from glob import glob # 匹配查找文件for fname in glob("*.py"):print(f"\n{fname}")with open(fname,'r',encoding='utf-8')as f:print(f.read())
实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件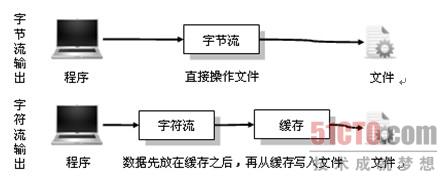
Python对象序列化为一个字节流,以便将它保存到一个文件、存储到数据库或者通过网络传输它
import pickleorder = list(range(10))with open("order.txt","wb") as fout:pickle.dump(order,fout)with open("order.txt","rb") as fin:order = pickle.load(fin)print(order) # 输出输入的pickle方式
pickle 是一种Python特有的自描述的数据编码。 通过自描述,被序列化后的数据包含每个对象开始和结束以及它的类型信息。 因此,你无需担心对象记录的定义,它总是能工作
order = list(range(10))with open("order.txt","wb") as fout:pickle.dump(order,fout)pickle.dump("hello",fout)pickle.dump(123,fout)with open("order.txt","rb") as fin:# order = pickle.load(fin)print(pickle.load(fin))print(pickle.load(fin))print(pickle.load(fin))"""[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]hello123

若有收获,就点个赞吧
0 人点赞
