逻辑日志: 可简单理解为 mysql 语句 物理日志: 因为 mysql 数据 最终保存在数据页中,物理日志记录数据页的变化
log 会先存在内存中,刷盘就是将内存中的持久化到硬盘上,对于 redo log 的 记录,就是在内存中先记录,找到合适的时候,对数据页 和 日志页进行持久化操作
事务执行中间过程的 redolog 都是直接写在 redolog buffer 中的,也就是说,一个没有提交的事务的 redolog,也是有可能会被后台线程一起持久化到磁盘的。
MySQL 保证数据不会丢的能力主要体现在两方面:
记录数据库执行的写入性操作,以二进制的形式存在磁盘中,是 mysql 的逻辑日志,由 server 层记录,使用任何引擎的 Mysql 都会记录 binlog
binlog 是通过追加的方式写入的,可通过 修改 max_binlog_size 来设置 binlog 文件的大小,当文件大小达到给定值之后,会生成新的文件保存日志。
使用场景
- 主从复制:在 master 端开启 binlog,然后将 binlog 发送到各个 Slave 端,Slave 端重放 binlog 从而达到主从数据一致。
- 数据恢复:通过使用 mysqlbinlog 工具恢复数据。(误删)
binlog 刷盘时机
对于 Innodb 只有事务提交时才会提交 binlog,此时记录还在内存中,通过 sunc_binlog 控制 binlog 的 刷盘时机,范围为 0-N
- 0 : 系统自己判断
- 1 :每次 commit 的时候都要写入
- N:当commit 达到 N 的时候写入
redo log(事务日志,记录数据修改后的值)
redo log 的使用
四大特性中存在一个特性为持久性,具体来说只要事务提交成功,那么对数据库的修改就被永远保存下来了,不可能因为任何原因再回到原来的状态。
mysql 的做法就是每次事务提交的时候,将该事务设计修改的数据页全部刷新到磁盘中,但是会存在严重的性能问题
- 每次操作可能只是修改一个数据页里面的借个字节,这样将完整的数据页刷到磁盘会大量浪费资源
- 一个事务可能修改多个数据页,写入IO性能太差
redolog 基本概念
包括两部分:1. 内存中的日志缓冲 2.磁盘上的日志文件
mysql 没执行一条语句,先将记录写入 redo log buffer,后续某个时间点将多个操作记录写入到 redo log file,这就是 WAL 技术。先写日志,再写磁盘。
redo log buffer 写入 redo log file 的时机,可以通过 innodb_flush_log_at_trx_commit 的参数配置,如下图
| 参数值 | 含义 |
|---|---|
| 0(延迟写) | 事务提交时不会将redo log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到redo log file中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。 |
| 1(实时写,实时刷) | 事务每次提交都会将redo log buffer中的日志写入os buffer并调用fsync()刷到redo log file中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。 |
| 2(实时写,延迟刷) | 每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到redo log file。 |

redo log 记录形式:
大小固定,循环写入,每次写道结尾时,会回到开头循环写日志。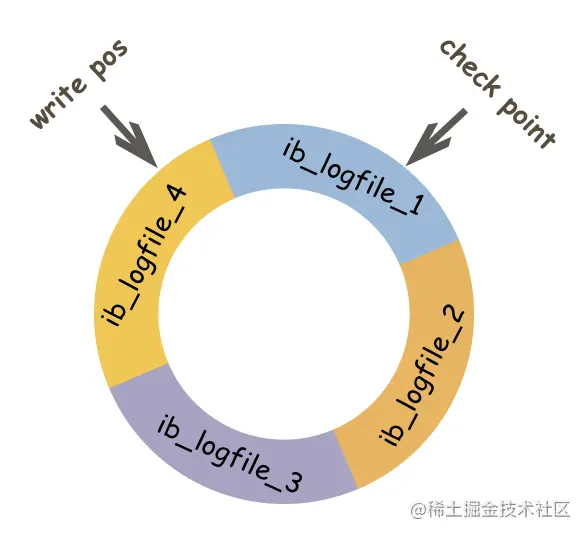
刷盘就是持久化到磁盘上。
补充 redolog 的具体落盘操作
在事务运行的过程中,MySQL 会先把日志写到 redolog buffer 中,等到事务真正提交的时候,再统一把 redolog buffer 中的数据写到 redolog 文件中。不过这个从 redolog buffer 写到 redolog 文件中的操作也就是 write 并不就是落盘操作了,这里仅仅是把 redolog 写到了文件系统的 page cache 上,最后还需要执行 fsync 才能够实现真正的落盘。
即在 innodb 中 redolog 需要刷盘, 数据页也需要 刷盘,redo log 的意义就是降低对 **数据页 刷盘的要求。
write pos ** 标识 redo log 当前记录的 LSN(逻辑序列号) 位置,从 write pos 到 check point 中间就是空着部分,用于记录新的记录,从 check point 到 write pos 中间就是待刷盘的数据页更改记录,当 write pos 追上 check point 时,就会推动 check point 向前移动,空出位置记录新的日志。
然后假如重启时,innodb 都会进行恢复操作,假如 日志中的 LSN > 磁盘中数据页的 LSN,证明关闭前,部分需要刷入磁盘的数据更改没有刷入,此时应该从checkpoint 开始恢复。另一种情况就是,当在进行刷盘时,宕机了,数据页中的刷盘速度超过 redo log,此时 数据页 LSN > redo log 中的 LSN,此时超过日志部分的进度不会再重做。
这个地方为什么会导致 数据页中的 LSN 大于 redo log 中的 LSN,前面我们提到了会先将记录写入操作,后续某个时间点再一次性将多个操作记录写到 redo log file 中,假如宕机的时刻,redo log file 正在刷盘,即同时对日志页 和 数据页 进行操作,此时就可能产生 数据页的 LSN > redo log file 中的 LSN
redo log与binlog区别
| redo log | binlog | |
|---|---|---|
| 文件大小 | redo log的大小是固定的。 | binlog可通过配置参数max_binlog_size设置每个binlog文件的大小。 |
| 实现方式 | redo log是InnoDB引擎层实现的,并不是所有引擎都有。 | binlog是Server层实现的,所有引擎都可以使用 binlog日志 |
| 记录方式 | redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 | binlog 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 适用场景 | redo log适用于崩溃恢复(crash-safe) | binlog适用于主从复制和数据恢复 |
undo log
数据库事务四大特性中有一个是原子性,具体来说就是 原子性是指对数据库的一系列操作,要么全部成功,要么全部失败,不可能出现部分成功的情况。实际上,原子性底层就是通过undo log实现的。undo log主要记录了数据的逻辑变化,比如一条INSERT语句,对应一条DELETE的undo log,对于每个UPDATE语句,对应一条相反的UPDATE的undo log,这样在发生错误时,就能回滚到事务之前的数据状态。同时,undo log也是MVCC(多版本并发控制)实现的关键。

若有收获,就点个赞吧
0 人点赞
