word2vec获取词向量,查找相似词
首先安装gensim, 训练或者下载别人训练好的word2vec模型
# coding=utf-8from gensim.models import Word2Vecfrom gensim.models import KeyedVectors#model = Word2Vec.load('./model/wiki.zh.text.model') #用模型model = KeyedVectors.load_word2vec_format('./model/wiki.zh.text.vector') # 用转换成txt的词向量文件testwords = ['孩子', '数学', '学术', '白痴', '篮球']for i in range(5):res = model.most_similar(testwords[i])print(testwords[i])print(res)
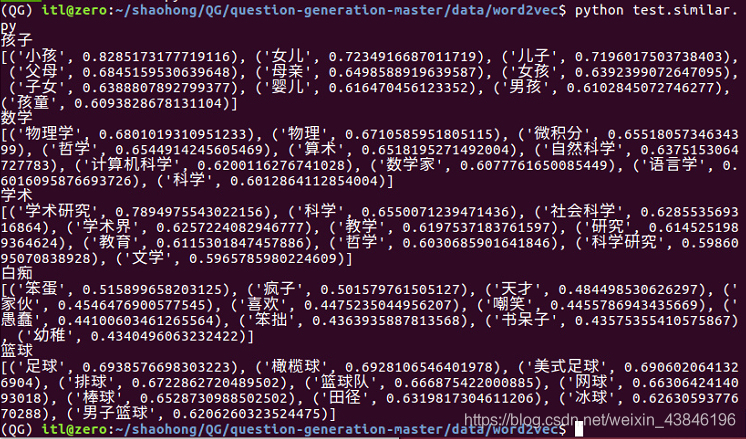
词向量模型下载地址:
https://github.com/Embedding/Chinese-Word-Vectors/blob/master/README_zh.md
文章来源:https://blog.csdn.net/weixin_43846196/article/details/95924039

若有收获,就点个赞吧
0 人点赞
