要使用python的正则表达式,则需要使用re模板,下面我们简单看看re模块所具备的方法,然后再详
解。
正则匹配:
re.match(pattern, string, flags=0)或re.search(pattern, string, flags=0)或re.fullmatch(pattern, string, flags=0)
正则替换:
re.sub(pattern, repl, string, count=0, flags=0)或re.subn(pattern, repl, string, count=0, flags=0)
正则查找:
re.findall(pattern, string, flags=0)或re.finditer(pattern, string, flags=0)
正则切割:
re.split(pattern, string, maxsplit=0, flags=0)
re模块的4种使用方法中都有3个共同的参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 被匹配的字符串 |
| flags | 标志位,对应于正则规则表中的iLmsux匹配模式 |
而正则替换re.sub的特有参数有repl和count,分别表示被替换的表达式和替换的总次数。
正则切割re.split的特有参数是maxsplit,最大切割次数。
这些将在后面详解。下面首先详解flags标志位:
flags标志位:
| 简写 | 全称 | 含义 |
|---|---|---|
| A | ASCII | 让 \w , \W , \b , \B , \d , \D , \s 和 \S 只匹配ASCII,而不是Unicode。 |
| U | UNICODE | 与 ASCII 模式相反,让 \w , \W , \b , \B , \d , \D , \s 和 \S 匹配 Unicode 例如 \w 字符集同时会包含英文字符和中文字符 |
| I | IGNORECASE | 忽略大小写 |
| L | LOCALE | 由当前语言区域决定是ASCII还是UNICODE,以及是否大小写敏感,这个 标记只能对8位字节的byte数据有效。 由于语言区域机制很不可靠,这个标记不推荐使用,本文也不作演示。 |
| M | MULTILINE | 开启多行模式,当某字符串中有换行符 \n 时,让 ^ 和 $ 分别能匹配行的 开头和行的结尾,而不是整个字符串的开头和结尾 |
| S | DOTALL | DOT表示 . ,ALL表示所有, . 默认匹配除了换行符以外的任意字符。而 这个标志位让 . 匹配包含换行符 \n 的任意字符 |
| X | VERBOSE | 开启详细模式,可以在正则表达式中加python语法的#注释 |
| T | TEMPLATE | 关闭回溯,只使用模板匹配,提高正则的性能 |
| DEBUG | 显示编译时的debug信息。 |
在re模块库的源码中:https://github.com/python/cpython/blob/3.7/Lib/re.py
所有的flags标志位都定义在RegexFlag枚举类中:
class RegexFlag(enum.IntFlag):ASCII = A = sre_compile.SRE_FLAG_ASCII # assume ascii "locale"IGNORECASE = I = sre_compile.SRE_FLAG_IGNORECASE # ignore caseLOCALE = L = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit localeUNICODE = U = sre_compile.SRE_FLAG_UNICODE # assume unicode "locale"MULTILINE = M = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newlineDOTALL = S = sre_compile.SRE_FLAG_DOTALL # make dot match newlineVERBOSE = X = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments# sre extensions (experimental, don't rely on these)TEMPLATE = T = sre_compile.SRE_FLAG_TEMPLATE # disable backtrackingDEBUG = sre_compile.SRE_FLAG_DEBUG # dump pattern after compilation
使用方式:例如要忽略大小写就传入re.IGNORECASE 或简写的 re.I,要只匹配英文字符就传入re.ASCII
或简写的 re.A等等。如果需要同时使用多个模式,可以相加,例如我既要只匹配英文字符,还要开启多
行模式,可以传入re.A+re.M。
我们可以看一个每个标志位对应的二进制位:
for flag in re.RegexFlag:print(f"{flag.value:0>9b}", flag, flag.value)
结果:
100000000 RegexFlag.ASCII 256000000010 RegexFlag.IGNORECASE 2000000100 RegexFlag.LOCALE 4000100000 RegexFlag.UNICODE 32000001000 RegexFlag.MULTILINE 8000010000 RegexFlag.DOTALL 16001000000 RegexFlag.VERBOSE 64000000001 RegexFlag.TEMPLATE 1010000000 RegexFlag.DEBUG 128
可以看到每个模式数值对应的二进制位只占用1位。所以我们在使用多个模式时使用 或 运算符性能更
佳,例如re.A|re.M。
下面我们看下各种标示位的示例:
ASCII和UNICODE模式
简写与首字母一致。
对于字符串:
s = "Midea美的"
我们只希望匹配其中的英文,就需要使用ASCII模式:
re.search('\w+', s, re.ASCII).group(0)
结果:
'Midea'
注意: re.ASCII 可简写为 re.A
假如不设置ASCII模式,默认模式是UNICODE模式:
re.search('\w+', s).group(0)
结果:
'Midea美的'
IGNORECASE模式
简写与首字母一致。
对于下面的字符串,希望能找出所有的Python字符串,可以采用使用忽略大小写模式:
s = "Python1 python2 PYTHON3"re.findall('python', s, re.I)
由于I模式存在与(?iLmsux)中,还可以直接在正则里面写:
s = "Python1 python2 PYTHON3"re.findall('(?i)python', s)
结果均为:
['Python', 'python', 'PYTHON']
如果不设置忽略大小写模式:
s = "Python1 python2 PYTHON3"re.findall('python', s)
结果则为:
['python']
MULTILINE模式
简写与首字母一致。
例如对于下面这段字符串:
s = """数据分析软件工程数据分析师开发工程师数据分析工程师数据开发工程师"""
我们希望取出每行以数据分析开头的文本就可以开启多行模式:
re.findall('^数据分析.*', s, re.M)
也可以直接通过正则本身(iLmsux范围内的字符都支持)开启多行模式:
re.findall('(?m)^数据分析.*', s)
结果均为:
['数据分析', '数据分析师', '数据分析工程师']
当然,如果没有设置多行模式,^和$的作用与 \A 和 \Z 的作用一致,仅匹配整个字符串的开头和字符串
的结尾。
re.findall('^数据分析.*', s)
和
re.findall('\A数据分析.*', s, re.M)
结果均为:
['数据分析']
DOTALL模式
简写为S,并不是首字母。
例如我们有一段很长的sql脚本,我们希望能找到其中所有的以select(不区分大小写)开头的查询sql
语句:
s="""CREATE TABLE GIRL AS SELECT SNO, SNAME, AGE FROMSTUDENTS WHERE SEX = ' 女 ';SELECT CNO, CNAME FROM COURSES WHERE CREDIT = 3 ;-- 例 查询年龄大于 22 岁的学生情况。SELECT * FROMSTUDENTS WHERE AGE > 22 ;-- 例 找出籍贯为河北的男生的姓名和年龄。SELECT SNAME, AGE FROM STUDENTS WHERE BPLACE = ' 河北 ' AND SEX = ' 男 ' ;"""
如果我们不开启DOTALL模式会相对麻烦一点,需要使用 [\w\W] 来表示包含换行符的所有字符:
re.findall('^select [\w\W]+?;', s, re.I|re.M)
或:
re.findall('(?im)^select [\w\W]+?;', s)
结果:
['SELECT CNO,CNAME FROM COURSES WHERE CREDIT=3;','SELECT \n * \nFROM\n STUDENTS \nWHERE AGE > 22;',"SELECT \n SNAME,\n AGE \nFROM\n STUDENTS \nWHERE BPLACE = '河北' \n AND SEX = '男';"]
但开启DOTALL模式,就可以直接使用 . 来匹配包含换行符的所有字符,即:
re.findall('^select .+?;', s, re.I|re.M|re.S)
或:
re.findall('(?ims)^select .+?;', s)
VERBOSE模式
简写为X,并不是首字母。
该模式的作用就是可以在正则中写#号的注释,对于很复杂的正则,或许我们使用注释会更加清晰易
懂。
例如我们有段字符串:
s = """中楼层(共9层)|2007年建|1室1厅|24.78平米|北地下室|2014年建|1室0厅|39.52平米|东底层(共2层)5室3厅|326.56平米|东南西北"""
我们需要提取出每行数据的 层、楼层数、建筑年份、户型、大小和方向。
如果直接写,或许这个正则阅读起来比较费劲:
re.findall("^([^|(]+)(?:\(共(\d+)层\))?(?:\|(\d{4})年建\|)?(\d室\d厅)\| ([\d.]+)平米\|([东南西北]+)", s, re.M)
于是我们可以开启VERBOSE模式加个注释:
pattern = """^([^|(]+?) # 层(?:\(共(\d+)层\))? # 楼层数(?:\|(\d{4})年建\|)? # 建筑年份(\d室\d厅) # 户型 \|([\d.]+)平米 # 大小\|([东南西北]+) #方向"""re.findall(pattern, s, re.M|re.X)
也可以直接使用正则字符串本身来开启VERBOSE(简写X)模式:
pattern = """(?mx)^([^|(]+?) # 层(?:\(共(\d+)层\))? # 楼层数(?:\|(\d{4})年建\|)? # 建筑年份(\d室\d厅) # 户型 \|([\d.]+)平米 # 大小\|([东南西北]+) #方向"""re.findall(pattern, s)
结果均为:
[('中楼层', '9', '2007', '1室1厅', '24.78', '北'),('地下室', '', '2014', '1室0厅', '39.52', '东'),('底层', '2', '', '5室3厅', '326.56', '东南西北')]
再来一个简单的示例:
pattern = r'''(?mx) ^ # 开头(\d{4}) # 年 [ ] # 空格(\d{2}) # 月 $ # 结尾'''re.findall(pattern, '2020 06\n2020 07')
结果:
[('2020', '06'), ('2020', '07')]
当然,正则本身也支持通过 (?#ABC) 增加注释 ABC ,例如:
"(\w+)(?#word) \1(?#word repeat again)"
TEMPLATE模式
简写与首字母一致。
该模式的作用是关闭回溯,在前面的贪婪模式、非贪婪模式和独占模式一节中,已经讲解过回溯的过
程,贪婪模式和非贪婪模式都需要发生回溯才能完成相应的功能。
TEMPLATE表示模板的意思,开启该模式意味着只能使用正则的模板匹配,而不能使用回溯算法,意味
着不能再使用任意数量词,包括*、?、+、{m,n}等,哪怕固定数量的{4}也不允许。
例如我们想要获取一个时间字符串的年月日:
s = "1980-02-12"re_match = re.match(r'(\d{4})-(\d{2})-(\d{2})', s)re_match.group(1), re_match.group(2), re_match.group(3)
结果:
('1980', '02', '12')
很明显这个时间字符串的每个部分,长度都是确定而且固定的,那我们就完全可以开启TEMPLATE模
式,关闭回溯算法。
但直接关闭会报错:
s = "1980-02-12"re_match = re.match(r'(?t)(\d{4})-(\d{2})-(\d{2})', s) re_match.group(1), re_match.group(2), re_match.group(3)
error: internal: unsupported template operator MAX_REPEAT
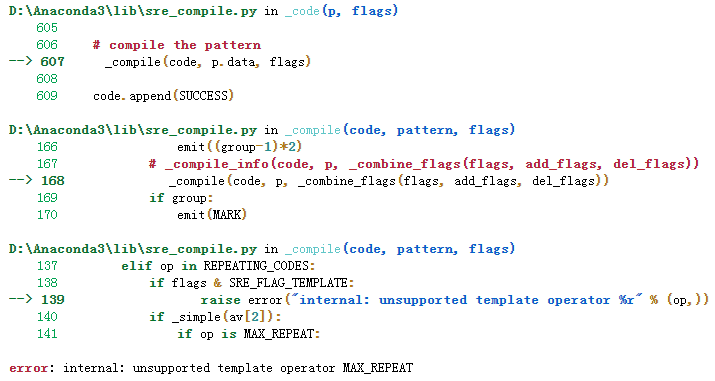
必须这样写:
s="1980-02-12"re_match=re.match('(\d\d\d\d)-(\d\d)-(\d\d)',s,re.T)re_match.group(1),re_match.group(2),re_match.group(3)
或
s = "1980-02-12"re_match = re.match('(?t)(\d\d\d\d)-(\d\d)-(\d\d)', s)re_match.group(1), re_match.group(2), re_match.group(3)
这个模式目前连官网文档没有任何说明,开启这个模式能否相对直接执行不会发生回溯的正则是否能提
升效率还未知。
DEBUG模式
这个模式没有简写,对于一般的用户用不上。开启这个模式之后,编译正则表达式时会打印出正则的解
释树信息,这些信息并不是任何一种编程语言,而是正则表达式特有的解析树,就类似于hive sql语句
编译的解析树一样。通过解析树可以让高级开发人员更清楚了解这个正则执行的性能和效率。
我们随便查看一个正则的编译信息:
re.compile('(\d{2}) ?-12', re.DEBUG)
结果:
SUBPATTERN 1 0 0MAX_REPEAT 2 2INCATEGORY CATEGORY_DIGITMAX_REPEAT 0 1LITERAL 32LITERAL 45LITERAL 49LITERAL 500. INFO 4 0b0 5 6 (to 5)5: MARK 07. REPEAT_ONE 9 2 2 (to 17)11. IN 4 (to 16)13. CATEGORY UNI_DIGIT15. FAILURE16: SUCCESS17: MARK 119. REPEAT_ONE 6 0 1 (to 26)23. LITERAL 0x20 (' ')25. SUCCESS26: LITERAL 0x2d ('-')28. LITERAL 0x31 ('1')30. LITERAL 0x32 ('2')32. SUCCESS

若有收获,就点个赞吧
0 人点赞
