GC主要发生在堆和方法区中
方法区回收的内容主要是废弃的常量和无用的类
废弃的常量:一个常量没有被任何地方引用
无用的类:
- 类的所有实例已被回收
- 加载类的ClassLoader已被回收
- 类对应的java.lang.Class对象没有被任何地方引用,无法在任何地方通过发射访问该类的方法
判断对象存活的算法
引用计数算法
给对象中增加一个引用计数器,每当有一个地方引用它时,计数器值+1,引用失效就-1,当引用计数器为0则表示不被使用,可以回收
特点:实现简单,高效但无法解决相互依赖引用的问题
可达性分析算法
以一系列GC Roots对象作为初始集合,将与该集合中有引用关系的对象纳入到该集合中,不在集合中的对象表示对象不可达,也即对象不可用,可以被回收
GC Roots可以理解成堆外指向堆内的引用 主要包括几种: 1.虚拟机栈中引用的对象 2.本地方法栈中引用的对象 3.方法区中类静态属性引用的对象 4.方法区中常量引用的对象
java引用
java对象中reference类型的数据储存着时另外一块内存的起始地址,代表这是一个引用
强引用
形式类似”Object obj=new Object()”,只要强引用还存在,GC永远不会回收被引用的对象
软引用
在内存不足的情况下,也即在内存溢出之前会对软引用类型进行回收
场景:图片缓存,网页缓存,内存足够时缓存数据,从缓存读取,内存不足,清理缓存,防止内存浪费
弱引用
只能生存到下一次GC发生之前,无论内存是否充足都会被回收
场景:ThreadLocal
虚引用
无法通过引用取得一个对象实例,当引用对象被回收时收到一个系统通知
对象finalize方法
当一个对象被标记为可回收时,如果对象实例重写了finalize方法且没被执行过,则该对象就会被判定需要执行finalize方法,因此该对象会被放置到一个叫做”F-Queue”的队列中。该队列由低优先级的Finalizer线程去执行它。虚拟机会触发这个方法,但不承诺等待执行完成。
垃圾收集算法
主要包括标记-清除算法,复制算法以及标记-整理算法
虚拟机采用”分代收集”算法,把java堆分为新生代和老年代,根据不同的年代采用不同的算法进行收集。新生代有大量对象死亡,只有少量存活,可以选用复制算法,老年代存活率高,没有额外的空间进行担保,就必须使用”标记-清除”或者“标记-整理”算法
1.标记-清除算法
先标记后回收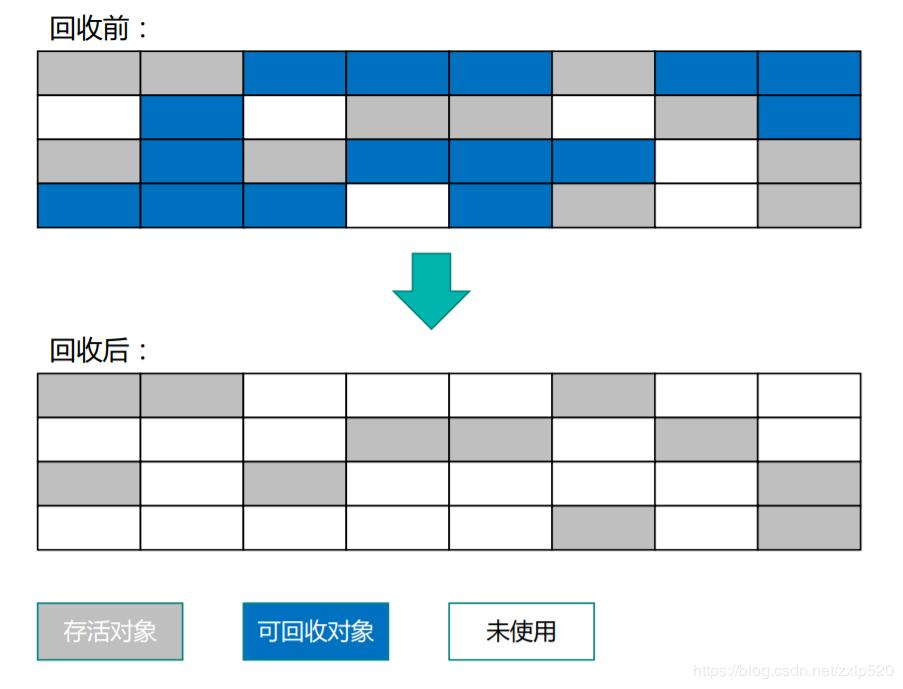
不足:
- 效率不高
-
2.复制算法
内存容量划分为相等两块,每次只是用一块,当一块内存用完时,就将还存活的对象复制到另一块内存中,将已使用的内存空间清理。
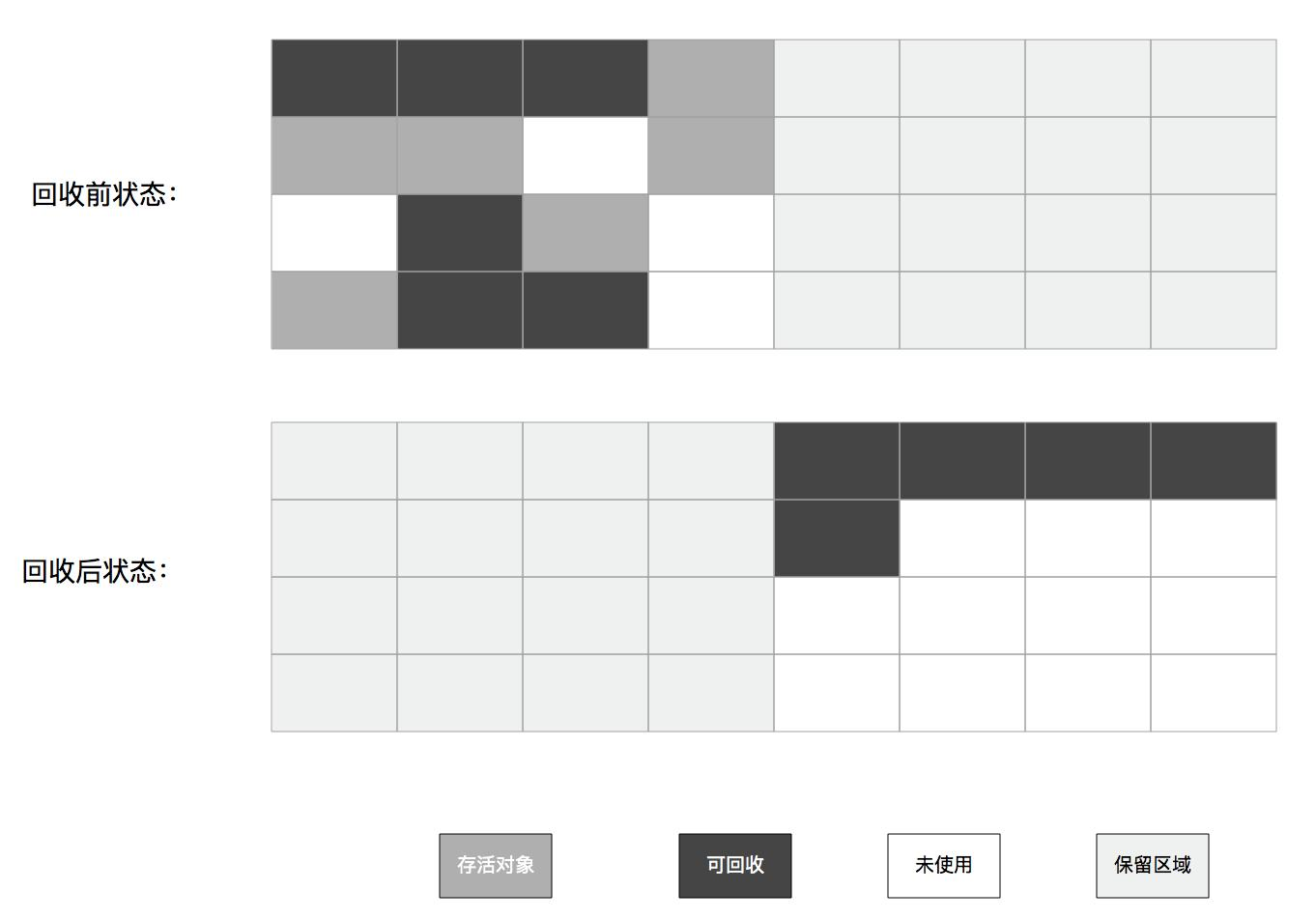
特点: 实现高效
- 没有内存碎片
- 空间利用率很低
-
3.标记-整理算法
先标记对象,将所有存活的对象向一端移动,然后清理掉边界以外的内存
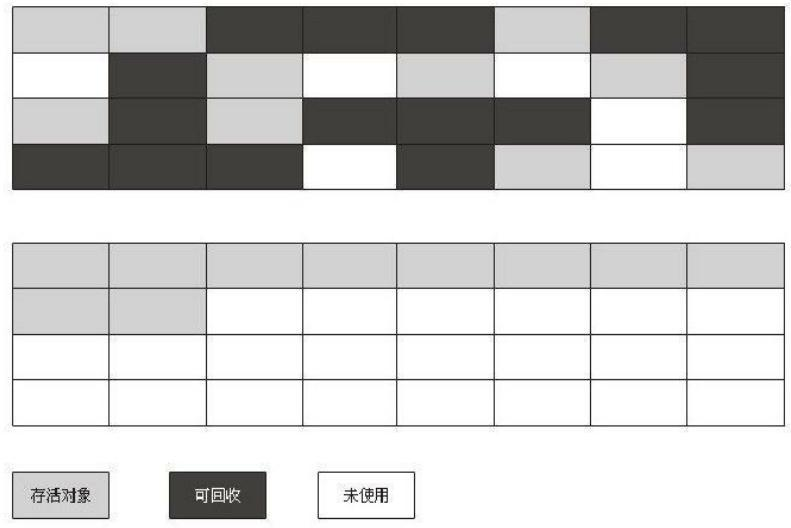
特点: 不存在内存碎片问题
- 适合老年代,不用进行分配担保
分配担保
另外一块的survivor区没有足够的空间存放上一次新生代收集下来存活的对象,这些对象将通过分配担保机制进入老年代
hotspot算法实现
枚举根节点
参考资料:
- 面试官:GC是如何快速枚举根节点的?
- 枚举根节点
1.使用OopMap记录GC Roots节点,避免全局扫描
在类加载时候进行计算,JIT阶段程序在处于安全点时进行记录在程序执行某些指令需要进行OopMap记录的特定位置称为安全点 工作线程只有都到达安全点才能停顿下来执行GC 安全点不能太少,导致GC等待时间过长 安全点不能太多,过分增加运行时负担
2.停留在安全点(正在执行的线程)
方案:
- 抢断式中断
系统中断所有线程,发现不在安全点线程,恢复线程,让其“跑”到安全点再停止下来
- 主动式中断
设置一个标志,让线程轮训是否需要中断线程,标志为真就中断线程,轮训判断的地方是安全点+分配内存时;
虚拟机底层会在轮训的地方增加test指令,需要暂停线程时,将test指令访问的内存页设置为不可读,线程执行到test指令会产生一个自陷异常信号,在预先注册的异常处理器中暂停线程实现等待
3.停留在安全区域(挂起的线程)
主要针对没有分配CPU时间的线程,如线程处于Sleep状态或者Blocked状态。这个时候线程无法响应JVM的中断请求。所以需要安全区域来解决
在这个区域内,不会发生引用关系的变化,线程执行到安全区域的代码时,首先标识自己进入安全区域,JVM发起GC时,进入安全区域的线程可以继续运行,当要离开安全区域时,需要检查系统是否完成了GC过程,已完成则继续执行,没有完全等待可以离开的信号之后才离开
垃圾收集器
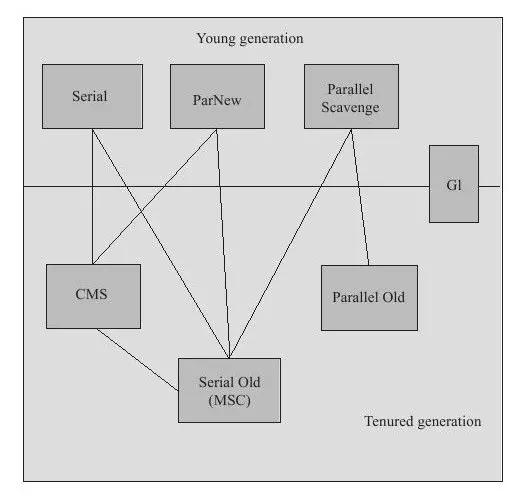
新生代收集器
包括Serial收集器,ParNew收集器和Parallel Scavenge收集器
Serial收集器
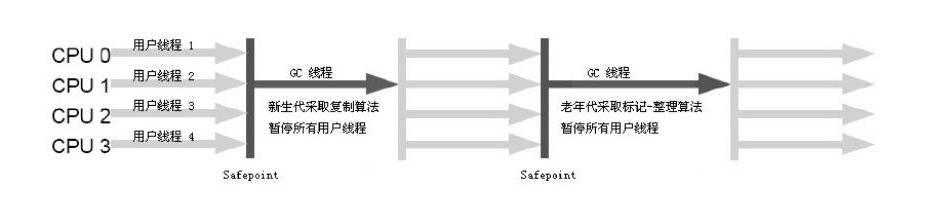
收集过程暂停所有工作线程,只使用单个线程执行收集工作
适合在client模式下使用,简单而高效
ParNew收集器
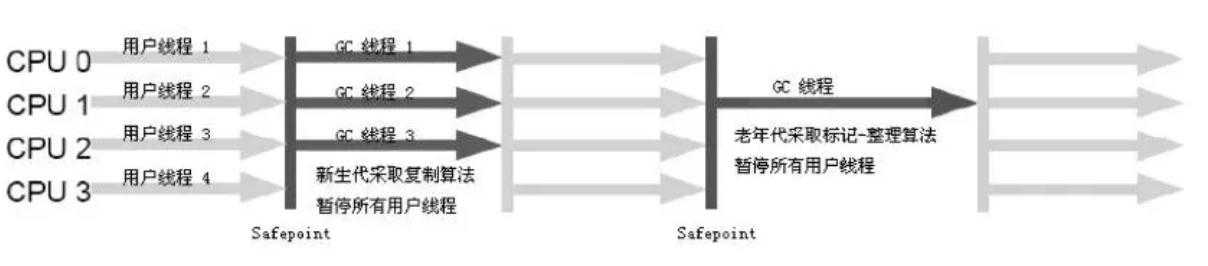
收集过程暂停所有工作线程,使用多线程进行收集工作
适用server模式,性能和CPU核数有关,可以和CMS搭配使用
Parallel Scavange收集器
多线程收集器,“吞吐量优先”收集器,可以达到一个可控的吞吐量
可以配置自适应的调节策略,用户无需指定eden区和surivor区的比例以及晋升老年代的年龄要求,通过收集性能监控信息进行动态调整参数
吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
老年代收集器
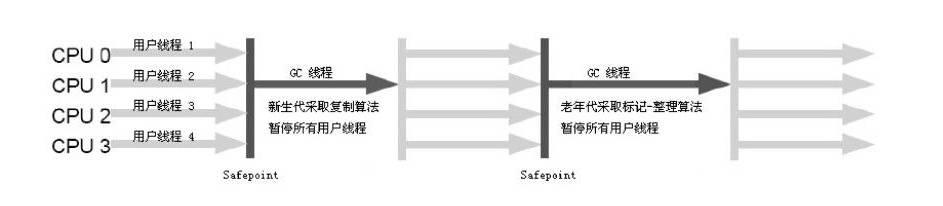
Serial Old收集器
Parallel Old收集器
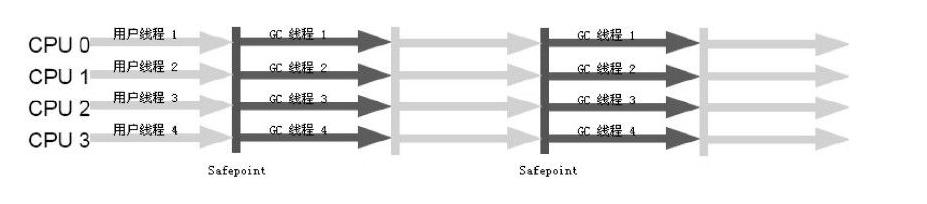
Parallel Scavange收集器的老年代版本,与Parallel Scavange搭配使用下,适用于注重吞吐量和CPU资源敏感的场合
CMS收集器
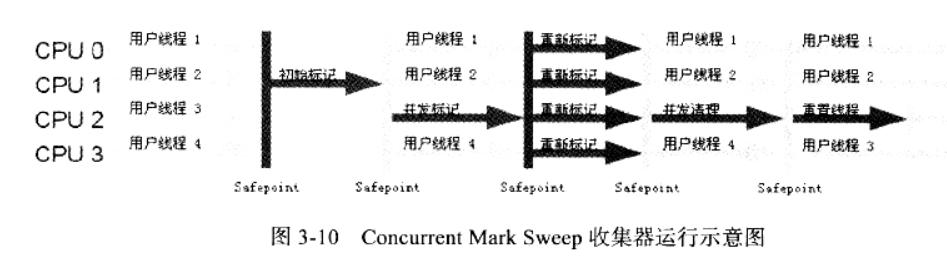
CMS使用的是标记-清除算法,以获取最短回收停顿时间为目标的收集器。
执行过程分为以下4步:
- 初始标记
需要STW,标记GC Roots直接关联的对象,速度快
- 并发标记
GC Roots Tracing过程,耗时很长
- 重新标记
需要STW,修正并发标记过程中变动的对象标记记录
- 并发清除
特点:并发收集,低停顿
缺点:
- 对CPU资源非常敏感,即较为占用CPU资源
无法处理浮动垃圾
并发清理过程用户线程还在执行,新产生的垃圾无法处理,也由于清理过程用户线程还在执行,需要预留空 间给用户线程使用,若预留的空间无法满足程序需要,会出现“Concurrent Mode Failure”失败,启用后备预案:临时启用Serial Old收集器进行老年代的垃圾收集
产生内存碎片
G1收集器
参考资料:G1收集器详解
取消了新生代,老年代的物理物理划分,取而代之的是区域划分,将堆划分为若干大小相等的独立区域,在逻辑上还是划分Eden、Survivor、OLd,但是物理上他们不是连续的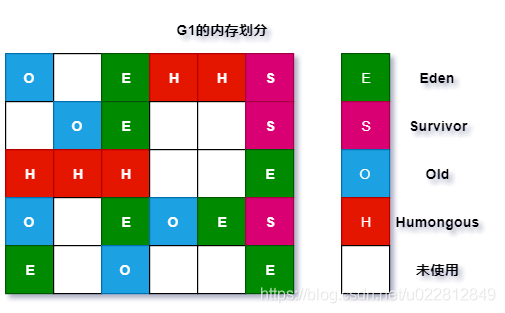
运行过程
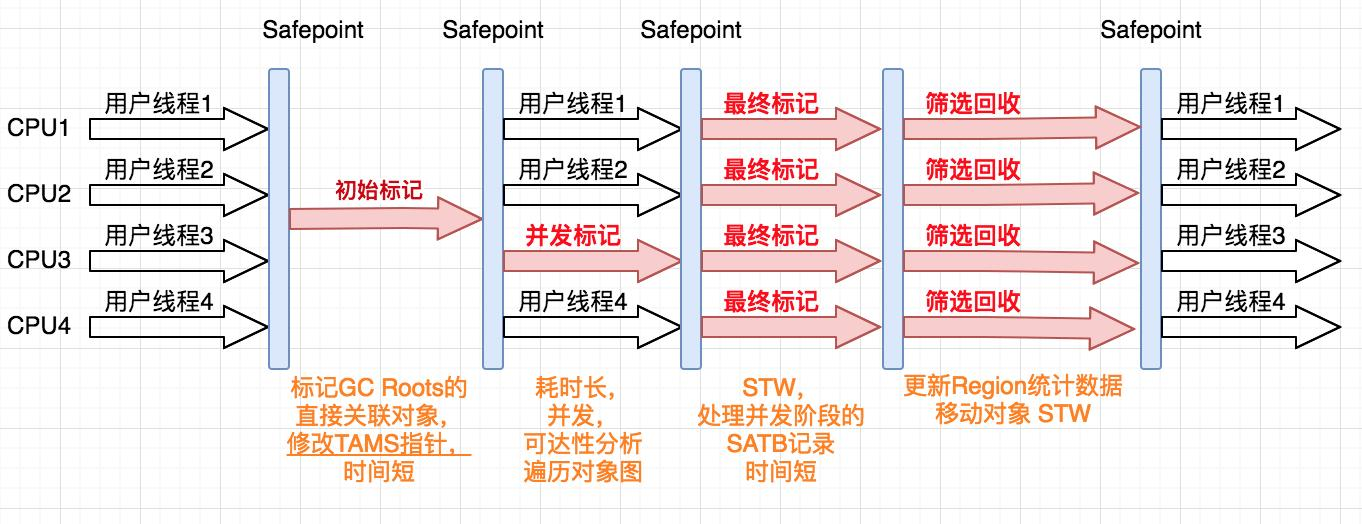
记忆集与卡表
跨代引用:堆空间通常被划分为新生代和老年代。由于新生代的垃圾收集通常很频繁,如果老年代对象引用了新生代的对象,那么回收新生代的话,需要扫描所有从老年代到新生代的所有引用,所以要避免每次YGC时扫描整个老年代,减少开销。
记忆集(RSet,Remembered Set):用来记录从其他Region中的对象到本Region的引用,是一种抽象的数据结构。每一个Region都设有一个RSet,有了这个数据结构,在回收某个Region的时候,就不必对整个堆内存的对象进行扫描了,它使得部分收集成为了可能。
对于年轻代的Region,它的RSet只保存了来自老年代的引用,这是因为年轻代的回收是针对所有年轻代Region的,没必要画蛇添足。所以说年轻代Region的RSet有可能是空的。
而对于老年代的Region来说,它的RSet也只会保存老年代对它的引用。这是因为老年代回收之前,会先对年轻代进行回收。这时,Eden区变空了,而在回收过程中会扫描Survivor分区,所以也没必要保存来自年轻代的引用。
RSet通常会占用很大的空间,大约5%或者更高(最高可能20%)。不仅仅是空间方面,很多计算开销也是比较大的。
RSet究竟是怎么辅助GC的呢?在做YGC的时候,只需要选定年轻代的RSet作为GC ROOTs,这些RSet记录了old->young的跨代引用,避免了扫描整个老年代。 而mixed gc的时候,老年代中记录了old->old的RSet,young->old的引用从Survivor区获取(老年代回收之前,会先对年轻代进行回收,存活的对象放在Survivor区),这样也不用扫描全部老年代,所以RSet的引入大大减少了GC的工作量。
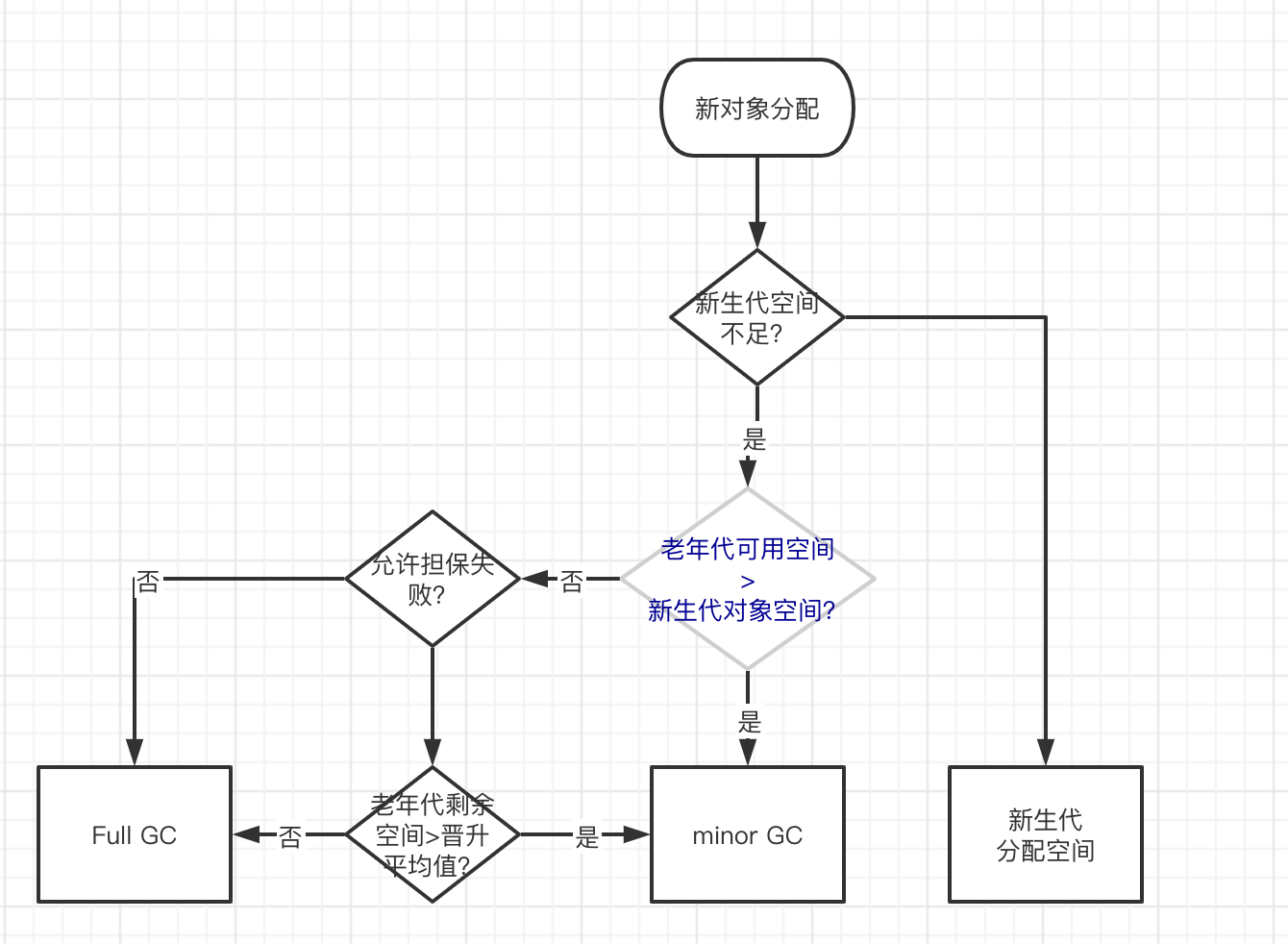
内存分配与回收策略
1.对象优先在Eden分配
空间不足需要进行minor GC,依然不足,通过分配担保机制,对象放入老年代
2.大对象直接进入老年代
3.长期存活的对象进入老年代
- 达到老年代年龄进入老年代
- survivor空间相同年龄的对象占survivor空间一半以上,年龄大于等于该年龄的对象直接进入老年代
空间分配担保

若有收获,就点个赞吧
0 人点赞
