集群准备
描述:hadoop HA 集群的搭建依赖于 zookeeper,所以选取三台当做 zookeeper 集群 ,总共准备了四台主机,分别是 hadoop1,hadoop2,hadoop3,hadoop4 其中 hadoop1 和 hadoop2 做 namenode 的主备切换,hadoop3 和 hadoop4 做 resourcemanager 的主备切换
四台机器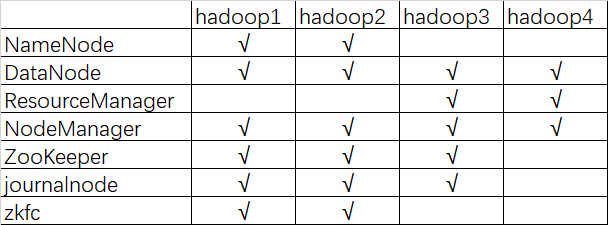
集群服务器准备
1、 修改主机名
2、 修改 IP 地址
3、 添加主机名和 IP 映射
4、 添加普通用户 hadoop 用户并配置 sudoer 权限
5、 设置系统启动级别
6、 关闭防火墙/关闭 Selinux
7、 安装 JDK 两种准备方式:
1、 每个节点都单独设置,这样比较麻烦。线上环境可以编写脚本实现
2、 虚拟机环境可是在做完以上 7 步之后,就进行克隆
然后接着再给你的集群配置 SSH 免密登陆和搭建时间同步服务
1在root用户下输入ssh-keygen -t rsa 一路回车
2秘钥生成后在~/.ssh/目录下,有两个文件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限
cat id_rsa.pub >> authorized_keyschmod 600 authorized_keys
3同理在其他节点上进行相同的操作,然后将公钥复制到master节点上的authoized_keys
4将master节点上的authoized_keys覆盖其他节点的authoized_keys,达到节点之间ssh免登录
8、 配置 SSH 免密登录
9、 同步服务器时间
集群安装
1.安装zookeeper集群
2.安装hadoop集群
2.1获取安装包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
2.2解压
[hadoop@hadoop1 ~]$ tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C /usr/local/
2.3修改配置文件
[hadoop@hadoop1 ~]$ cd /usr/local/hadoop-2.7.5/etc/hadoop/[hadoop@hadoop1 hadoop]$ echo $JAVA_HOME/usr/local/jdk1.8.0_73[hadoop@hadoop1 hadoop]$ vi hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.8
2.3.1修改core-site.xml
[hadoop@hadoop1 hadoop]$ vi core-site.xml<configuration><!-- 指定hdfs的nameservice为myha01 --><property><name>fs.defaultFS</name><value>hdfs://myha01/</value></property><!-- 指定hadoop临时目录 --><property><name>hadoop.tmp.dir</name><value>/home/hadoop/data/hadoopdata/</value></property><!-- 指定zookeeper地址 --><property><name>ha.zookeeper.quorum</name><value>hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181</value></property><!-- hadoop链接zookeeper的超时时长设置 --><property><name>ha.zookeeper.session-timeout.ms</name><value>1000</value><description>ms</description></property></configuration>
2.3.2修改hdfs-site.xml
[hadoop@hadoop1 hadoop]$ vi hdfs-site.xml<configuration><!-- 指定副本数 --><property><name>dfs.replication</name><value>2</value></property><!-- 配置namenode和datanode的工作目录-数据存储目录 --><property><name>dfs.namenode.name.dir</name><value>/home/hadoop/data/hadoopdata/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/home/hadoop/data/hadoopdata/dfs/data</value></property><!-- 启用webhdfs --><property><name>dfs.webhdfs.enabled</name><value>true</value></property><!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。例如,如果使用"myha01"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符--><property><name>dfs.nameservices</name><value>myha01</value></property><!-- myha01下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.myha01</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.myha01.nn1</name><value>hadoop1:9000</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.myha01.nn1</name><value>hadoop1:50070</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.myha01.nn2</name><value>hadoop2:9000</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.myha01.nn2</name><value>hadoop2:50070</value></property><!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalIdjournalId推荐使用nameservice,默认端口号是:8485 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/myha01</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/home/hadoop/data/journaldata</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置失败自动切换实现方式 --><property><name>dfs.client.failover.proxy.provider.myha01</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 --><property><name>dfs.ha.fencing.methods</name><value>sshfenceshell(/bin/true)</value></property><!-- 使用sshfence隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><property><name>ha.failover-controller.cli-check.rpc-timeout.ms</name><value>60000</value></property></configuration>
2.3.3修改mapped-site.xml
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml[hadoop@hadoop1 hadoop]$ vi mapred-site.xml<configuration><!-- 指定mr框架为yarn方式 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 指定mapreduce jobhistory地址 --><property><name>mapreduce.jobhistory.address</name><value>hadoop1:10020</value></property><!-- 任务历史服务器的web地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop1:19888</value></property></configuration>
2.3.4修改yarn-site.xml
[hadoop@hadoop1 hadoop]$ vi yarn-site.xml<configuration><!-- 开启RM高可用 --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定RM的cluster id --><property><name>yarn.resourcemanager.cluster-id</name><value>yrc</value></property><!-- 指定RM的名字 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 分别指定RM的地址 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop3</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop4</value></property><!-- 指定zk集群地址 --><property><name>yarn.resourcemanager.zk-address</name><value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value></property><!-- 启用自动恢复 --><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 制定resourcemanager的状态信息存储在zookeeper集群上 --><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property></configuration>
2.3.5修改slaves
[hadoop@hadoop1 hadoop]$ vi slaves
hadoop1
hadoop2
hadoop3
hadoop4
2.4将hadoop安装包分发到其他集群节点
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop2:$PWD
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop3:$PWD
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop4:$PWD
2.5配置Hadoop环境变量
千万注意:
1、如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
2、如果你使用普通用户进行安装。 vi ~/.bashrc 用户变量
本人是用的hadoop用户安装的
[hadoop@hadoop1 ~]$ vi .bashrc
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
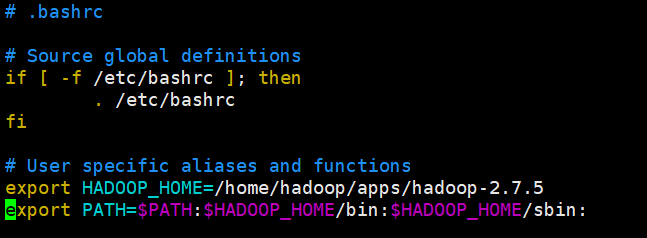
使环境变量生效
[hadoop@hadoop1 bin]$ source ~/.bashrc
2.6查看hadpop版本
[hadoop@hadoop4 ~]$ hadoop version
Hadoop 2.7.5
Subversion Unknown -r Unknown
Compiled by root on 2017-12-24T05:30Z
Compiled with protoc 2.5.0
From source with checksum 9f118f95f47043332d51891e37f736e9
This command was run using /home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5.jar
[hadoop@hadoop4 ~]$
Hadoop集群初始化
1.启动zookeeper服务器
在每台服务器上都启动,这里是节点角色是一台Master两台follower一台Observer
[hadoop@hadoop1 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop1 conf]$ jps
2674 Jps
2647 QuorumPeerMain
[hadoop@hadoop1 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop1 conf]$
observer节点设置
[root@hadoop1 logs]# vim /usr/local/zookeeper/conf/zoo.cfg
#在本身节点加上这条,其他不用加
peerType=observer
server.1=10.4.7.111:2888:3888
server.2=10.4.7.112:2888:3888
server.3=10.4.7.113:2888:3888
#在每个节点都标注这个observer
server.4=10.4.7.114:2888:3888:observer
2.在配置的各个journalnode节点启动该进程
按照之前的规划,我的是在hadoop1、hadoop2、hadoop3上进行启动,启动命令如下
hadoop1
[hadoop@hadoop1 conf]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-journalnode-hadoop1.out
[hadoop@hadoop1 conf]$ jps
2739 JournalNode
2788 Jps
2647 QuorumPeerMain
[hadoop@hadoop1 conf]$
3.格式化namenode
先选取一个namenode(hadoop1)节点进行格式化
[hadoop@hadoop1 ~]$ hadoop namenode -format
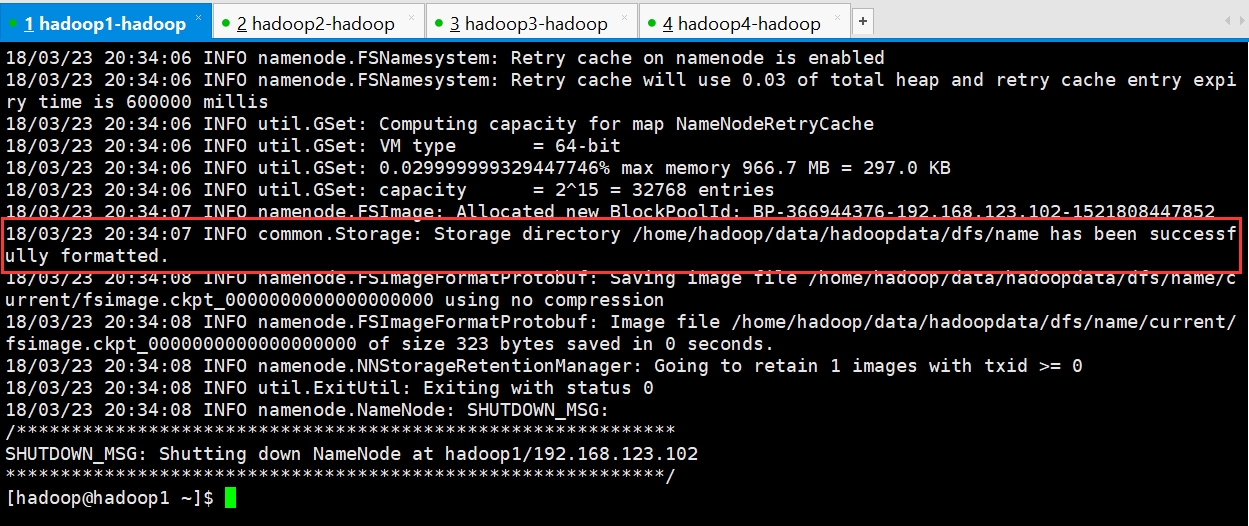
4.把在hadoop1节点上生成的元数据复制到另一个namenode上
这里要检查两个节点下目录文件是不是一样的,否则会发生启动不起来namenode
[hadoop@hadoop1 ~]$ cd data/
[hadoop@hadoop1 data]$ ls
hadoopdata journaldata zkdata
[hadoop@hadoop1 data]$ scp -r hadoopdata/ hadoop2:$PWDVERSION 100% 206 0.2KB/s 00:00 fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00 fsimage_0000000000000000000 100% 323 0.3KB/s 00:00 seen_txid 100% 2 0.0KB/s 00:00 [hadoop@hadoop1 data]$
5.格式化zkfc
重点强调:只能在nameonde节点进行
重点强调:只能在nameonde节点进行
重点强调:只能在nameonde节点进行
[hadoop@hadoop1 data]$ hdfs zkfc -formatZK
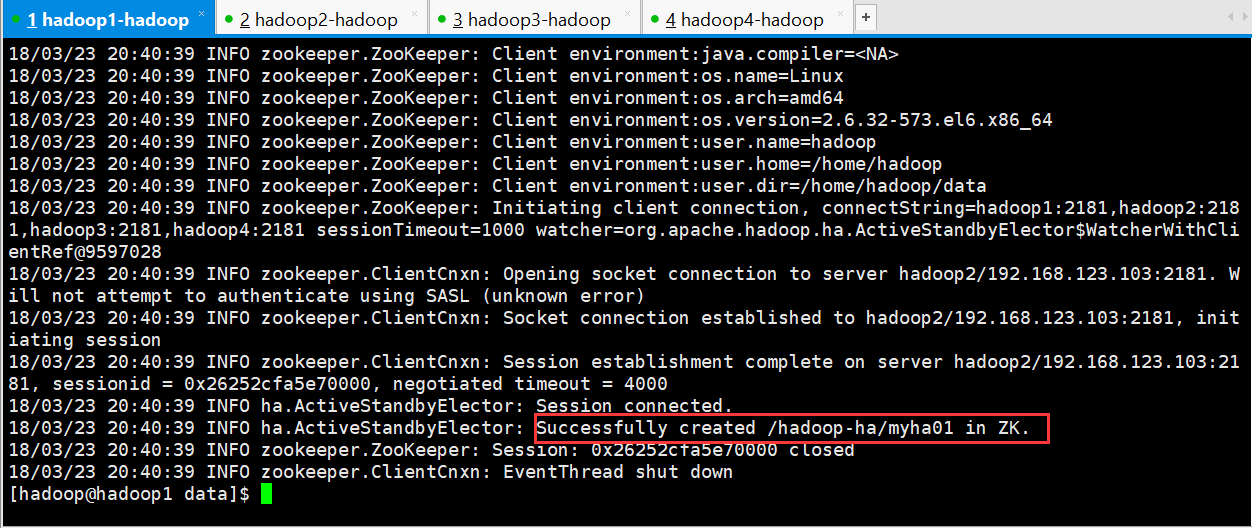
启动集群
1.启动HDFS
可以从启动输出日志里面看到启动了哪些进程
[hadoop@hadoop1 ~]$ start-dfs.sh
Starting namenodes on [hadoop1 hadoop2]
hadoop2: starting namenode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-namenode-hadoop2.out
hadoop1: starting namenode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-namenode-hadoop1.out
hadoop3: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop3.out
hadoop4: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop4.out
hadoop2: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop2.out
hadoop1: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop1.out
Starting journal nodes [hadoop1 hadoop2 hadoop3]
hadoop3: journalnode running as process 16712. Stop it first.
hadoop2: journalnode running as process 3049. Stop it first.
hadoop1: journalnode running as process 2739. Stop it first.
Starting ZK Failover Controllers on NN hosts [hadoop1 hadoop2]
hadoop2: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-hadoop2.out
hadoop1: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-hadoop1.out
[hadoop@hadoop1 ~]$
查看各个节点是否正常,也就是是否有这些进程
hadoop1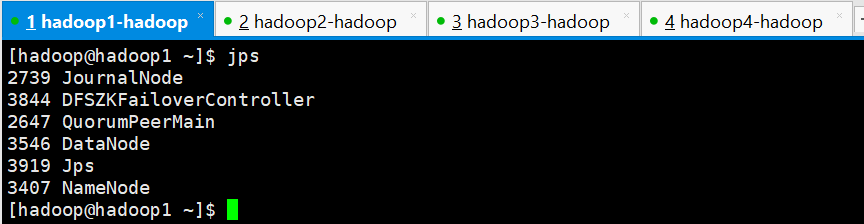
hadoop2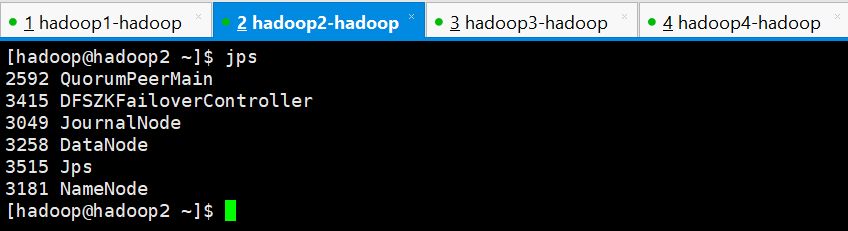
hadoop3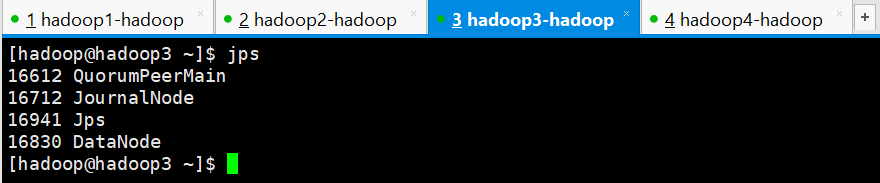
hadoop4
2.启动YARN
在主备 resourcemanager 中随便选择一台进行启动
[hadoop@hadoop4 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-resourcemanager-hadoop4.out
hadoop3: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop3.out
hadoop2: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop4: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop4.out
hadoop1: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop1.out
[hadoop@hadoop4 ~]$
正常启动之后,检查各节点的进程
hadoop1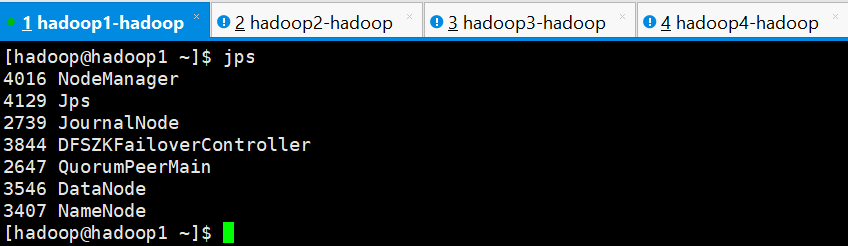
hadoop2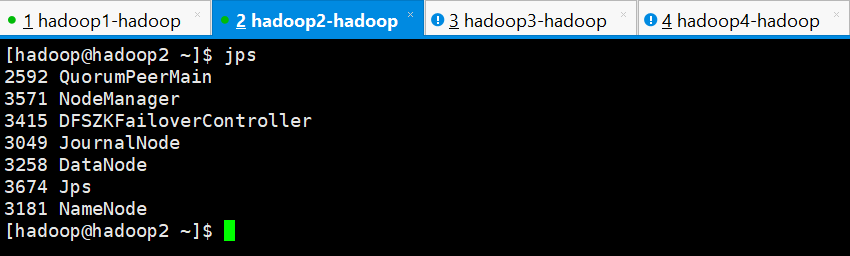
hadoop3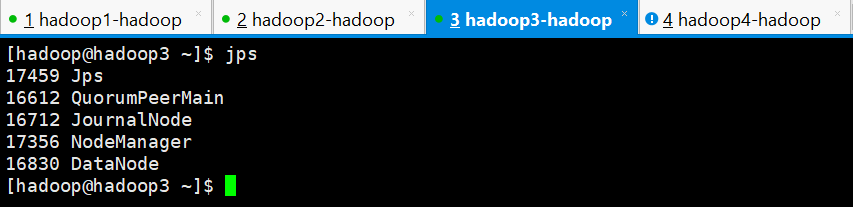
hadoop4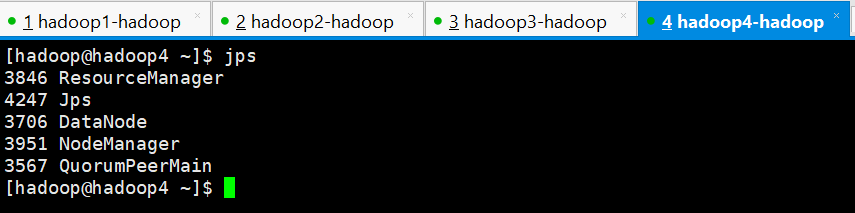
若备用节点的 resourcemanager 没有启动起来,则手动启动起来,在hadoop3上进行手动启动
[hadoop@hadoop3 ~]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-resourcemanager-hadoop3.out
[hadoop@hadoop3 ~]$ jps
17492 ResourceManager
16612 QuorumPeerMain
16712 JournalNode
17532 Jps
17356 NodeManager
16830 DataNode
[hadoop@hadoop3 ~]$
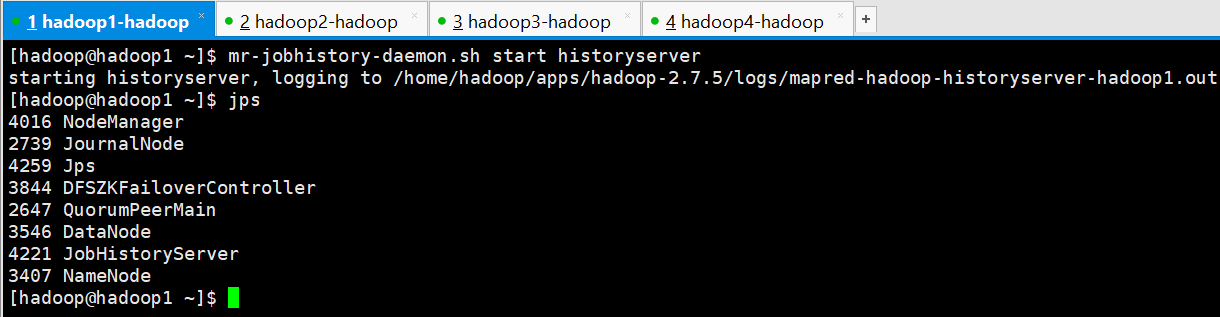
3.启动mapreduce任务历史服务器
[hadoop@hadoop1 ~]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/hadoop/apps/hadoop-2.7.5/logs/mapred-hadoop-historyserver-hadoop1.out
[hadoop@hadoop1 ~]$ jps
4016 NodeManager
2739 JournalNode
4259 Jps
3844 DFSZKFailoverController
2647 QuorumPeerMain
3546 DataNode
4221 JobHistoryServer
3407 NameNode
[hadoop@hadoop1 ~]$
4.查看各主节点的状态
HDFS
[hadoop@hadoop1 ~]$ hdfs haadmin -getServiceState nn1
standby
[hadoop@hadoop1 ~]$ hdfs haadmin -getServiceState nn2
active
YARN
[hadoop@hadoop4 ~]$ yarn rmadmin -getServiceState rm1
standby
[hadoop@hadoop4 ~]$ yarn rmadmin -getServiceState rm2
active
5.WEB页面查看
HDFS
hadoop1
http://hadoop1:50070/dfshealth.html#tab-overview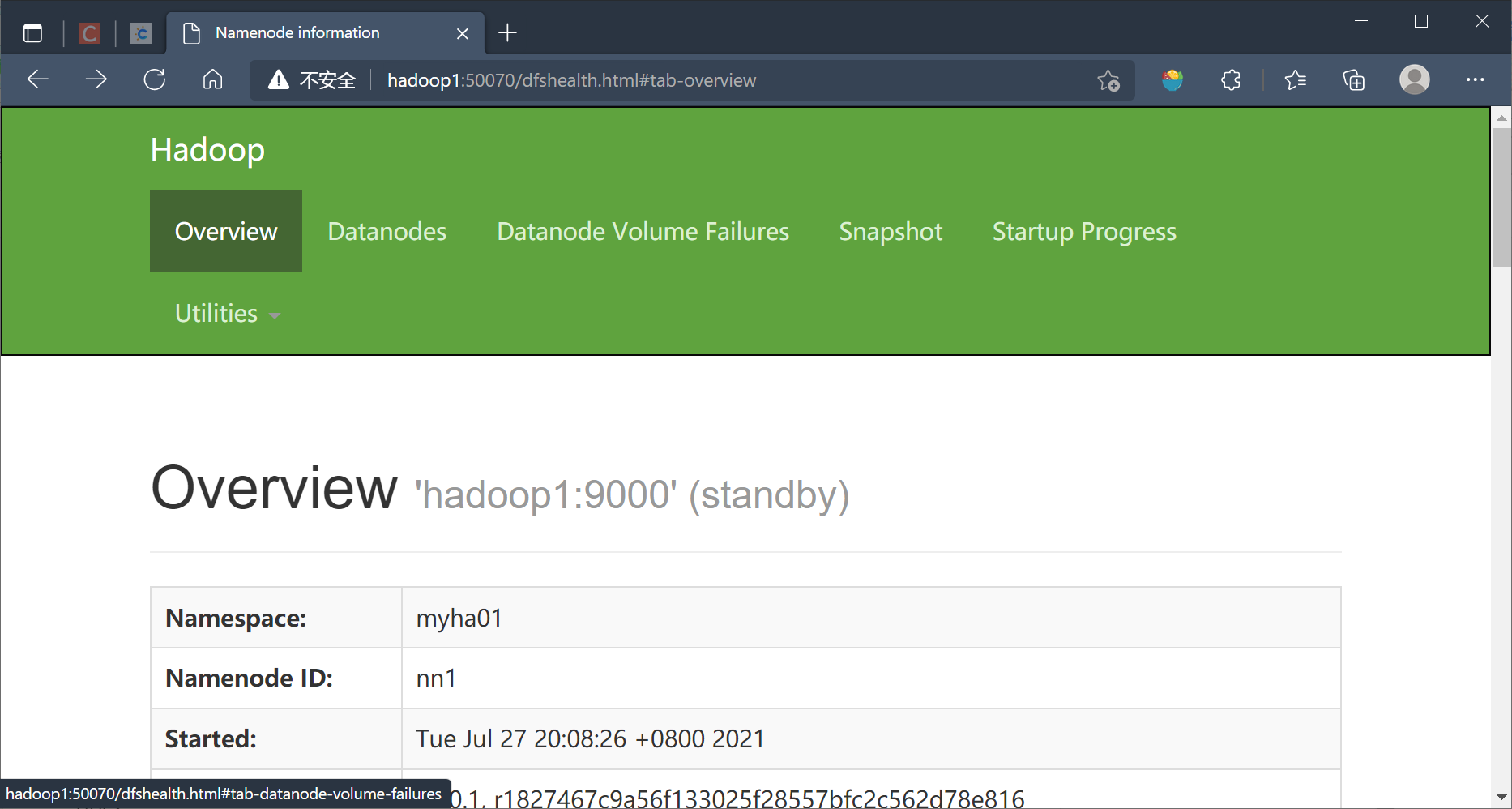
hadoop2
http://hadoop2:50070/dfshealth.html#tab-overview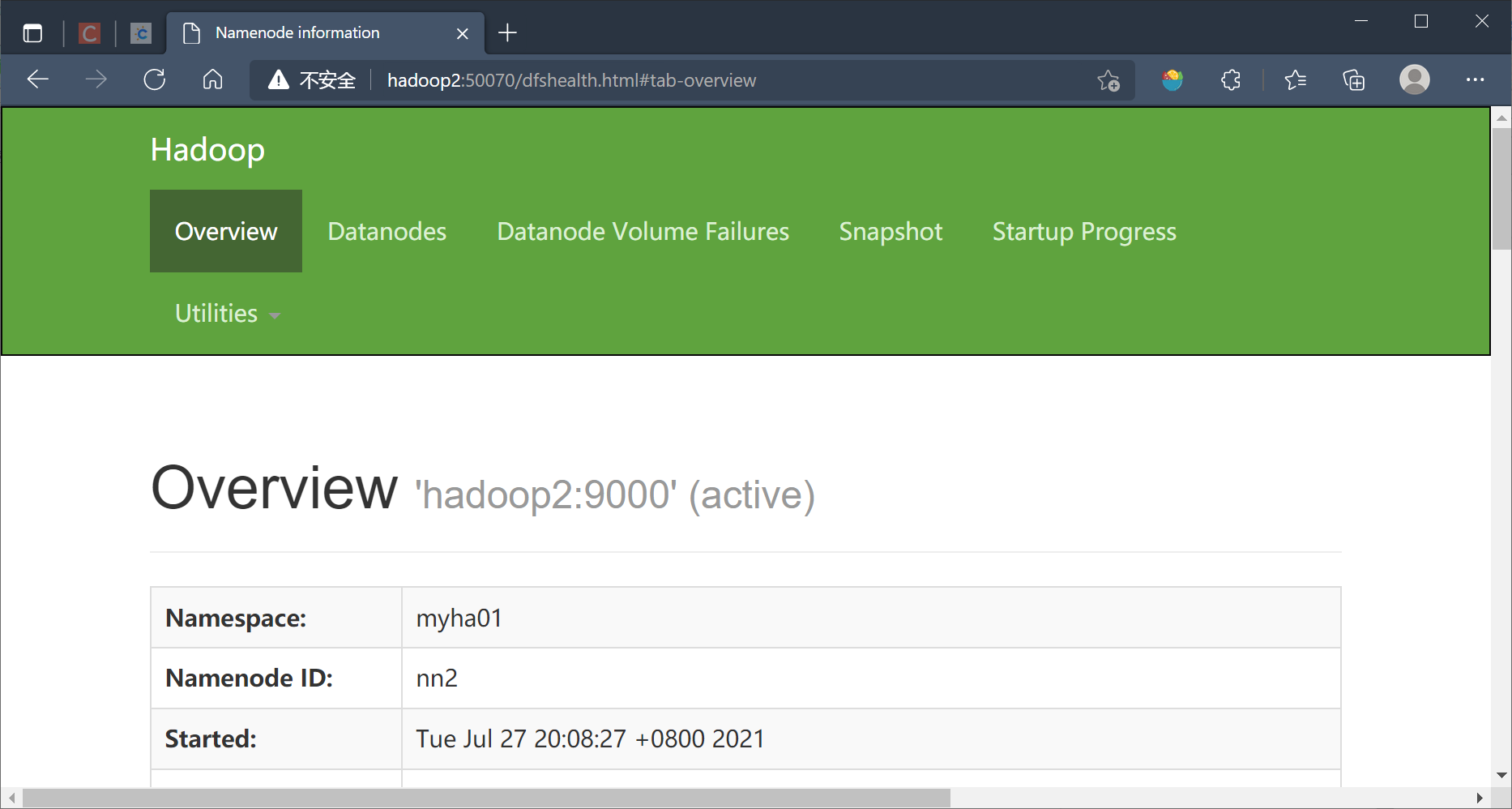
YARN
standby节点会自动跳到avtive节点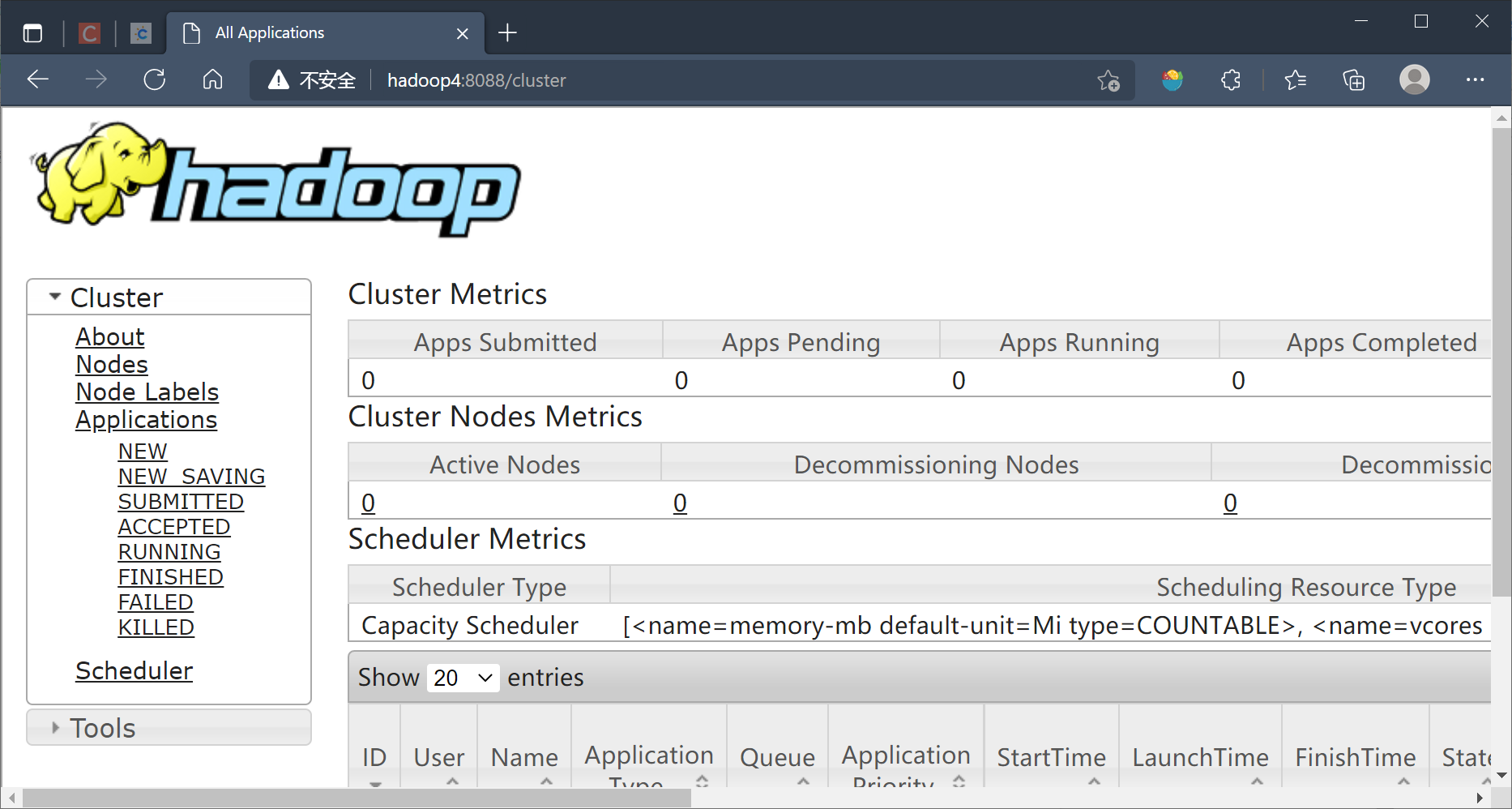
MapReduce历史服务器web界面
http://hadoop1:19888/jobhistory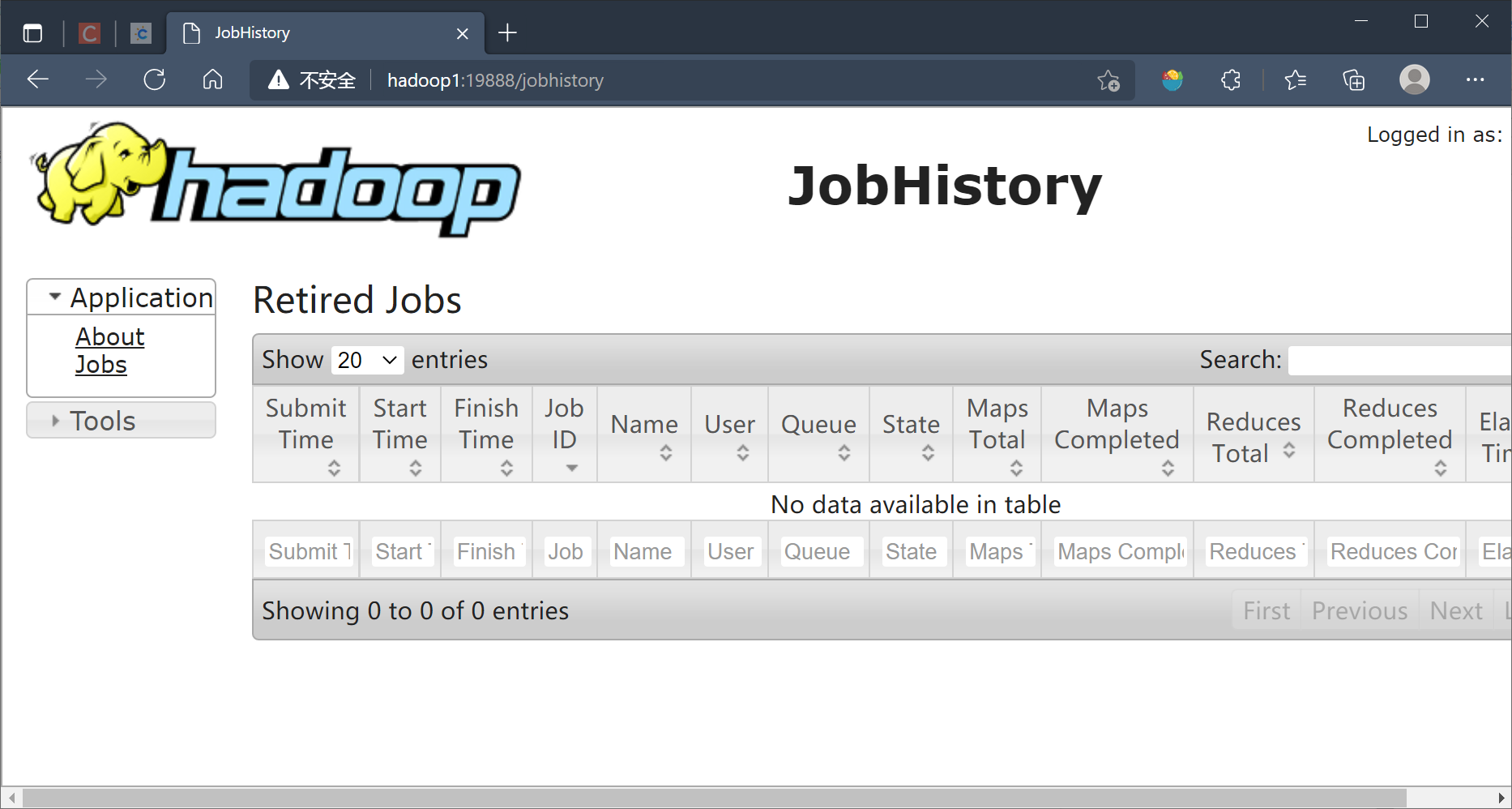
关闭集群
关闭 Hadoop 集群也是在 Master 节点上执行的:
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver

若有收获,就点个赞吧
0 人点赞
