一种基于指对数的算法思想
numpy有两个函数,log1p()和expm1()。其中log1p(x)等价于log(x+1),expm1(x)等价于exp(x)-1。这两个函数在x的数量级远小于1(或x为绝对值很大的负数)的时候依然能返回一个正数,若直接使用log(x+1)或exp(x)-1则值为0,此操作保证值域的稳定性,避免出现值中出现0导致程序出错,难以调试。
它们互为逆运算,可以用于对输入值进行一些预处理再还原
曲线平滑
少量点之间插值补平滑
scipy.interpolate.make_interp_spline()可以把稀疏的点之间用多项式连接起来,且每段的多项式之间也是平滑连接的。具体的“如何平滑”需靠bc_type指定,可参考scipy官网
from scipy.interpolate import make_interp_splinemodel = make_interp_spline(xarray, yarray, 多项式次数,bc_type="natural")xs = np.linspace(xarray[0], xarray[-1], SMOOTH_POINT)axe.plot(xs, model(xs), label=legend)
仪器采集的很多点降噪
滑动窗口
最好用的是pandas.Series.rolling(),详见pandas官网,对于时间序列的滑动支持很完美,对其他序列的支持也不错
滑动窗口对象可以采用Series的函数和操作,可以执行.mean(),.min(),.max()等函数。
pandas.to_timedelta官网教程
# 某df是金属棒拉伸实验导出的数据,有三列数据,分别是时间(s)、压力、位移# 这段代码可以把把仪器上取得的每个点的压力和位移与其±250ms的点取平均值,达到平滑的效果df = df.set_index(pd.to_timedelta(df["时间"],"sec"))df = df.drop(columns=["时间"])df = df.rolling(pd.Timedelta(500, "ms"), center=True).mean()
Savitzky-Golay平滑滤波
Savitzky-Golay平滑滤波是一种广为采用的降噪算法,在python中的具体用法参照scipy官方文档
scipy.signal.savgol_filter(一维数据,窗口宽度<正奇数>,多项式次数)
numpy.convolve滑动平均滤波
和Savitzky-Golay是不一样的算法,具体参考numpy官网,在python中的实现方法相对于savitzky-golay要复杂一些
具体写法以后再研究
拟合
可参考教程
numpy多项式拟合
适用于少量有规律分布的点
# 从高次到低次排列的系数xarray = np.polyfit(xarray, yarray, 1)# 多项式,可以用形如f(2)的方式调用line_func = np.poly1d(cofficients)fit_yarray = line_func(xarray)
最小二乘法和线性回归
使用scipy.linalg.lstsq进行最小二乘,使用和scipy.stats.linregress进行s线性回归
适合找出杂乱分布的点的线性回归规律
原理复杂,参考官网解释scipy.linalg.lstsq和官网解释scipy.stats.linregress
任意函数拟合
很好用也很常用,详细解释见官网
from scipy.optimize import curve_fit系数矩阵, 协方差矩阵 = curve_fit(function, xarray, y_noisy)plt.plot(xarray, function(x, *系数矩阵))
判断数据中是否有异常值
可参考知乎翻译文章,虽然他翻译的很烂,但是原文需付费还被墙。图很好,看图就行
箱线图和IQR
如下图所示,一般定义超出箱线图边界的值就是不合理的值,numpy和pandas.DataFrame都有percentile方法,具体的算法写出来无非就是加减乘除,以后遇到了需求再写完整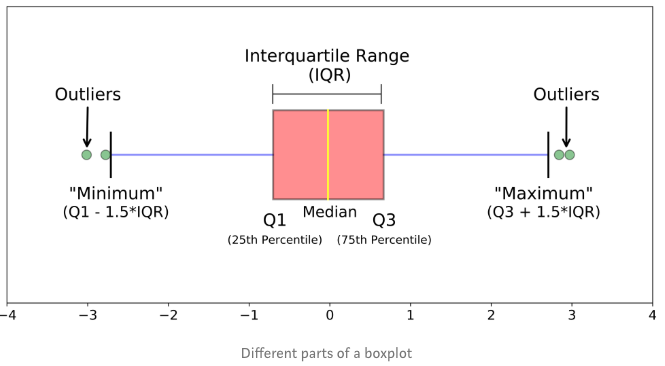
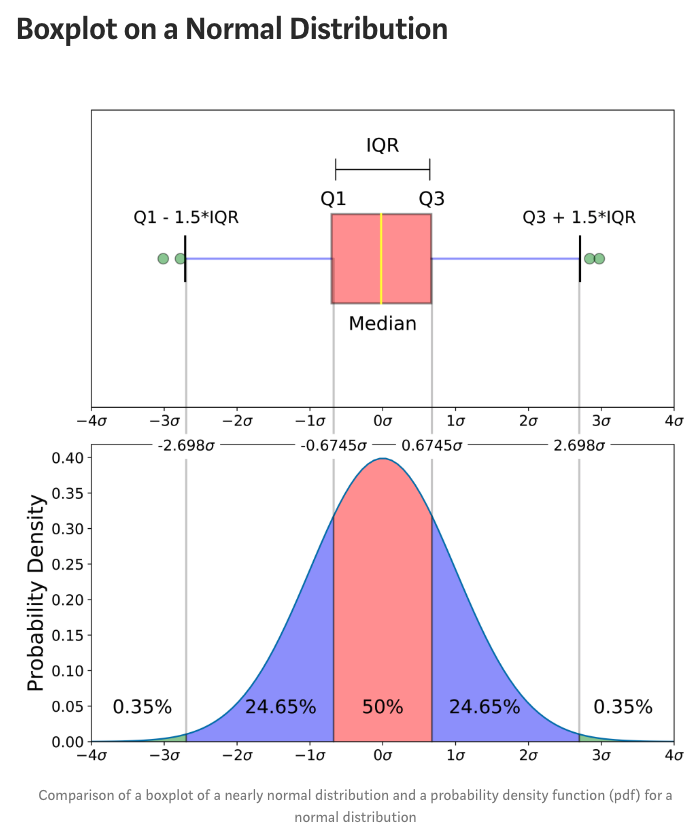
Z-Score
在一个统计模型中,对某选定值,zscore=(选定值-平均值)/标准差。若zscore的绝对值大于3则一般认为是异常值。
def valid_zscore(s):return np.abs((s - s.mean()) / s.std()) < 3
去除异常值后可视化
曲线数据的可视化不是用类似excel的界面显示几十万甚至更多个数字,而是使用图表。而数据中若有异常值,则图表的显示会出现问题,因此必须先去除异常值。最后参考下文导出数据分析报告。
pandas数据分析报告

若有收获,就点个赞吧
0 人点赞
