- mysql 几种搜索引擎的比较
mysql中通过show ENGINES指令可以看到所有支持的数据库存储引擎,最为常用的就是MylSAM和lnnoDB两种。">mysql 几种搜索引擎的比较
mysql中通过show ENGINES指令可以看到所有支持的数据库存储引擎,最为常用的就是MylSAM和lnnoDB两种。
mysql 几种搜索引擎的比较
mysql中通过show ENGINES指令可以看到所有支持的数据库存储引擎,最为常用的就是MylSAM和lnnoDB两种。
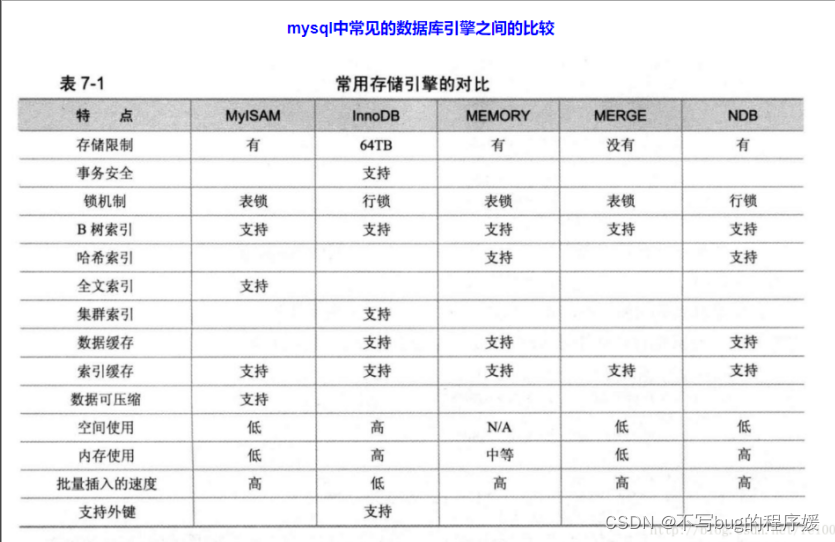
MySQL5.5以后默认使用InnoDB存储引擎,其中InnoDB提供事务安全,其它存储引擎都是非事务安全
MyISAM
它不支持事务,也不支持外键,尤其是访问速度快,对事务完整性没有要求或者以SELECT、INSERT为主的应用基本都可以使用这个引擎来创建表。
InnoDB
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引
InnoDB是如何实现事务的:
Inodb通过Buffer Pol, LogBuffer,Redo Log, Undo log来实现事务。以一个update为例:
1. Inodb在收到一个update语句后, 会先根据条件找到数据所在的页。并将该页缓存在Bufter Pool中
2执行update语句,修改Buffer Pool中的数据,也就是内存中的数据
3针对updare语句生成一个Redo Log对像。 并存LogBuffer中
4针对update语句生成undo log日志。用于事务回滚
5.如果事务提交,那么则把Redolog对象进行持久化,后续还有其他机制Bufter Pool中所修改的数据页持久化到磁盘中
6如果事务回滚,则利用undolog日志进行回滚
InnoDB和MyISAM的区别:
InnoDB支持事务,支持外键,空间使用和内存使用都比MyISAM高。InnoDB是行级锁。MyISAM是表级锁,InnoDB表能够自动从灾难中恢复,查询不加锁(默认排他锁) ,
1.存储文件, MyISAM每个表有两个文件。 MYD和MYI文件。 MYD是数据文件。 MYI是索引文件。 而InnDB每个表 只有一个文件,idb.
2、InnoDB支持事务,支持行级锁,支持外键。
3. InnoDB支持XA事务
4. InnoDB支持savePoints
外键:
1.外键的性能问题
数据库需要维护外键的内部管理;
外键等于把数据的一致性事务实现,全部交给数据库服务器完成;
有了外键,当做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,而不得不消耗资源;
外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
MySQL 中 varchar 与 char 的区别?varchar(50) 中的 50 代表的涵义?
varchar 与 char 的区别,char 是一种固定长度的类型,varchar 则是一种可变长度的类型。
varchar(50) 中 50 的涵义最多存放 50 个字符。varchar(50) 和 (200) 存储 hello 所占空间一样,但后者在排序时会消耗更多内存,因为 ORDER BY col 采用 fixed_length 计算 col 长度(memory引擎也一样)。
int(11) 中的 11 代表什么涵义?
无论是int(3), int(6), 都可以显示6位以上的整数。但是,当数字不足3位或6位时,前面会用0补齐,我看了真实的数据库,并没有补齐啊?
为什么 SELECT COUNT() FROM table 在 InnoDB 比 MyISAM 慢?
对于 SELECT COUNT() FROM table 语句,在没有 WHERE 条件的情况下,InnoDB 比 MyISAM 可能会慢很多,尤其在大表的情况下。因为,InnoDB 是去实时统计结果,会全表扫描;而 MyISAM 内部维持了一个计数器,预存了结果,所以直接返回即可。
【重点】什么是索引?
索引,类似于书籍的目录,想找到一本书的某个特定的主题,需要先找到书的目录,定位对应的页码。MySQL 中存储引擎使用类似的方式进行查询,先去索引中查找对应的值,然后根据匹配的索引找到对应的数据行。索引的数据结构是B+树
索引有什么好处?
提高数据的查询速度,降低数据库IO成本
降低数据排序的成本,降低CPU消耗:索引之所以查的快,是因为先将数据排好序,若该字段正好需要排序,则正好降低了排序的成本。
索引有什么坏处?
占用存储空间:索引实际上也是一张表,记录了主键与索引字段,一般以索引文件的形式存储在磁盘上。降低更新表的速度:表的数据发生了变化,对应的索引也需要一起变更,从而降低的更新速度。否则索引指向的物理数据可能不对,这也是索引失效的原因之一。
索引的使用场景?
对非常小的表,大部分情况下全表扫描效率更高。
对中大型表,索引非常有效。
特大型的表,建立和使用索引的代价随着增长,可以使用分区技术来解决
索引的类型?
索引,都是实现在存储引擎层的。主要有六种类型:
1、普通索引:最基本的索引,没有任何约束。
2、唯一索引:唯一索引列的值必须唯一允许有空值。
3、主键索引:特殊的唯一索引,不允许有空值。
4、复合索引:将多个列组合在一起创建索引,可以覆盖多个列。复合索引遵守“最左前缀”原则,即在查询条件中使用了复合索引的第一个字段,索引才会被使用。因此,在复合索引中索引列的顺序至关重要
5、外键索引:只有InnoDB类型的表才可以使用外键索引,保证数据的一致性、完整性和实现级联操作。
6、全文索引:MySQL 自带的全文索引只能用于 InnoDB、MyISAM ,并且只能对英文进行全文检索,一般使用全文索引引擎。
MySQL 索引的“创建”原则?
1.最适合索引的列是出现在 WHERE 子句中的列,或连接子句中的列,而不是出现在 SELECT 关键字后的列。
2. 索引列的基数(索引中不重复的索引值的数量)越大,索引效果越好。
3、根据情况创建复合索引,复合索引可以提高查询效率,因为复合索引的基数会更大。
4、避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率。
5、主键尽可能选择较短的数据类型,可以有效减少索引的磁盘占用提高查询效率。
6、对字符串进行索引,应该定制一个前缀长度,可以节省大量的索引空间。
7.更新频繁字段不适合创建索引
8.若是不能有效区分数据的列不适合做索引列(如性别,男女未知, 最多也就三种,区分度实在太低)
9.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索 引即可。
9.对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
10.对于定义为text. image和bit的数据类型的列不要建立索引。
MySQL 索引的“使用”注意事项?
1.应尽量避免在 WHERE 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。优化器将无法通过索引来确定将要命中的行数,因此需要搜索该表的所有行。
2.应尽量避免在 WHERE 子句中使用 OR 来连接条件如:SELECT id FROM t WHERE num = 10 OR num = 20 。要想使用 or,又想让索引生效,只能将 or 条件中的每个列都加上索引。
3、Where 子句里对索引列上有表达式运算,数学运算,函数运算,用不上索引。
4、不要在 WHERE 子句中的 = 左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
5、如果 MySQL 评估使用索引比全表扫描更慢,会放弃使用索引。如果此时想要索引,可以在语句中添加强制索引。
6、存在索引列的数据类型隐形转换,则用不上索引,比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
7、LIKE 查询,% 不能在前,因为无法使用索引。如果需要模糊匹配,可以使用全文索引。
6、复合索引遵循’最左前缀’原则(即在查询条件中使用了复合索引的第一个字段,索引才会被使用。因此,在复合索引中索引列的顺序至关重要)。
mysql常见的水平切分方式有哪些?
回答:分库分表,分区表
什么是mysql的分库分表?
回答:把一个很大的库(表)的数据分到几个库(表)中,每个库(表)的结构都相同,但他们可能分布在不同的mysql实例,甚至不同的物理机器上,以达到降低单库(表)数据量,提高访问性能的目的。
分库分表往往是业务层实施的,分库分表后,为了满足某些特定业务功能,往往需要rd修改代码。
什么是mysql的分区表?
回答:所有数据还在一个表中,但物理存储根据一定的规则放在不同的文件中。这个是mysql支持的功能,业务rd代码无需改动。
看上去分区表很帅气,为什么大部分互联网还是更多的选择自己分库分表来水平扩展咧?
回答:
1)分区表,分区键设计不太灵活,如果不走分区键,很容易出现全表锁
2)一旦数据量并发量上来,如果在分区表实施关联,就是一个灾难
3)自己分库分表,自己掌控业务场景与访问模式,可控。分区表,研发写了一个sql,都不确定mysql是怎么玩的,不太可控
使用联合索引进行排序或分组的注意事项。
1.对于联合索引有个问题需要注意,ORDER BY的子句后边的列的顺序也必须按照索引列的顺序给出,索引列的顺序是(b,c,d),如果给出 order by c, b, d 的顺序,那也是用不了B+树索引的。
2.对于使用联合索引进行排序的场景,我们要求各个排序列的排序顺序是一致的,也就是要么各个列都是ASC规则 排序,要么都是DESC规则排序。 ORDER BY子句后的列如果不加ASC或者DESC默认是按照ASC排序规则排序的,也就是升序排序的
select * from t1 order by b ASC, c DESC; 这个查询是用不到索引的。
Mysql的索引结构是什么样的
B+树:非叶子节点不存储数据,只进行数据索引,所有数据都存储在叶子节点中,每个叶子节点都存有相邻叶子节点的指针,叶子节点按照本身关键字从小到大排序,B树:节点排序,一个节点可以存放多个元素,多个元素也排序了,B+树拥有B树的特点
聚簇索引和非聚簇索引的区别?
都是B+树的数据结构
●聚簇索引上:将数据存储与索引放到了一块并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的 物理存放顺序与索引顺序是一致的。 即:只要索引是相邻的。那么对应的数据一定也是相邻地存放在磁盘上的 ,所以一个表当中只能有一个聚簇索引, 而非聚簇索引可以有多个。 InnoDB采用的是聚簇索引,树的叶子节点上的data就是数据本身。InnoDB中,如果表定义了PK,那PK就是聚簇索引。如果没有PK, 就会找第一个非空的unique列作为聚簇索引。否则,InnoDB会创建一个隐藏的row-id作为聚簇索引。
●非聚簇索引:叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再去磁盘查找數据,这个就有点类似一本书的目录。比如我们要找第三章第一节,那我们先在这个目录里面找。找到对应 的页码后再去对应的页码看文章。MyISAM使用的是非聚簇索引,树的子节点上的data不是数据本身,而是数据存放的地址。
优势。
1.通过聚簇索引可以直接获取数据。相比非聚族索引需要第二次查询(非覆盖索引的情况下效率要高)
2.聚族索引对于范围查询的效率很高。因为其数据是按照大小排列的
3.聚族索引适合用在排序的场合。非聚族索引不适合
劣势:
1.维护索引很昂贵。特别是插入新行或者主键被更新导致要分页(page split)的时候。建议在大量插入新行后。选 在负载较低的时间段,通过OPTIMIZE TABLE优化表。因为必须被移动的行数据可能造成碎片。使用独享表空间可以 羽化碎片
2.表因为使用uUId (菌机ID)作为主键。使数据存储稀疏。这就会出现聚族索引有可能有比全表扫面更慢。所以建 议使用int的auto_ increment作为主键 议使用int的自动增量作为主键
3、如果主键比较大的话。那辅助索引将公变的更大。因为辅助索引的叶子存储的是主键值:过长的主键值。公导致非叶子节点占用占用更多的物理空间 叶子节点占用占用更多的物理空间
MySQL的覆盖索引和回表
如果只需要在一颗索引树上就可以获取SQL所需要的所有列,就不需要再回表查询,这样查询速度就可以更快。
实现索引覆盖最简单的方式就是将要查询的字段,全部建立到联合索引当中。
user (PK id, name ,sex)
select count(name) from user; -> 在name字段上建立-个索引.
select id,name ,sex from user; 将name字段上的索引升级为(name,sx)联合索引
Mysql的锁有哪些?什么是间隙锁?
从锁的粒度来区分:
1.行锁:加锁粒度小,但是加锁资源开销比较大InnDB支持,悲伤锁,并发度高
共享锁:读锁。多个事务可以对同一个数据共享同一把锁。持有锁的事务都可以访问数据,但是只能读不能修改。select xxx Lock IN SHAREMODE.
排他锁:写锁。只有一个事务能够获得排他锁,其他事务都不能获取该行的锁。InnoDB会对update\delete\insert语句自动添加排他锁。SELECT Xxx FOR UPDATE, InnoDB默认加排他锁
自增锁:通常是针对MySQL 当中的自增字段。如果有事务回滚这种情况,数据会回滚,但是自增序列不会回滚。
2.表锁:加锁粒度大,加锁资源开锁比较小,MyLSAM和InnDB都支持,悲伤锁,并发度低
表共享读锁
表排他写锁
意向锁:是InnoDB自动添加的一种锁,不需要用户干预,
3.全局锁:Flush tables with read lock.加锁之后整个数据库实例都处于只读状态,所有的数据变更操作都会被挂起,一般用于全库备份的时候
常见的锁算法: user: userid ( 1.4.9) update user set xo where userid=5; REPEATABLE READ间隙锁锁住(5.9)
1、记录锁:锁一条具体的数据。
2、间隙锁: RR隔离级别下,会加间隙锁。锁一定的范围,而不锁具体的记录。是为了防止产生幻读。(-xx,1)(1,4)(4,9) (9, xxx)
3、Next-key :间隙锁+右记录锁。(-xx.1(1.4]4,9] (9, xx) 3、下键:间隙锁+右记录锁.(-x.1(1.4)4,9](9,xx)
Mysql 主从复制:
mysql通过将主节点的Binlog同步给从节点完成主从之间的数据同步。
MySQL的主从集群只会将binlog从主节点同步到从节点,而不会反过来同步。由此也就引申出了读写分离的问题。 因为要保证主从之间的数据一致, 写数据的操作只能在主节点完成,而读数据的操作, 可以在主节点或者从节点上完成。
海量数据下,如何快速查找一条记录?
1.使用布隆过滤器,快速过滤不存在的记录。
使用Redis的bitmap结构来实现布隆过滤器。
2.在Redis中建立数据缓存,。 将我们对Redis使用场景的理解尽量表达出来。
以普通宇符申的形式来存储,(useld -> userjson).以一个hash来存储条记录(userd key-> usemame field-> ,userAge->)。以一 个整的hash来存储所有的数据,Userlnfo-> field就用userld , value就用userison. 一个hash最多能支持2^32-1(40多个亿)个键值对。
缓存击穿:对不存在的数据也建立key.这些key都是经过布隆过滤器过滤的,所以一般不会太多。
缓存过期:将热点数据设置成永不过期,定期重建缓存。使用分布式锁重建缓存。
3.查询优化。
按槽位分配数据,
自己实现槽位计算,找到记录应该分配在哪台机器上,然后直接去目标机器上找。
事务的基本特性和隔离级别:
事务:表示多个数据操作组成一个完整的事务单元。 这个事务内的所有数据操作要么同时成功,要么同时失败。
事务的特性: ACID
1.原子性:事务是不可分割的,要么完全成功,要么完全失败。
2. 一致性:事务无论是完成还是失败,都必须保持事务内操作的一致性。当失败时,都要对前面的操作进行回滚,不管中途是否成功
3.隔商性:当多个事务操作一个数据的时候, 为防止数据损坏,需要将每个事务进行隔离,互相不干扰。
4.持久性:事务开始就不会终止。 他的结果不受其他外在因素的影响。
事务的隔离级别: SHOW VARIABLES like transaction%’
设置隔离级别: set transaction level xxx设置下次事务的隔离级别。
set session transaction level xxx 设置当前会话的事务隔离级别
set global transaction level xxx 设置全局事务隔离级别
事务可能产生的问题:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。读取到未提交事务的数据。读取阶段。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就有几列数据是未查询出来的,如果此时插入和另外一个事务插入的数据,就会报错。读取到新提交的数据,发生在插入阶段。
MySQL当中有五种隔离级别
none :不使用事务。
read uncommit读未提交.可能会读到其他事务未提交的数据,也叫做脏读。
read commit读已提交,两次读取结果不一致, 叫做不可重复读。 不可重复读解决了脏读的问题,他只会读取已经提交的事务。oracle的默认隔离级别
repeatable read可重复读。这是mysq的默认隔离级别,就是每次读取结果都一样,但是有可能产生幻读。
srilzable串行,一般是不会使用的。他会给每一行读取的数据加锁,会导致大量超时和就竞争的问题。
五种隔离级别。级别越高,事务的安全性是更高的,但是,事务的并性能也就会越低。
乐观锁的实现:
使用版本控制字段,再利用行锁的特性实现乐观锁,如下:
有一张订单表order,有字段id、order_no、 price, 为实现乐观锁控制,添加version字段,默认值为0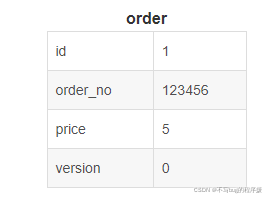
假设两个人同时进来修改该条数据,操作为:
1. 先查询该数据 select from order where id = 1
2. 修改该条数据 update order set price = 1 where id = 1
如果两个人同时查询到该条数据price = 5, 可以执行update操作, 但任意一方还没执行update操作,那么最后双方都执行update,导致数据被修改两次,产生脏数据 !
使用version字段控制版本后:
1. 两人先查询该数据 select from order where id = 1
此时两人查询到的数据一样,id = 1, price = 5, order_no = 123456, version = 0
- 两人都发现该条数据price = 5, 符合update条件,第一人执行update(因为mysql行锁的特性,两人不可能同时修改一条数据,所以update同一条数据的时候,是有先后顺序的,只有在第一个执行完update,才能释放行锁,第二个继续进行update):
update order set price = 1, version = version + 1 where id = 1 and version = 0
执行完成后,version字段值将变成1, 第二人执行update:
update order set price = 1, version = version + 1 where id = 1 and version = 0
此时的version的值已经被修改为1,所以第二人修改失败,实现乐观锁控制。
like用左匹配符不能用索引 可以用什么代替:
col like ‘%a%’ 等价于 locate(‘a’,col)>0
col like ‘%a%’ position(‘a’ IN col)
col like ‘%a%’ 等价于 instr(col, ‘a’ )>0
执行过程:
select * from a where id in (select a_id from b)
mysql 执行过程:首先把in里面的子查询存到临时表,然后join,如果select a_id from b里的a_id 有重复值,会先去重。

若有收获,就点个赞吧
0 人点赞
