深入理解 Java 中 SPI 机制
一、简介
SPI(Service Provider Interface) , 是JDK内置的一种服务提供发现机制,可以用来启动框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对接口做出不同的实现,MYSQL和PostgreSQL都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤为重要,其核心思想就是解耦。
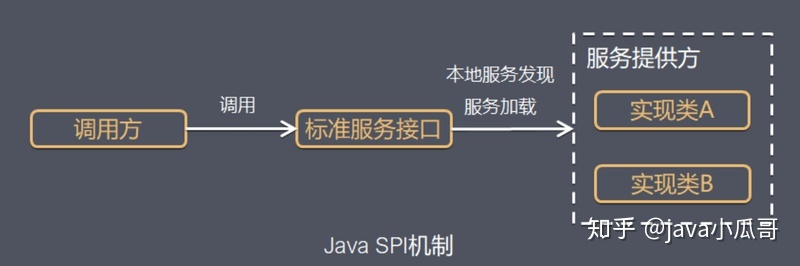
当服务的提供者提供了一种接口的实现之后,需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader。
二、应用场景
SPI扩展机制应用场景有很多,比如Common-Logging,JDBC,Dubbo等等。
SPI流程:
- 有关组织和公式定义接口标准
- 第三方提供具体实现: 实现具体方法, 配置 META-INF/services/${interface_name} 文件
- 开发者使用
比如JDBC场景下:
- 首先在Java中定义了接口java.sql.Driver,并没有具体的实现,具体的实现都是由不同厂商提供。
- 在MySQL的jar包mysql-connector-java-6.0.6.jar中,可以找到META-INF/services目录,该目录下会有一个名字为java.sql.Driver的文件,文件内容是com.mysql.cj.jdbc.Driver,这里面的内容就是针对Java中定义的接口的实现。
同样在PostgreSQL的jar包PostgreSQL-42.0.0.jar中,也可以找到同样的配置文件,文件内容是org.postgresql.Driver,这是PostgreSQL对Java的java.sql.Driver的实现。
三、源码分析
// ServiceLoader实现了Iterable接口,可以遍历所有的服务实现者public final class ServiceLoader<S> implements Iterable<S>{// 查找配置文件的目录private static final String PREFIX = "META-INF/services/";// 表示要被加载的服务的类或接口private final Class<S> service;// 这个ClassLoader用来定位,加载,实例化服务提供者private final ClassLoader loader;// 访问控制上下文private final AccessControlContext acc;// 缓存已经被实例化的服务提供者,按照实例化的顺序存储private LinkedHashMap<String,S> providers = new LinkedHashMap<>();// 迭代器private LazyIterator lookupIterator;}// 服务提供者查找的迭代器public Iterator<S> iterator() {return new Iterator<S>() {Iterator<Map.Entry<String,S>> knownProviders= providers.entrySet().iterator();// hasNext方法public boolean hasNext() {if (knownProviders.hasNext())return true;return lookupIterator.hasNext();}// next方法public S next() {if (knownProviders.hasNext())return knownProviders.next().getValue();return lookupIterator.next();}};}// 服务提供者查找的迭代器private class LazyIterator implements Iterator<S> {// 服务提供者接口Class<S> service;// 类加载器ClassLoader loader;// 保存实现类的urlEnumeration<URL> configs = null;// 保存实现类的全名Iterator<String> pending = null;// 迭代器中下一个实现类的全名String nextName = null;public boolean hasNext() {if (nextName != null) {return true;}if (configs == null) {try {String fullName = PREFIX + service.getName();if (loader == null)configs = ClassLoader.getSystemResources(fullName);elseconfigs = loader.getResources(fullName);} catch (IOException x) {fail(service, "Error locating configuration files", x);}}while ((pending == null) || !pending.hasNext()) {if (!configs.hasMoreElements()) {return false;}pending = parse(service, configs.nextElement());}nextName = pending.next();return true;}public S next() {if (!hasNext()) {throw new NoSuchElementException();}String cn = nextName;nextName = null;Class<?> c = null;try {c = Class.forName(cn, false, loader);} catch (ClassNotFoundException x) {fail(service,"Provider " + cn + " not found");}if (!service.isAssignableFrom(c)) {fail(service, "Provider " + cn + " not a subtype");}try {S p = service.cast(c.newInstance());providers.put(cn, p);return p;} catch (Throwable x) {fail(service, "Provider " + cn + " could not be instantiated: " + x, x);}throw new Error(); // This cannot happen}}
首先,ServiceLoader实现了Iterable接口,所以它有迭代器的属性,这里主要都是实现了迭代器的hasNext和next方法。这里主要都是调用的lookupIterator的相应hasNext和next方法,lookupIterator是懒加载迭代器。
其次,LazyIterator中的hasNext方法,静态变量PREFIX就是”META-INF/services/”目录,这也就是为什么需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件。
最后,通过反射方法Class.forName()加载类对象,并用newInstance方法将类实例化,并把实例化后的类缓存到providers对象中,(LinkedHashMap
四、不足
1.不能按需加载,需要遍历所有的实现,并实例化,然后在循环中才能找到我们需要的实现。如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,这就造成了浪费。
2.获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。
3.多个并发多线程使用 ServiceLoader 类的实例是不安全的。

若有收获,就点个赞吧
0 人点赞
