方便
- 删除、插入移动大量元素
// 静态存储#define MaxSize 50typedef struct{ElemType data;int length;}SqList;// 动态存储#define InitSize 100typedef struct{ElemType *data;int MaxSize,length;}SeqList;
时间复杂度
- 插入:O(n)
- 删除:O(n)
- 按值查找:O(n)
- 按位查找·:O(1)

2.3、单链表
特点:
- 不需要连续的存储单元
- 删除、插入不需要大量移动
- 失去了 随机存储 的优点
typedef struct LNode{ELemType data;struct LNode *next;}LNode,*LinkList;
时间复杂度
- 建表、查找、表长都是 O(n)
- 插入和删除的基本操作是 O(1),但是前提要查找到需要操作的结点处,导致 O(n)
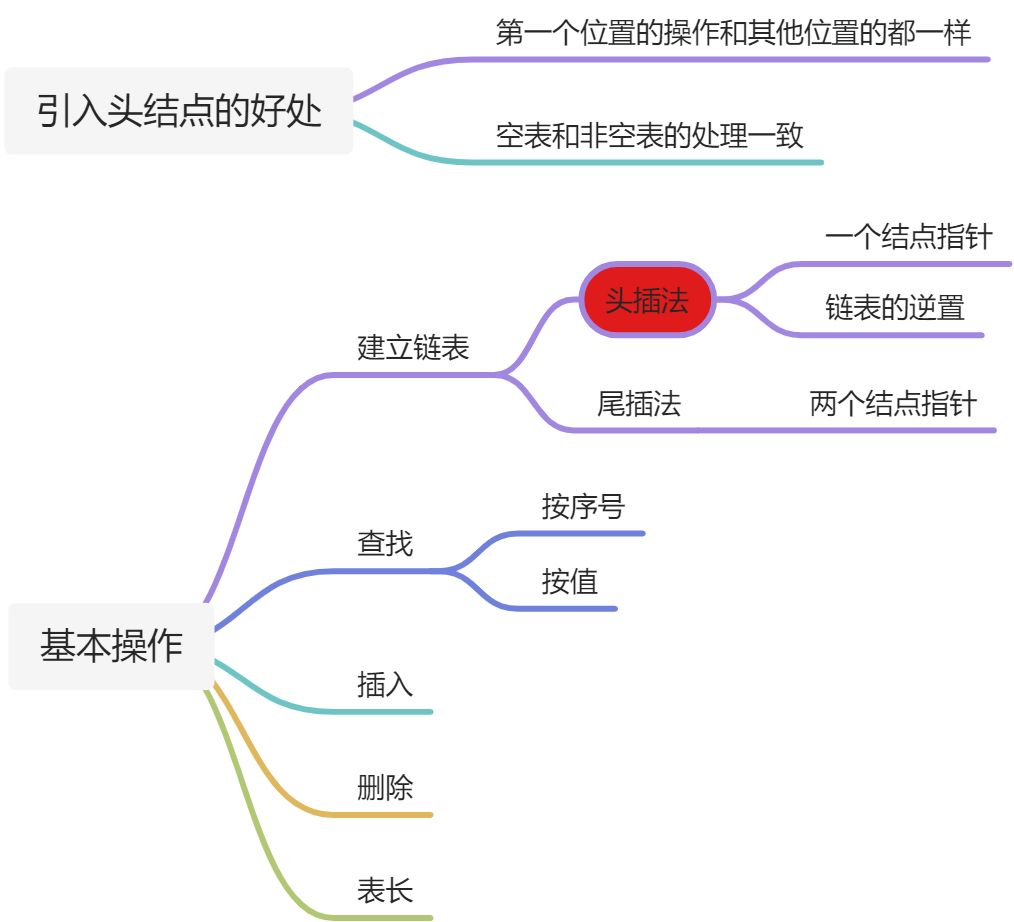
2.4、双链表
typedef struct DNode{ElemType data;struct DNode *prior,*next;}DNode,*DLinkList;


2.5、循环链表
- 循环单链表
- 任何一个位置 插入 / 删除 都是等价的
- 可以从任意一个位置遍历整个链表
- 有时:在 头/尾 处进行操作,此时只需要对单链表设置 尾指针 即可大大提高效率
- 循环单链表
- 循环单链表和双链表的结合
2.6、静态链表
特点:
- 用数组的方式实现链表
- 增删不需要移动大量数据
- 不能随机存取
- 容量固定不变,要预先分配空间
#define MaxSize 50typedef struct{ElemType data;int next;}SLinkList[MaxSize];
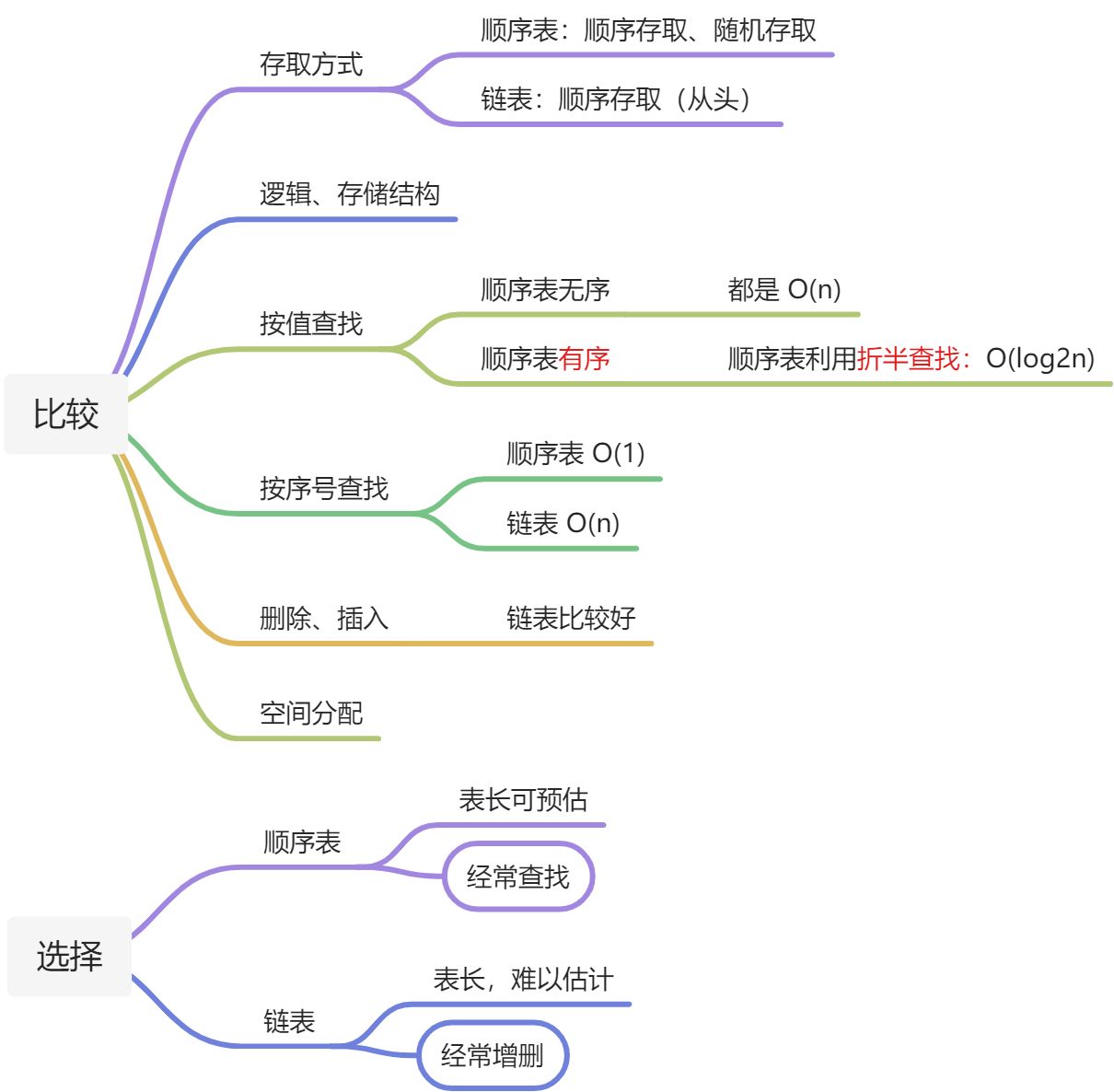
2.7、顺序表和链表总结(大题的思路)
三、栈(LIFO)
3.1、栈的基本操作
InitStack(&S) // 初始化StackEmpty(S) // 判空Push(&S,x) // 入栈Pop(&S,&X) // 出栈GetTop(S,&x) // 读栈顶元素DestroyStack(&S) // 销毁栈
3.2、顺序栈
#define MaxSize 50typedef struct{ElemType data[MaxSize];int top;}SqStack;
注意初始化时,栈顶从 -1 开始 还是从 0 开始
共享栈:
- 更有效的利用存储空间
- 存取数据:O(1)
3.3、链栈
优点:
- 便于多个栈共享存储空间和提高效率
- 不存在栈满溢出
- 入栈、出栈都在表头进行
typedef struct Linknode{ElemType data;struct Linknode *next;}*LiStack;
四、队列(FIFO)
4.1、队列的基本操作
InitQueue(&Q) // 初始化QueueEmpty(Q) // 判空EnQueue(&Q,x) // 入队DeQueue(&Q,&x) // 出队GetHead(Q,&x) // 读对头元素
4.2、顺序存储
#define MaxSize 50typedef struct{ElemType data[MaxSize];int front,rear;}SqQueue;
rear 在不同题目可能有不一样的要求:
- 指向队尾的下一个位置
- 指向队尾
4.3、循环队列
利用 取余运算 来实现循环队列
区分队空还是队满:
- 牺牲一个单元来区分
- 结构体中增加一个记录数据个数的成员
- 增加一个tag标签,表示队满还是队空
4.4、链队
typedef struct LinkNode{ElemType data;struct LinkNode *next;}LinkNode;typedef struct{LinkNode *front,*rear;}LinkQueue;
4.5、双端队列
分为两种:
- 输出受限的双端队列
- 输入受限的双端队列
五、栈和队列的应用
5.1、括号匹配(栈)
算法思想如下:
- 初始空栈,顺序读入括号
- 若是右括号,则将栈顶与之匹配的进行消除,或者因为不合法而退出程序
- 若为左括号,则作为需要匹配的括号而压入栈中,直至最后匹配完,栈空成功,否则不匹配
5.2、表达式求值(栈)(重点)
- 中缀表达式:要依赖运算符优先级,还要处理括号
- 后缀表达式:只有操作数和运算符
要熟练掌握:中缀表达式 和 后缀表达式 的互相转化
5.3、递归应用(栈)(最后执行先结束的原则)
适用于:可以把原始问题转化为属性相同,但规模较小的问题
必要条件:边界条件(递归出口)、递归表达式(递归体)
缺点:效率不高、递归次数过多会导致溢出
优点:代码简单
5.4、层次遍历(队列)(重点)
六、数组(难点)
存储方式:
- 行优先
- 列优先
6.1、特殊矩阵
6.1.1、对称矩阵
6.1.2、三角矩阵
考查的点:
七、串
7.1、简单的模式匹配算法(熟悉代码)
采用定长顺序存储结构
最坏时间复杂度:O(mn)(m、n 分别是主串和模式串的长度)
7.2、KMP 算法(熟悉思想)
会 next 数组 和 nextval 数组 的手写
最坏时间复杂度:O(m+n)
优点:主串不回溯
八、树
8.1、树的基本概念
基本概念:
- 树的定义是递归的
- 树是一种递归的数据结构
- 一种分层结构
树的性质:(重点:要记!!!)
- 总结点数 = 所有结点度数和 + 1 (最重要)
- 度为 m 的树,第 i 层至多有 mi-1 个结点
- 高度为 h 的 m 叉树,至多有 (mh-1)/(m-1) 个结点,至少有 h 个结点
- n 个结点的 m 叉树,hmin = logm(n(m-1)+1)的向上取整
- 高度为 h,度为 m,至少有 h+m-1 个结点
解决树结点与度之间关系的考题:
- 总结点数 = n0+n1+n2+n3+…+nm
- 总分支数 = 1n1+2n2+3n3+…+mnm
- 总结点数 = 总分支数 + 1
8.2、二叉树
8.2.1、基本概念
- 有序树
- 可以为空(注意:图不可以为空)
特殊二叉树:(重难点!!!)
- 满二叉树
- 高度 h
- 结点数 2h-1
- 度全为 2
- 左孩子 2i
- 右孩子 2i+1
- 双亲 i/2 且向下取整
- 完全二叉树
- 若 i <= n/2 且向下取整,结点 i 就是分支结点,否则为叶子结点
- 叶子结点在:层次最大的两层
- 度为 1 的结点,只有 1 个
- i 结点为叶子结点或者只有左孩子,说明:编号大于 i 的都是叶子节点
- n 是奇数:分支结点都有左孩子和右孩子
- n 是偶数:最后一个分支结点,只有左孩子
- 二叉排序树:用于元素的排序、搜索
- 平衡二叉树:能有更高的搜索效率,树上任一结点左右子树深度差 <= 1

二叉树的性质:
- n**0 = n2** + 1
- 非空二叉树第 k 层,至多 2**k-1 **个结点
- 高度 h ,至多 2**h**-1 个结点
完全二叉树:
- n 个结点的完全二叉树的高度 log2n+1(log的部分:向下取整)
- 完全二叉树,结点 i 所在的层次 log2i+1(log的部分:向下取整)
- 完全二叉树,n**0 + n2 ** 一定为奇数
- 完全二叉树,n**1 = n2** + 1
8.2.2、二叉树的顺序存储
完全二叉树和满二叉树采用顺序存储比较合适
typedef struct TreeNode{int value;bool Empty;};
8.2.3、二叉树的链式存储
typedef struct BiTNode{ElemType data;struct BiTNode *lchild,*rchild;}BiTNode,*BiTree;
缺点:找到父节点,只能从头遍历
——> 优化:三叉链表,加入struct BiTNode *parent;属性
8.2.4、二叉树的遍历
二叉树递归特性:
- 要么是一个空二叉树
- 要么是一个非空二叉树
树的遍历:树结构 转 线性结构
遍历方法:(考研是基于这三种的延申、变种)
- 先序遍历(根 左 右)
- 中序遍历(左 根 右)
- 后序遍历(左 右 根)
很类似于:入栈、出栈 时间复杂度:O(n) 空间复杂度:O(n)(递归工作栈的深度:树的深度)
一种题型: 后序遍历中,访问一个结点时,栈中的结点必定为其所有祖先,刚好构成一个:从根到该结点的一条路径
- 求根到结点的路径
- 求两个结点的最近公共祖先
- 等等
层次遍历:
- 需要借用队列,来完成相应的操作
- 考题:
- 对已知的树,求结点双亲
- 求结点孩子
- 求结点深度
- 求二叉树叶子结点个数
- 判断两棵二叉树是否相同
- 等等
由遍历序列构建二叉树:(必须由中序,才可以唯一构建)
- 后序 + 中序
- 先序 + 中序
- 层序 + 中序
8.2.5、线索二叉树
知识点:
- 利用二叉树的空指针,完成线索化
- 缺陷:遍历时,我们可能只知道某个结点,但是我们无法知道其根节点,就只能从头遍历
- 引发的缺点:程序中反复找前驱、后继会很耗时
- 解决:
- 土办法:定义两个指针,其中一个指向前驱
- 好方法:创建线索二叉树
- 线索二叉树:可以加快查找结点前驱和后继的速度、
- 线索二叉树实质:遍历一次二叉树
typedef struct ThreadNode{ElemType data;struct ThreadNode *lchild,*rchild;int ltag,rtag;}ThreadNode,*ThreadTree;
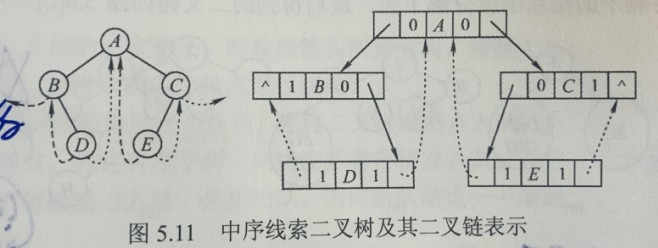
8.3、树
三种存储结构:
- 双亲表示法
- 孩子表示法
- 孩子兄弟表示法
8.4、树、森林与二叉树的转换
8.5、树和森林的遍历
树:
- 先根遍历
- 后根遍历
- 层次遍历
森林:
- 先序遍历
- 中序遍历
8.6、哈夫曼树
知识点:
- 带权路径长度(WPL)最小二叉树:哈夫曼树、最优二叉树
- 每个初始结点最终都成为叶结点,且权值越小的结点到根节点的路径长度越大
- 构造过程中,共建了 n-1 个结点,总结点数 2n-1
- 哈夫曼树不存在度为 1 的点
哈夫曼编码:
- 固定长度编码
- 可变长度编码:对频率高的字符赋以短编码
- 是一种被广泛应用而且非常有效的数据压缩编码
- 前缀编码: 0 、1
- 权值为其出现的频数或者次数
- 可能考查:压缩百分之多少的数据
8.7、并查集(考纲新增,很大可能会考)
并集 + 查集
基本操作:1.Initial(S);2.Union(S,Root1,Root2);3.Find(S,x);
知识点:
- Find 的用处
- 给一个元素,判断属于哪个集合
- 给两个元素,判断是否属于同一个集合
- 森林:m 棵互不相交的树的集合
- 一棵树成为另外一棵树的孩子
- 利用双亲表示法(顺序存储)
- 每个子集合以一棵树表示
- 双亲指针指向另一个集合的根节点
8.8、需要掌握的思想
- 统计二叉树中,度为 1、2、0 的结点个数
- 统计二叉树,高度、深度
- 删除二叉树所有叶子结点
- 计算给定结点所在层次
- 计算二叉树中最大元素的值
- 交换二叉树所有结点的左右孩子
- 以先序遍历,输出二叉树所有结点的数据值和所在层次
九、图
十、查找
10.1、顺序查找
10.2、折半查找
10.3、分块查找
10.4、树型查找
10.5、B树
10.6、散列表
十一、排序


简单选择、希尔、快排、堆排:不稳定
插入排序

11.1、直接插入排序
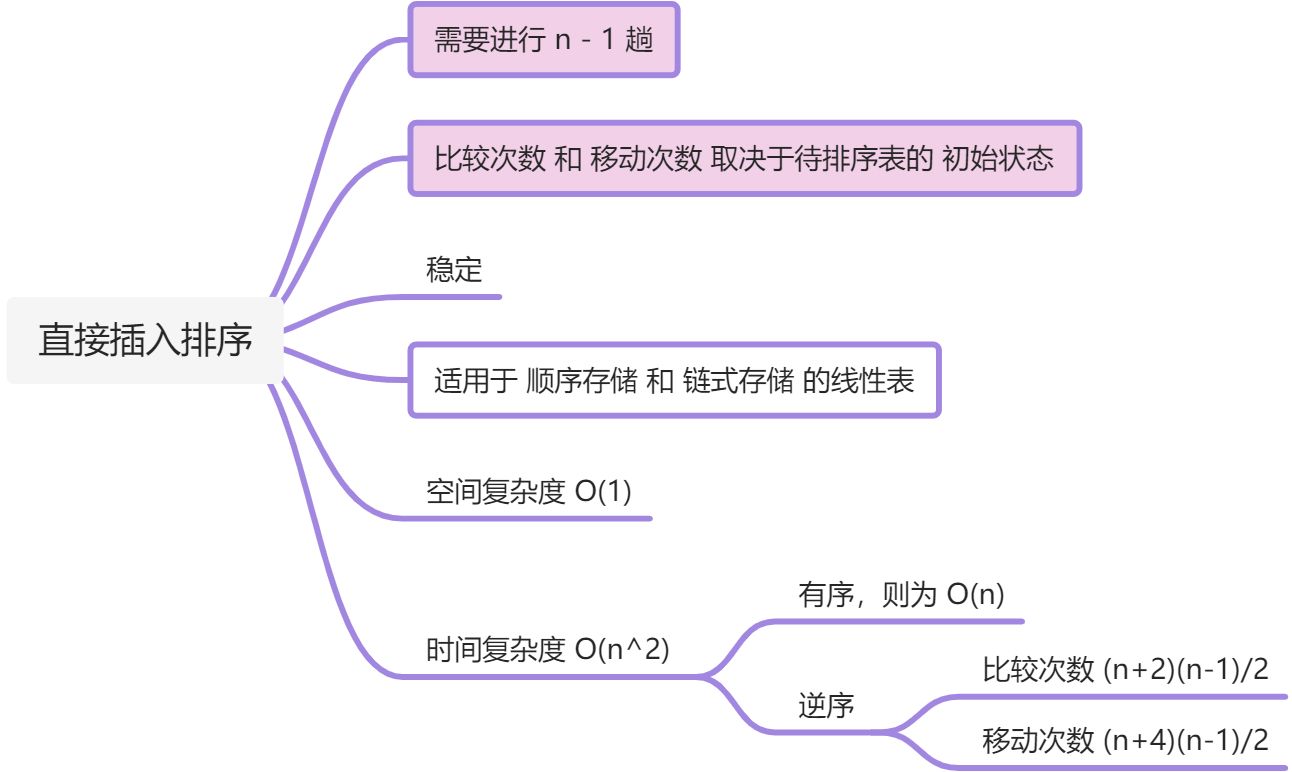
算法思想:
- 将要插入的数据存储于哨兵
- 哨兵 跟前面依次比较
- 若小于 则前面依次向后覆盖
- 直至大于前面的为止,或者说到头了
void InsertSort(ElemType A[],int n){int i,j;for(i = 2;i <= n;i++){if(A[i] < A[i-1]){ // 若 A[i] 小于前一个值A[0] = A[i]; // 将 A[i] 存下来for(j = i-1;A[0] < A[j];--j) // 判断 A[i] 前面是否还有比他小的值A[j+1] = A[j]; // 若由比 A[i] 小的值,就不断向后覆盖A[j+1] = A[0]; // 将哨兵的数据赋值回来}}}
11.2、折半插入排序

算法思想:
- 每插入一个数据都设置头尾标志
- 对插入前,已经排序的数据进行折半查找
- 直至找到“前小后大”的位置
- 查到的当前位置全部向后移动
- 哨兵值覆盖当前位置
void InsertSort(ElemType A[],int n){int low,mid,high,i,j;for(i = 2;i <= n;i++){A[0] = A[i]; // 需要插入的数据存储在哨兵low = 1;high = i-1; // 已经有的元素的头和尾while(low <= high){ // 就是折半查找,查找要插入的元素应该插入什么地方mid = (low + high) / 2;if(A[mid] > A[0]) // 比中间的小,查左边的(默认递增有序)high = mid - 1;else // 比中间的大或者等于,查右边的(也保证了稳定性)low = mid + 1;}for(j = i - 1;j >= high + 1;--j) // 查到位置后,把当前位置以及后面所有,都向后移动A[j+1] = A[j];A[high+1] = A[0]; // high+1 就是 low ,把当前位置用哨兵值覆盖}}
11.3、希尔排序
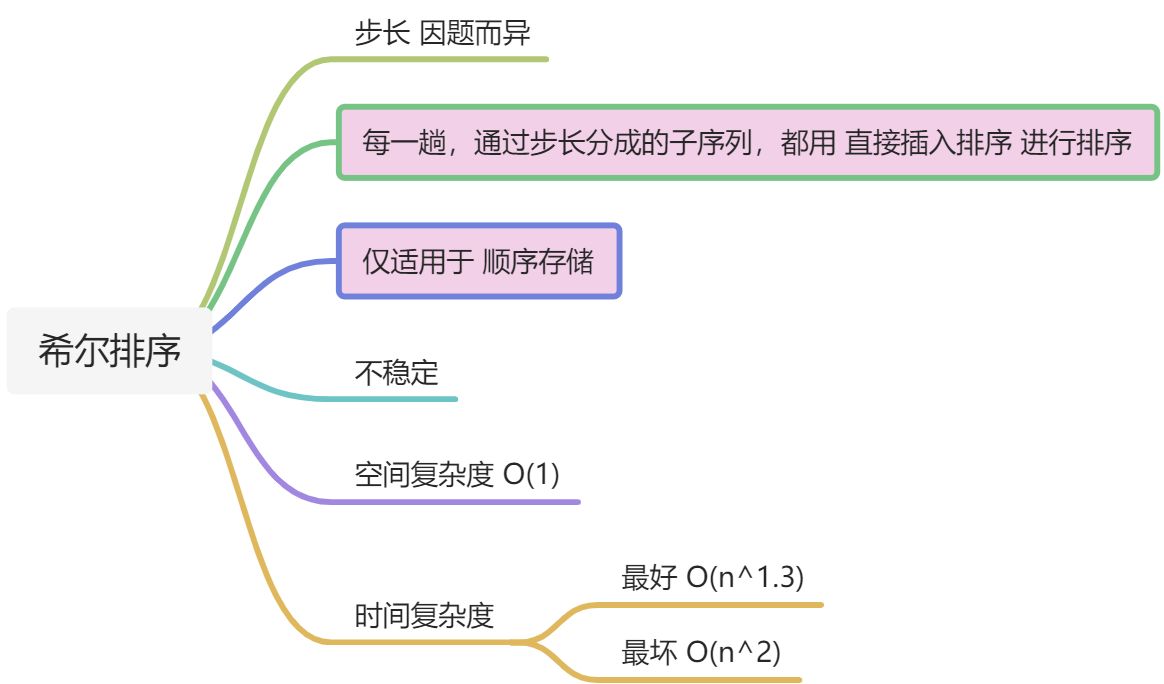
交换排序
11.4、冒泡排序
11.5、快排
选择排序
11.6、简单选择排序
11.7、堆排
其他排序
11.8、归并排序
11.9、基数排序

若有收获,就点个赞吧
0 人点赞
