流(stream)在 Node.js 中是处理流数据的抽象接口(abstract interface)
- Node.js诞生之初就是为了提高IO性能(解决IO密集型问题)
- Node.js内置Stream,实现了流操作对象
流是一个抽象接口,被 Node 中的很多对象所实现。比如HTTP服务器request和response对象都是流,文件操作系统和网络模块实现了流接口
应用程序中为什么使用流来处理数据?
场景:观看高清电影
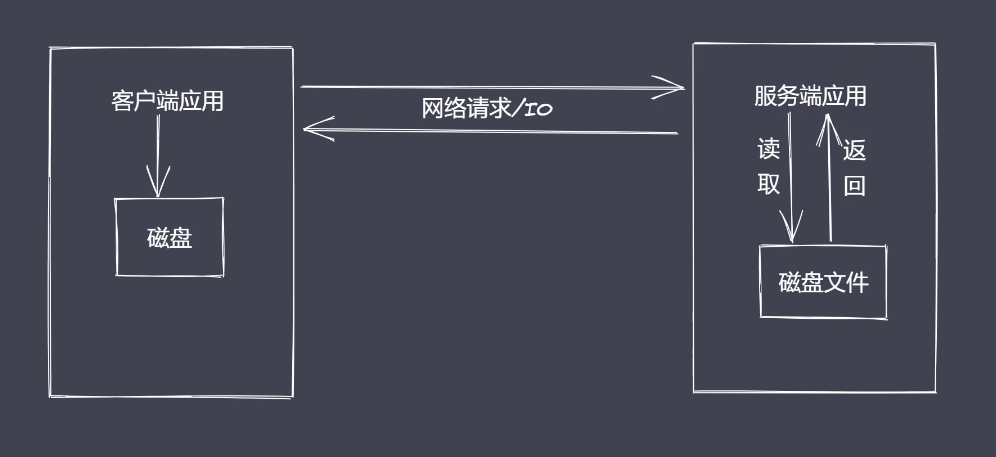
常见问题
- 同步读取资源文件,用户需要等待数据读取完成
- 资源文件最终一次性加载至内存,开销较大(V8提供的内存1.4G)64位约1.4G,32位约0.7G
- 实现数据缓冲,和数据操作
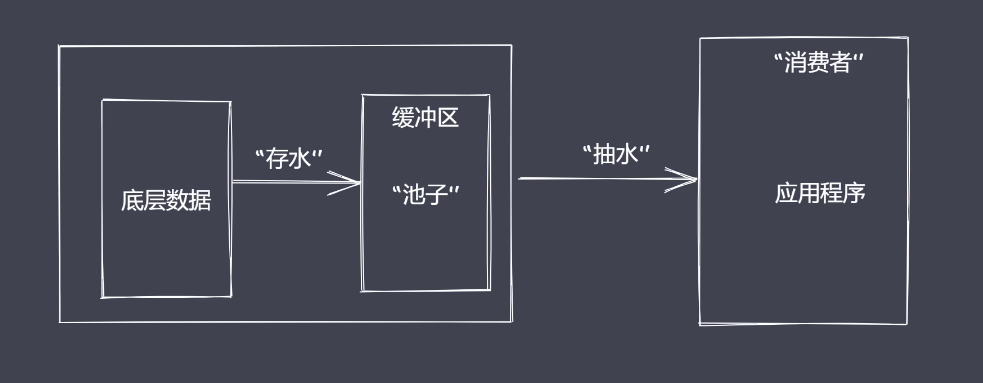
流处理数据的优势
- 时间效率:流的分段处理可以同时操作多个数据chunk
- 空间效率:同一时间流无须占据大内存空间
-
Node.js中流的分类
Readable:可读流,能够实现数据的读取 (例如 fs.createReadStream())
- Writeable:可读流,能够实现数据的写操作 (例如 fs.createWriteStream())
- Duplex:双工流, 既可读又可写 (例如 net.Socket)
Tranform:转换流,可读可写,还能实现数据转换 (例如 zlib.createDeflate())
Node.js流特点
Stream模块实现了四个具体的抽象
- 所有流都继承自EventEmitter(可以去基于发布订阅的模式,让他们可以发布数据的读写事件,事件循环监控事件时机) ```javascript // 拷贝文件 const fs = require(‘fs’) let rs = fs.createReadStream(‘./test.txt’) let ws = fs.createWriteStream(‘./test1.txt’)
// 复制 rs.pipe(ws)
<a name="k5znn"></a>### 可读流(生产数据)- 是生产供程序消费数据的流(数据源)```javascriptconst fs = require('fs')// 创建了一个可读流const rs = fs.createReadStream('00-note.txt')// 管道操作,传递给process.stdoutrs.pipe(process.stdout)
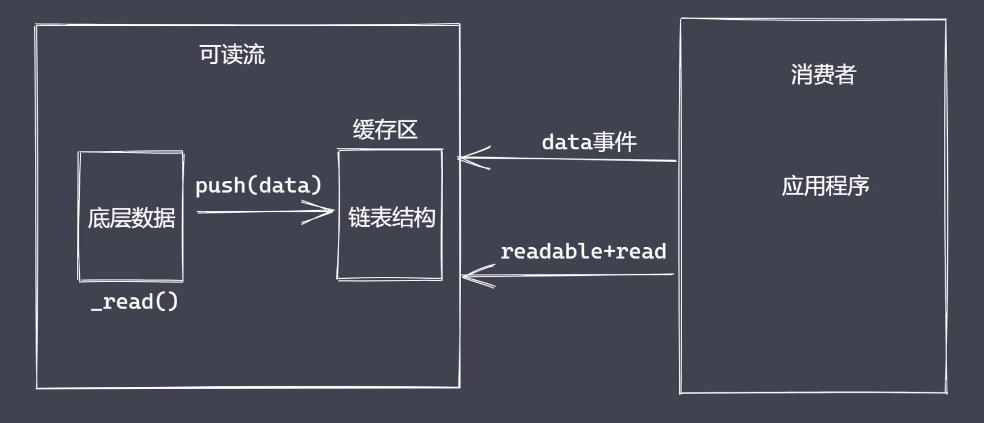
可读流事件
- 常用操作:监听以下两个事件
- readable事件:当流中存在可读取数据时触发
- data事件:当流中数据块传给消费者后触发
- 两种读取模式:
- 流动模式:数据会从底层系统读取,并通过 EventEmitter 尽快的将数据传递给所注册的事件处理程序中
- 暂停模式:在这种模式下将不会读取数据,必须显示的调用 Stream.read () 方法来从流中读取数据
- 三种状态:
- readableFlowing === null:不会产生数据,调用 Stream.pipe ()、Stream.resume 会使其状态变为 true,开始产生数据并主动触发事件
- readableFlowing === false:此时会暂停数据的流动,但不会暂停数据的生成,因此会产生数据积压
- readableFlowing === true:正常产生和消耗数据
- _read 方法是把数据存在缓存区中,因为是异步的,流是通过readable事件来通知消耗方的。
说明一下,流中维护了一个缓存,当缓存中的数据足够多时,调用read()不会引起_read()的调用,即不需要向底层请求数据。state.highWaterMark是给缓存大小设置的一个上限阈值。如果取走n个数据后,缓存中保有的数据不足这个量,便会从底层取一次数据
自定义可读流
继承stream里的Readable
- 重写_read方法调用push产出数据 ```javascript const { Readable } = require(“stream”);
// 模拟底层数据 let source = [“lg”, “zce”, “syy”];
// 自定义类继承 Readable
class MyReadable extends Readable { constructor(source) { super(); this.source = source; }
_read() { // 对数据进行添加的操作,操作完之后往source里面传一个null,这样底层才知道读完了 // push(null)结束推送 let data = this.source.shift() || null; this.push(data); // push方法是继承Readable readable.push } }
// 实例化 let myReadable = new MyReadable(source);
// 暂停模式 所有的流操作继承了EventEmitter myReadable.on(“readable”, () => { // console.log(1); // 打印了两次1, // 默认的是暂停模式, let data = null; // read(2)可以传入指定的数据长度 while ((data = myReadable.read(2)) !== null) { console.log(data.toString()); } });
// 流动模式 myReadable.on(‘data’, (chunk) => { // 不需要往缓存中放,直接读取了 console.log(chunk.toString()); })
<a name="IRG1e"></a>
#### 自定义可读流问题
- 底层数据读取完成之后如何处理? 读取完之后可以给source传递一个null值,让底层知道读取完了
- 消费者如何获取可读流中的数据?
- 消费数据为什么存在二种方式?流动模式,暂停模式(满足不同的场景)
<a name="VVwN3"></a>
#### 可读流总结
- 明确数据生产与消费流程
- 利用API实现自定义的可读流
- 明确数据消费的事件使用
<a name="lVeQt"></a>
### 可写流(消费数据)
- 用于消费数据的流
```javascript
const fs = require('fs')
// 创建一个可读流,生产数据
let rs = fs.createReadStream('test.txt')
// 修改字符编码,便于后续使用
rs.setEncoding('utf-8')
// 创建一个可写流,消费数据
let ws = fs.createWriteStream('02test.txt')
// 监听事件调用方法完成具体的消费
rs.on('data',(chunk) => {
// 写入数据
ws.write(chunk)
})
自定义可写流
- 继承stream模块的Writeable
- 重写_write方法,调用write执行写入 ```javascript const { Writable } = require(“stream”); class MyWriteable extends Writable{ constructor(){ super() } // 参数:执行写入的数据,当前写入的编码集,回调 _write(chunk, en ,done){ process.stdout.write(chunk.toString() + ‘<——‘) process.nextTick(done) // 放入异步,让在同步代码之后再执行回调 } }
let myWriteable = new MyWriteable()
myWriteable.write(‘早上好啊’,’utf-8’,() => { console.log(‘end’); })
<a name="da4Ru"></a>
#### 可写流事件
- pipe事件:可读流调用pipe()方法时触发(数据的到来)
- unpipe事件:可读流调用unpipe()方法时触发(数据的切断)
<a name="NnoSX"></a>
### 双工流和转换流(Duplex && Transform)
- 可读、可写、双工、转换是单一抽象具体实现
- 流操作的核心功能就是处理数据
- Nodejs诞生的初衷就是解决密集型IO事务
- Nodejs中处理数据模块继承了流和EventEmitter
- stream、四种类型流、实现流操作的模块
<a name="lhPUK"></a>
#### Duplex双工流(实现了Readable和Writable)
- 既能生产又能消费
<a name="zx7JE"></a>
#### 自定义双工流
1. 继承Duplex类
1. 重写_read方法,调用push生产数据
1. 重写_write方法,调用write消费数据
```javascript
const { Duplex } = require('stream')
// 继承Duplex,重写_read和_wirte方法
class MyDuplex extends Duplex{
constructor(source){
super() // 父类的构造方法执行起来
this.source = source
}
_read(){
// 模拟从底层读取的数据,读取完,传null
let data = this.source.shift() || null
this.push(data) // push(null)结束推送
}
// 参数:操作的数据,字符编码,回调
_write(chunk, en, next){
// 消耗数据,放在可写流写出
process.stdout.write(chunk)
// 在上面执行完之后执行回调,这里采用异步操作
process.nextTick(next)
}
}
let source = ['a','b','c']
let myDuplex = new MyDuplex(source)
// myDuplex.on('data', (chunk) => {
// console.log(chunk.toString());
// })
myDuplex.write('早上好',() => {
console.log(111);
})
Transform转换流,也是双工流
- 继承Transform类
- 重写_transform方法,调用push和callback
- 重写_flush 方法,处理剩余数据
自定义转换流
```javascript const { Transform } = require(‘stream’)
class MyTransform extends Transform{ constructor(){ super() }
_transform(chunk, en, cb){ // 放在可读流里面 push方法是继承Readable readable.push this.push(chunk.toString().toUpperCase()) cb(null) // 如果要把原始的数据给进去,加chunk } }
let t = new MyTransform() // 可读写 t.write(‘a’)
t.on(‘data’, (chunk) => { console.log(chunk.toString()); }) ```
Duplex和Transform的区别
- Duplex的读和写是相互独立的,读操作的数据不能被写操作直接当作数据源使用的
Transform是可以的,转换流的底层将读写操作进行了连通,同时转换流还可以对相应的数据进行转换操作(相应:自己定义实现)
Nodejs中四种流
Readable 可读流(生成数据的,常用:监听readable和data事件,Readable是需要我们主动调用read方法来消耗数据的,data就是一个流动模式,他可以一直去读,当然流动和暂停是可以切换的)
- Writeable 可写流(专门消费数据的流,主要是调用write方法,然后再把数据源里的数据写入指定的位置)
- Duplex 双工流(可读可写,但是两者是独立的)
- Transform转换流(可读可写,中间可以添加数据的转换操作,可写流和可读流是打通的,非常利用在中间管道传输中做状态处理)
推荐大佬文章
本文章只是作为初学者了解Node流模块,如果深入,请看下面大佬文章和官方文档,总结极全
Node.js 流源码解读之可读流

若有收获,就点个赞吧
0 人点赞
