数组排序
时间复杂度
我们说的更多的是通过 O(nlogn) 以及 O(n) 等来衡量。其实大多数时候我们对此并未建立形象的认知,到底哪一种算法更快、更好呢?下面是一张时间复杂度的曲线图。
图中用颜色区分了最优的、一般的以及比较差的时间复杂度,可以看到有这几种分类:Excellent、Good、Fair、Bad、Horrible,通过这张图可以一目了然。因此你在面试或者日常工作中编写代码的时候,要努力将代码的时间复杂度维持在 O(nlogn) 以下,要知道凡是超过 n 平方的时间复杂度都是难以接受的。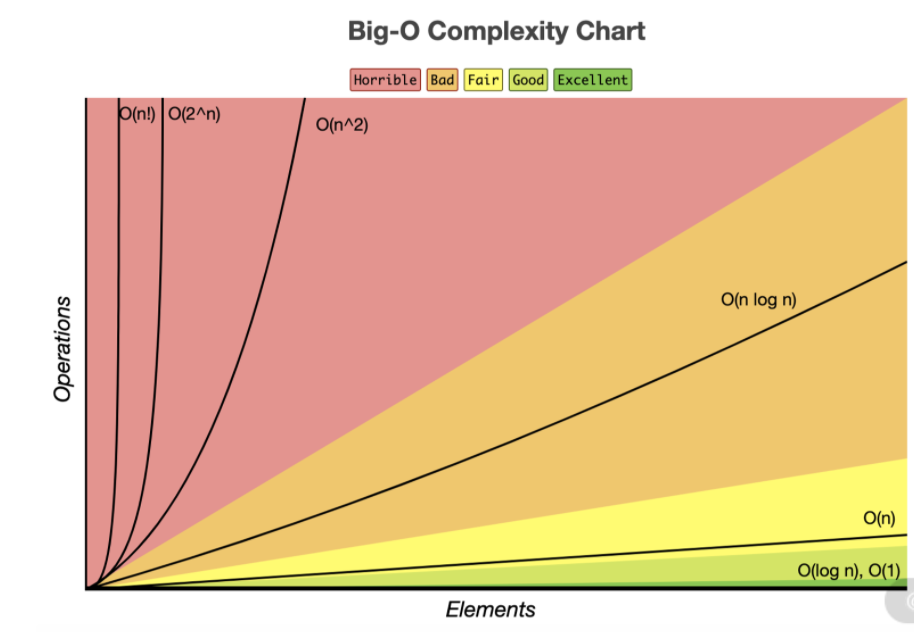
空间复杂度
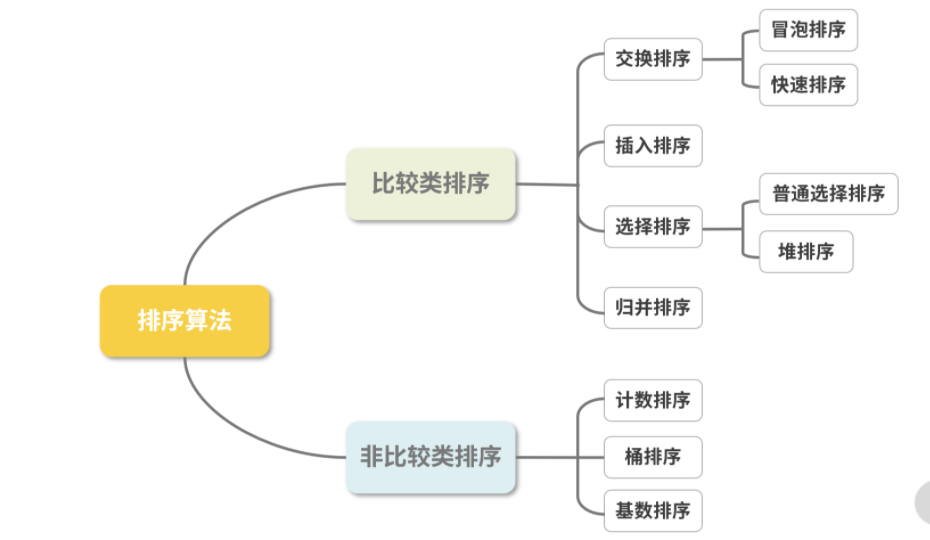
各种js排序实现
- 比较类排序:通过比较来决定元素间的相对次序,其时间复杂度不能突破 O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
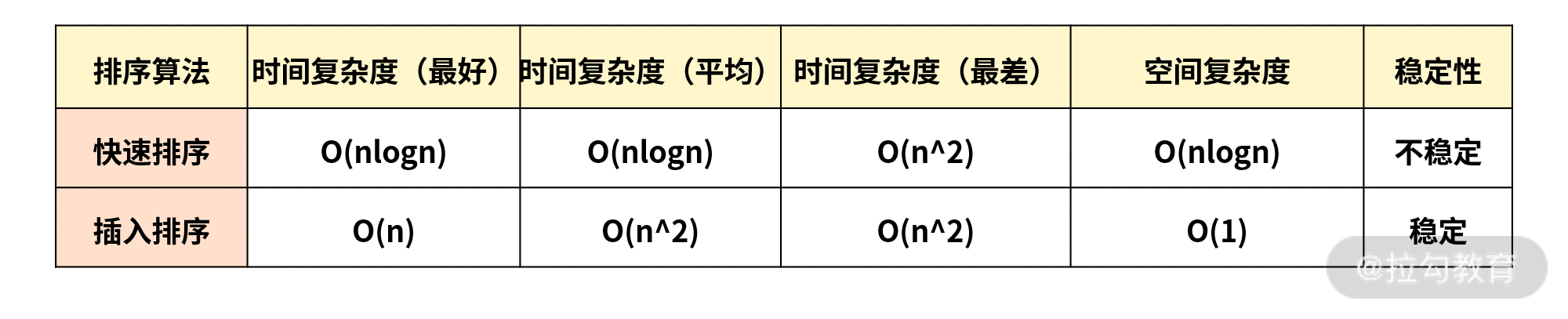
- 快速排序
最主要的思路是从数列中挑出一个元素,称为 “基准”(pivot);然后重新排序数列,所有元素比基准值小的摆放在基准前面、比基准值大的摆在基准的后面;在这个区分搞定之后,该基准就处于数列的中间位置;然后把小于基准值元素的子数列(left)和大于基准值元素的子数列(right)递归地调用 quick 方法排序完成,这就是快排的思路。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];function quickSort(array) {var quick = function(arr) {if (arr.length <= 1) return arrconst index = Math.floor(len >> 1)const pivot = arr.splice(index, 1)[0]const left = []const right = []for (let i = 0; i < arr.length; i++) {if (arr[i] > pivot) {right.push(arr[i])} else if (arr[i] <= pivot) {left.push(arr[i])}}return quick(left).concat([pivot], quick(right))}const result = quick(array)return result}quickSort(a);// [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
- 插入排序
插入排序算法描述的是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,从而达到排序的效果。
插入排序的思路是基于数组本身进行调整的,首先循环遍历从 i 等于 1 开始,拿到当前的 current 的值,去和前面的值比较,如果前面的大于当前的值,就把前面的值和当前的那个值进行交换,通过这样不断循环达到了排序的目的。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];function insertSort(array) {const len = array.lengthlet currentlet prevfor (let i = 1; i < len; i++) {current = array[i]prev = i - 1while (prev >= 0 && array[prev] > current) {array[prev + 1] = array[prev]prev--}array[prev + 1] = current}return array}insertSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
sort
sort 方法是对数组元素进行排序,默认排序顺序是先将元素转换为字符串,然后再进行排序。arr.sort([compareFunction])
其中 compareFunction 用来指定按某种顺序进行排列的函数,如果省略不写,元素按照转换为字符串的各个字符的 Unicode 位点进行排序。
const months = ['March', 'Jan', 'Feb', 'Dec'];months.sort();console.log(months);// ["Dec", "Feb", "Jan", "March"]const array1 = [1, 30, 4, 21, 100000];array1.sort();console.log(array1);// [1, 100000, 21, 30, 4]
如果指明了 compareFunction 参数 ,那么数组会按照调用该函数的返回值排序,即 a 和 b 是两个将要被比较的元素:
- 如果 compareFunction(a, b)小于 0,那么 a 会被排列到 b 之前;
- 如果 compareFunction(a, b)等于 0,a 和 b 的相对位置不变;
- 如果 compareFunction(a, b)大于 0,b 会被排列到 a 之前。 ```javascript const array1 = [1, 30, 4, 21, 100000];
array1.sort((a,b) => b - a);
console.log(array1); // [100000, 30, 21, 4, 1]
const array1 = [1, 30, 4, 21, 100000];
array1.sort((a,b) => a - b);
console.log(array1); // [1, 4, 21, 30, 100000]
<a name="noial"></a>#### 底层sort源码分析```javascriptfunction ArraySort(comparefn) {CHECK_OBJECT_COERCIBLE(this,"Array.prototype.sort");var array = TO_OBJECT(this);var length = TO_LENGTH(array.length);return InnerArraySort(array, length, comparefn);}function InnerArraySort(array, length, comparefn) {// 比较函数未传入if (!IS_CALLABLE(comparefn)) {comparefn = function (x, y) {if (x === y) return 0;if (%_IsSmi(x) && %_IsSmi(y)) {return %SmiLexicographicCompare(x, y);}x = TO_STRING(x);y = TO_STRING(y);if (x == y) return 0;else return x < y ? -1 : 1;};}function InsertionSort(a, from, to) {// 插入排序for (var i = from + 1; i < to; i++) {var element = a[i];for (var j = i - 1; j >= from; j--) {var tmp = a[j];var order = comparefn(tmp, element);if (order > 0) {a[j + 1] = tmp;} else {break;}}a[j + 1] = element;}}function GetThirdIndex(a, from, to) { // 元素个数大于1000时寻找哨兵元素var t_array = new InternalArray();var increment = 200 + ((to - from) & 15);var j = 0;from += 1;to -= 1;for (var i = from; i < to; i += increment) {t_array[j] = [i, a[i]];j++;}t_array.sort(function(a, b) {return comparefn(a[1], b[1]);});var third_index = t_array[t_array.length >> 1][0];return third_index;}function QuickSort(a, from, to) { // 快速排序实现//哨兵位置var third_index = 0;while (true) {if (to - from <= 10) {InsertionSort(a, from, to); // 数据量小,使用插入排序,速度较快return;}if (to - from > 1000) {third_index = GetThirdIndex(a, from, to);} else {// 小于1000 直接取中点third_index = from + ((to - from) >> 1);}// 下面开始快排var v0 = a[from];var v1 = a[to - 1];var v2 = a[third_index];var c01 = comparefn(v0, v1);if (c01 > 0) {var tmp = v0;v0 = v1;v1 = tmp;}var c02 = comparefn(v0, v2);if (c02 >= 0) {var tmp = v0;v0 = v2;v2 = v1;v1 = tmp;} else {var c12 = comparefn(v1, v2);if (c12 > 0) {var tmp = v1;v1 = v2;v2 = tmp;}}a[from] = v0;a[to - 1] = v2;var pivot = v1;var low_end = from + 1;var high_start = to - 1;a[third_index] = a[low_end];a[low_end] = pivot;partition: for (var i = low_end + 1; i < high_start; i++) {var element = a[i];var order = comparefn(element, pivot);if (order < 0) {a[i] = a[low_end];a[low_end] = element;low_end++;} else if (order > 0) {do {high_start--;if (high_start == i) break partition;var top_elem = a[high_start];order = comparefn(top_elem, pivot);} while (order > 0);a[i] = a[high_start];a[high_start] = element;if (order < 0) {element = a[i];a[i] = a[low_end];a[low_end] = element;low_end++;}}}// 快排的核心思路,递归调用快速排序方法if (to - high_start < low_end - from) {QuickSort(a, high_start, to);to = low_end;} else {QuickSort(a, from, low_end);from = high_start;}}}
通过研究源码我们先直接看一下结论,如果要排序的元素个数是 n 的时候,那么就会有以下几种情况:
- 当 n<=10 时,采用插入排序;
- 当 n>10 时,采用三路快速排序;
- 10<n <=1000,采用中位数作为哨兵元素;
- n>1000,每隔 200~215 个元素挑出一个元素,放到一个新数组中,然后对它排序,找到中间位置的数,以此作为中位数。
1. 为什么元素个数少的时候要采用插入排序?
虽然插入排序理论上是平均时间复杂度为 O(n^2) 的算法,快速排序是一个平均 O(nlogn) 级别的算法。但是别忘了,这只是理论上平均的时间复杂度估算,但是它们也有最好的时间复杂度情况,而插入排序在最好的情况下时间复杂度是 O(n)。
在实际情况中两者的算法复杂度前面都会有一个系数,当 n 足够小的时候,快速排序 nlogn 的优势会越来越小。倘若插入排序的 n 足够小,那么就会超过快排。而事实上正是如此,插入排序经过优化以后,对于小数据集的排序会有非常优越的性能,很多时候甚至会超过快排。因此,对于很小的数据量,应用插入排序是一个非常不错的选择。
2. 为什么要花这么大的力气选择哨兵元素?
当数据量大于 1000 的时候就开始寻找哨兵元素。
因为快速排序的性能瓶颈在于递归的深度,最坏的情况是每次的哨兵都是最小元素或者最大元素,那么进行 partition(一边是小于哨兵的元素,另一边是大于哨兵的元素)时,就会有一边是空的。如果这么排下去,递归的层数就达到了 n , 而每一层的复杂度是 O(n),因此快排这时候会退化成 O(n^2) 级别。
这种情况是要尽力避免的,那么如何来避免?就是让哨兵元素尽可能地处于数组的中间位置,让最大或者最小的情况尽可能少。

若有收获,就点个赞吧
0 人点赞
