一:框架构思
(此代码只作为简单演示使用,因为好多问题没有考虑到,时间有限,没有做参数化,没有重跑机制,代码规范等等,请各位仅供参考。)
base:是基于seleniium的二次封装的点击、输入、刷新等操作
common:是基于业务的底层公共方法
config:配置文件
log:收集log的方法,以及生成的截图
excute_logs:生成的日志都会打印在一个文件
page_object:webui登录的方法和一些二次封装的方法
testcase:是testcase
reports:是生成reports的方法和生成的报告
二:框架代码展示
base_page.py文件
# coding=utf-8import timefrom time import sleepfrom log.getLogStream import logStreamlog = logStream()# 创建基类class BasePage:# driver = webdriver.Chrome()# 构造函数def __init__(self, driver):log.info('初始化driver{}'.format(driver))self.driver = driver# 访问URLdef open(self, url):"""function: 打开浏览器,访问urldescription:arg:return:"""log.info('访问网址')self.driver.get(url)self.driver.maximize_window()sleep(3)# 元素定位def locator(self, loc):"""function: 定位元素description:arg:return:"""log.info('正在定位{}元素'.format(loc))return self.driver.find_element(*loc)# 输入def input_(self, loc, txt):"""function: 输入description:arg:return:"""try:log.info('正在定位{}元素, 输入{}内容'.format(loc, txt))self.locator(loc).send_keys(txt)sleep(2)except Exception as e:self.screenShot()log.error('错误日志' % e)# 点击def click(self, loc):"""function: 点击description:arg:return:"""try:log.info('正在点击{}元素'.format(loc))self.locator(loc).click()except Exception as e:self.screenShot()log.error('错误日志' % e)# 等待def wait(self, time_):"""function: 等待description:arg:return:"""log.info('等待时间{}秒'.format(time_))sleep(time_)# 关闭def quit(self):"""function: 退出description:arg:return:"""log.info('退出')self.driver.quit()# 最大化def maxSize(self):"""function: 最大化description:arg:return:"""log.info('最大化')self.driver.maximize_window()# 截图并保存def screenShot(self):"""function: 绑定服务器description: bind服务器arg:return:"""current_time = time.strftime('%Y-%m-%d %H-%M-%S')print(current_time)pic_path = '../log/screenshot' + '/' + current_time + '.png'self.driver.save_screenshot(pic_path)# 关闭浏览器def close(self):"""function: 关闭当前浏览器description:arg:return:"""self.driver.close()# 刷新浏览器def refresh(self):"""function: 刷新浏览器description:arg:return:"""self.driver.refresh()def waitUntilPageContains(self, message):"""function: 等待界面出现某个字段description:arg::return:example: self.waitUntilPageContains('vsite_automation')"""log.info('正在获取页面%s字段' % message)sleep(3)msg = self.driver.find_element_by_xpath('//*[contains(text(), "%s")]' % message).textprint(msg)return msg
common目录下的业务文件
import paramikofrom time import sleepimport reclass CLI:def ssh_ag(self):""":param self::return:"""# 创建ssh对象self.ssh = paramiko.SSHClient()# 允许连接不在know_hosts文件中的主机self.ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)# 连接AGself.ssh.connect(hostname='192.168.120.220', port=22, username='gaojs', password='123')sleep(5)channel = self.ssh.invoke_shell()self.channel = channelchannel.settimeout(5)sleep(5)self.cli_cmd('enable')self.cli_cmd('')self.cli_cmd('config ter')def print_step(self):""":return:"""result = self.channel.recv(2048)print(result.decode())
getLogStream.py收集日志文件
import loggingdef logStream():# 创建一个日志器logger = logging.getLogger()# 设置日志级别为infologger.setLevel(logging.INFO)# 日志想要输出到哪,就要制定输出目的地,控制台 要创建一个控制台处理器console = logging.StreamHandler()logger.addHandler(console)# 创建一个格式器# 设置日志格式fmt = '%(asctime)s %(filename)s %(levelname)s %(module)s %(funcName)s %(message)s'# 生成日志信息 生成时间 文件名 日志的状态 类名 方法名 日志内容fomator = logging.Formatter(fmt)# 优化及控制台格式console.setFormatter(fomator)# 创建一个处理器 文本处理器 制定日期信息输出到文本处理器filehandler = logging.FileHandler('../excute_logs/logger.log', encoding='utf-8')logger.addHandler(filehandler)# 设置logger.log文本格式filehandler.setFormatter(fomator)return logger
base_logging.py文件
import loggingdef logger():# 设置日志格式fmt = '%(asctime)s %(filename)s %(levelname)s %(module)s %(funcName)s %(message)s'# 生成日志信息 生成时间 文件名 日志的状态 类名 方法名 日志内容# 设置日志级别logging.basicConfig(level=logging.INFO, format=fmt, filename='../excute_logs/log.log')return logging
page_object目录下的login_page.py文件
from time import sleepfrom selenium.webdriver.common.by import Byfrom base.base_page import BasePagefrom selenium import webdriverclass LoginPage(BasePage):def login(self, username, password):"""description:登录webui界面:param username::param password::return:example:self.login('array', 'admin')"""self.driver = webdriver.Chrome()# URL# self.url = "https://%s:%s" % ip, portself.url = "https://192.168.120.209:8888"# 页面元素self.user = (By.NAME, "username")self.passwd = (By.ID, 'password')self.button = (By.ID, 'loginID')# 访问URL,最大化self.open(self.url)# 点击页面上不是隐私连接提示try:self.waitUntilPageContains('不是私密连接')self.driver.find_element_by_xpath('//button[@id="details-button"]').click()sleep(1)self.driver.find_element_by_xpath('//a[@id="proceed-link"]').click()except:pass# 输入账号sleep(5)self.input_(self.user, username)# 输入密码self.input_(self.passwd, password)# 点击登录按钮self.click(self.button)sleep(5)def login_L3vpn_test(self, ip, method, username, password, challenge=None, challenge_passwd1=None, challenge_passwd2=None):"""function:登录L3vpn:argument:ip: 虚拟站点IPmethod:方法名username:用户名password:密码:return:examlpe:self.login_L3vpn_test('192.168.120.x', 'http_challenge', 'array', 'admin')self.login_L3vpn_test(self.vsiteip, 'http_challenge_test', self.username, self.passwd,challenge=True, challenge_passwd1='chal1', challenge_passwd2='chal2')"""self.driver = webdriver.Chrome()# URLself.url = "https://%s" % ip# 页面元素self.user = (By.NAME, "uname")self.passwd = (By.NAME, 'pwd')self.button = (By.NAME, 'submitbutton')self.select_method = (By.NAME, "method")self.challenge_signin = (By.NAME, "option")# 访问URL,最大化self.open(self.url)sleep(5)try:self.driver.find_element_by_xpath('//button[@id="details-button"]').click()sleep(1)self.driver.find_element_by_xpath('//a[@id="proceed-link"]').click()except:pass# 切换方法self.click(self.select_method)self.driver.find_element_by_xpath('//option[@value="%s"]' % method).click()# 输入账号sleep(5)self.input_(self.user, username)# 输入密码self.input_(self.passwd, password)# 点击登录按钮self.click(self.button)sleep(5)# 挑战模式if challenge:try:self.input_(self.passwd, challenge_passwd1)self.click(self.challenge_signin)self.input_(self.passwd, challenge_passwd2)self.click(self.challenge_signin)self.waitUntilPageContains('welcome to the ArrayOS')except Exception as e:print(e)print('挑战失败,请重试!')else:print('不符合挑战条件,请检查配置!')
reports目录下的testReports.py文件
import time
import unittest
from BeautifulReport import BeautifulReport
# 找到用例defaultTestLoader默认加载
# import HTMLTestRunner
def testReports():
"""
function: 生成测试报告方法
description: 生成测试报告
arg:
return:
"""
case_dir = '../testcase/aaa_http/'
discover = unittest.defaultTestLoader.discover(case_dir, 'test*.py')
# 用时间命名测试报告 测试报告生成时间 + 后缀名 2021-11-20 14-49-30test_report.html
report_dir = '../reports/'
now = time.strftime('%Y-%m-%d %H-%M-%S')
report_name = report_dir + '/' +now+ '_test_report.html'
with open(report_name, 'wb') as f:
# 执行用例
# HTMLTestRunner.HTMLTestRunner(stream=f, verbosity=2, title='unittest测试报告练习', description='练习HTMLTestRunner使用').run(discover)
BeautifulReport(discover).report(description=u'UAG每日构建测试报告', filename=report_name, report_dir='../reports/')
run.py文件:
from reports.testReports import testReports
if __name__ == "__main__":
testReports()
三:用例代码
testcase目录下的test_01文件
import unittest
from common.agCli import *
from page_object.login_page import *
class Testcase(unittest.TestCase, LoginPage, CLI):
def setUp(self) -> None:
self.ssh_ag()
self.vsitename = 'vsite_automation'
self.username = 'array'
self.passwd = 'admin'
self.message = 'vsite_automation'
def test_01(self):
"""
description: cli创建虚拟站点,登录webui去查看是否创建成功,是否有vsite_automation虚拟站点信息
:return:
date: 2022/02/17
author: gaojs
"""
self.cli_cmd('virtual site name vsite_automation')
self.login(self.username, self.passwd)
self.switch_vsite(self.vsitename)
msg = self.waitUntilPageContains(self.message)
print(msg)
if msg not in(self.message):
raise Exception('切换虚拟站点失败,请重试!')
# 恢复环境
def tearDown(self) -> None:
self.cli_cmd('no virtual site name vsite_automation')
self.cli_cmd('YES')
self.quit_enable()
self.close()
压力测试用例test_02:
from locust import HttpUser, between, task, TaskSet
import os
from common.agCli import *
import logging
class TaskTest(TaskSet, CLI):
# 执行并发前置动作,比如清理当前所有session
def on_start(self):
"""
description:登录ag, 清理log
:return:
"""
self.ssh_ag()
self.clear_log()
logging.info('清理log结束,压测开始!!!')
# 压测任务,也可以是@task(10)啥的,这个数字是代表权重,数值越大,执行的频率就越高
@task
def login(self):
url = '/prx/000/http/localh/login'
data = {
"method": "http1",
"uname": "gaojs",
"pwd1": "",
"pwd2": "",
"pwd": "admin",
"submitbutton": "Sign"
}
header = {"Content-Type": "application/json;charset=UTF-8"}
self.client.request(method='POST', url=url, data=data, headers=header, name='登录虚拟站点', verify=False, allow_redirects=False)
# 执行并发测试后执行的动作,比如保存log等操作,查看报告http://localhost:8089/
def on_stop(self):
self.ssh_ag()
self.cli_cmd('switch vsite')
self.cli_cmd('session kill all')
logging.info('清理session结束,压测结束,请查看report, http://localhost:8089!!!')
class Login(HttpUser):
host = 'https://192.168.120.206'
# 每次请求停顿时间
wait_time = between(1, 3)
tasks = [TaskTest]
if __name__ == "__main__":
os.system("locust -f locust_test.py --host=https://192.168.120.206")
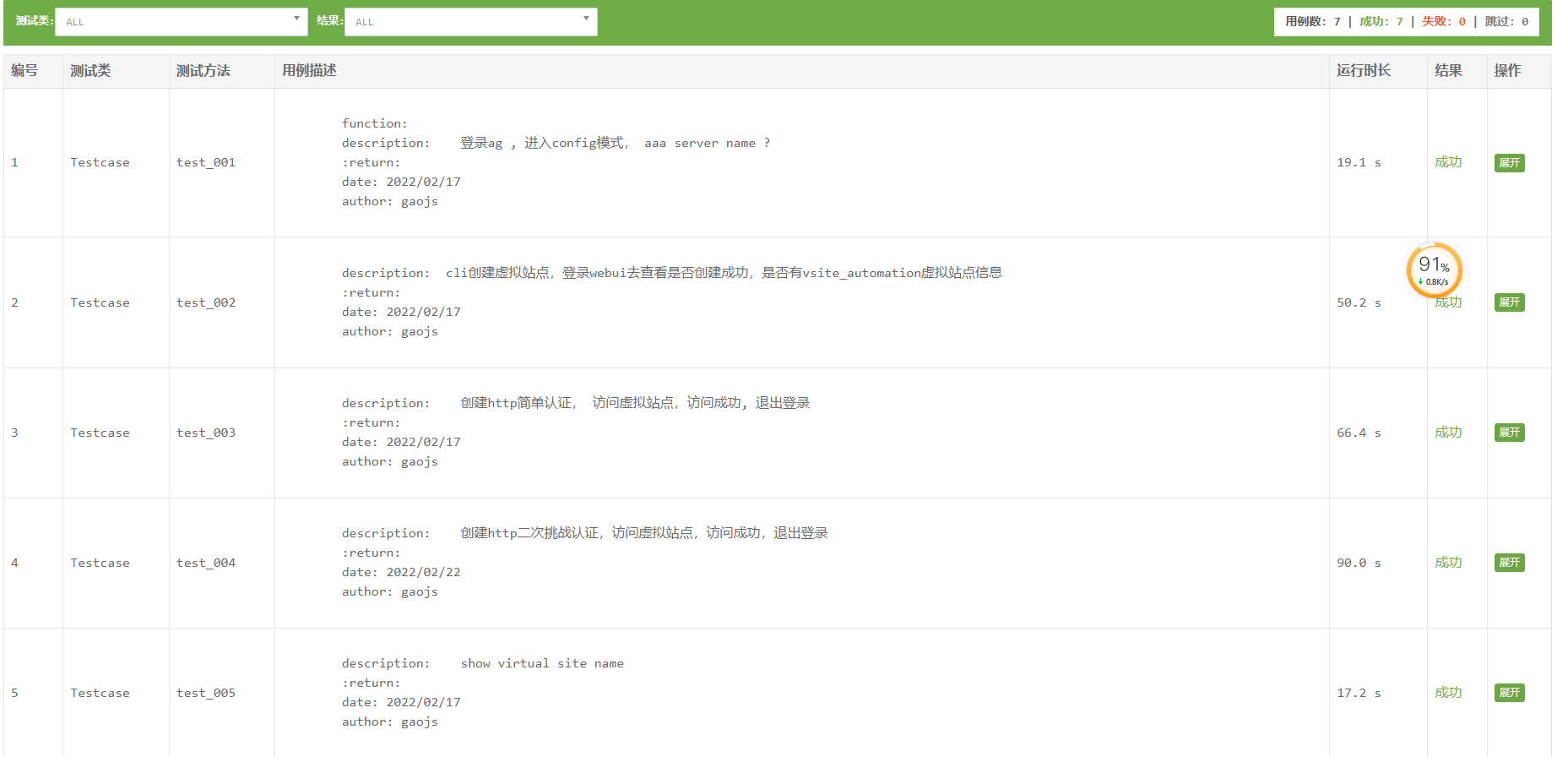
四:测试报告
生成报告展示: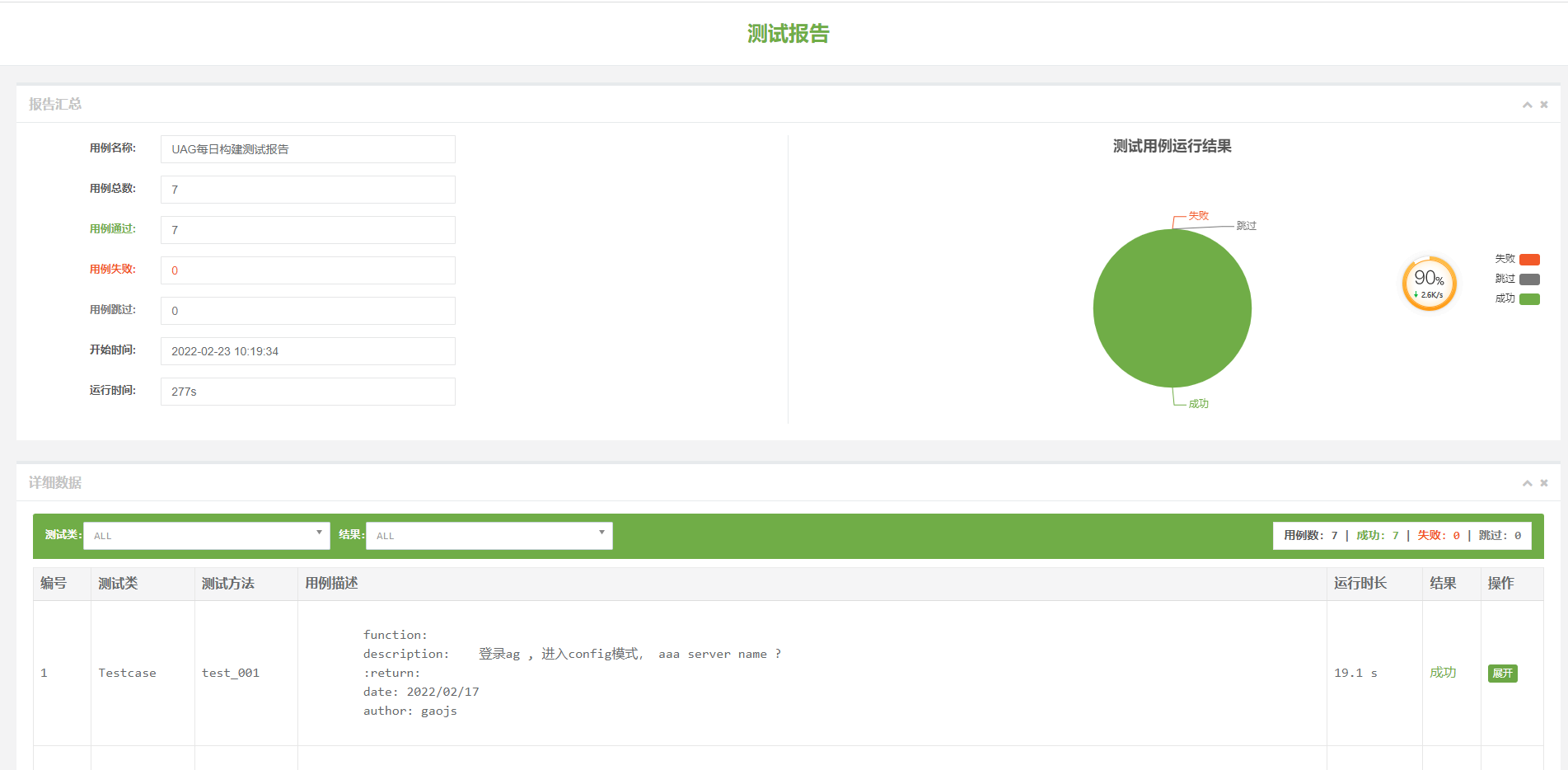

若有收获,就点个赞吧
0 人点赞
