1. SQL关键字用法
1.1 distinct 去重复
用法 select distinct name from t_user;
1.2 Where 条件查询
where 条件查询 可以使用运算符可以使用 between 在某个范围内查询 t_user表中的 年龄15-30 之间的值用法 select * from t_user where age between 15 and 30;like 模糊查询% 表示多个字值,_ 下划线表示一个字符;M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。%M% : 表示查询包含M的所有内容。%M_ : 表示查询以M在倒数第二位的所有内容。查询 t_user表中name 包含姓李的内容用法 select * from t_user where name like '李%';in 指定针对某个列的多个可能值查询 t_user表中年龄等于 25,30,40的值用法 select * from t_user where age in (25,30,40)and 第一个条件和第二个条件都成立,则 and 显示一条记录查询 t_user 表中年龄在20-30之间的女性 和 25-30之间的男性select age,sex from t_userage between 20 and 30 and sex = '女'or age between 25 and 30 and sex = '男'or 第一个和第二个条件只要有一个成立,则 or 显示一条记录查询 t_user表中年龄大于30岁的(不包括30)名字姓王的人select age,name from t_user where age>30 or name like '王%'
1.3 order by 关键字
order by 用于对结果集按照一个列或者多个列进行排序 默认是升序排序,如果需要倒序则要配合 desc 使用查询 姓名和年龄 年龄要排序select name,age from t_user order by ageorder by desc 对结果集进行倒序排序查询 所有的姓名,年龄。排序,年龄要倒序select name,age from t_user order by age desc;order by 多列查询所有的信息 年龄和姓名列排序select name,age from t_user order by name,age
1.4 insert into 新增
insert into 向表中插入新数据 id 自增有两种写法第一种写法insert into t_user values (值1,值2,值3 ....)insert into t_user values ('张三',20,1.73)第二种写法insert into t_user (字段1,字段2..) values (值1,值2)insert into t_user (name,age,height) values ('张三',20,1.73)
1.5 update 修改
update 用于修改表中已经存在的内容修改id = 3 的姓名 年龄 身高update t_user set name = '张山',age = 20, height = 1.79 where id = 3
1.6 delete 删除
delete 用于删除表中的行根据id = 3 进行删除的操作delete from t_name where id = 3;
1.7 select limit 限制查询
查询前两条数据select name,age from user limit 2
1.8 通配符
1. % 代替0个或者多个字符2. _ 替代一个字符3. [charlist] 字符列中任何单一字符4. [^charlist] 或者 [!charlist] 不在字符列中的任何单一字符
1.9 SQL 别名
把列起别名name 变成 tnameselect name as tname from t_user把表起别名select name(s) from t_user as t_name
2.0 连接 JOIN
把两个表或者多个表结合起来语法select user.name,user.age,student.address,student.height from t_user inner join t_student on t_user.id = t_student.idinner join : 如果表中有至少一个匹配,则返回行left join : 即使右表没有匹配,也从左表返回所有的行right join : 即使左表没有匹配,也从右表返回所有的行full join : 只要其中一个表中存在匹配,则返回行
2.1 LEFT JOIN 左连接
LEFT Join 从左表返回所有的行,即使右表中没有匹配,也会返回左边的内容,如果右表没有匹配则返回Null语法有两种1. select name,age from t_user left join t_student on t_user.name=t_student.name2. select name,age from t_user left outer join t_student on t_user.name=t_student.name
2.2 Right Join 右连接
Right Join 从右表返回所有的行,即使左表中没有匹配,也会返回右边的内容,如果左表没有匹配则返回Null语法有两种1. select name,age from t_user right join t_student on t_user.name=t_student.name2. select name,age from t_user right outer join t_student on t_user.name=t_student.name
2.3 Inner Join
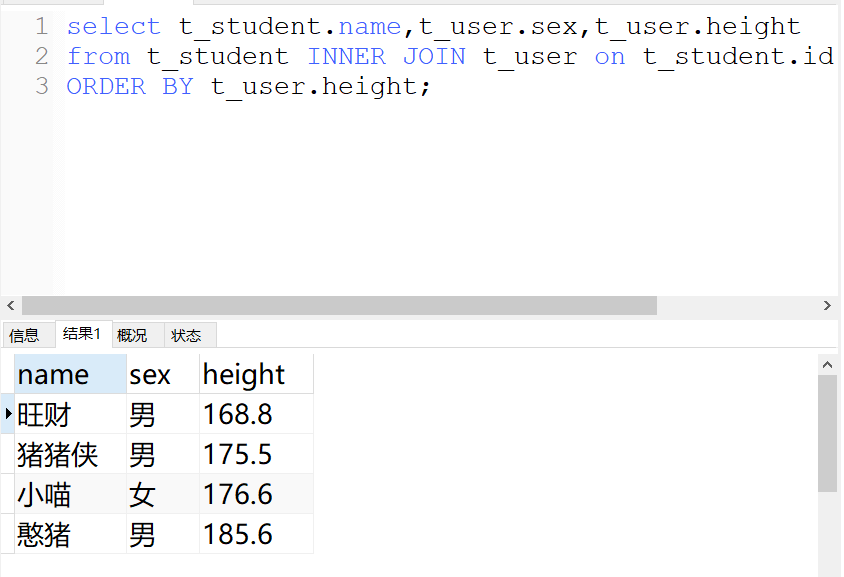
inner join 关键字在表中存在至少一个匹配时返回查询 t_student的名字 和 t_user中的性别和身高并且按照身高进行排序select t_student.name,t_user.sex,t_user.hightfrom t_student inner join t_user on t_student.id = t_user.idorder by t_user.hight;
2.1 union
union :合并两个或者多个select查询语句的结果注:union 内部的每个select语句必须拥有相同数量的列,列也必须拥有相似的数据类型同时每个select语句的列顺序必须相同语法:select name from t_user;unionselect name from t_student;注:默认的 union会选取不同的值,如果允许选取重复的值 则需要使用union all查询用户和学生的所有爱好(重复) 并排序select hobby from t_userunion allselect hobby from t_studentorder by hobby

2.2 insert into select
insert into select 可以从一个表所有复制信息到另一个表中不会影响目标表任何已存在的行语法:insert into t_userselect * from t_student;
2.3 create database
create database :用于创建数据库语法 create database 数据库名称create datavase my_sql
2.4 create table
create table 创建表语法 create table 表名create table user(id int,name varchar(125),sex int(10))
2.5 sql约束
Not null
not null 指某列不能存储null值
2.6 unique
unique 保证某列的每行必须有唯一值
2.7 primary Key
primary Key : NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
2.8 foreign key
foreign key : 保证一个表中的数据匹配另一个表中的值的参照完整性
2.9 check
check : 保证列中的值符合指定的条件
3.0 default
default : 规定给没有列赋值的时候 设置一个默认值
3.1 create index 创建索引
create index 创建一个简单的索引 允许使用重复的值语法:create index index_name on t_user
3.2 drop index 删除索引
drop index 可以删除索引语法: ALTER TABLE table_name DROP INDEX index_name

若有收获,就点个赞吧
0 人点赞
