Java 集合概览
Java 集合, 也叫作容器,主要是由两大接口派生而来:
一个是 Collection接口,主要用于存放单一元素;
另一个是 Map 接口,主要用于存放键值对。
对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。
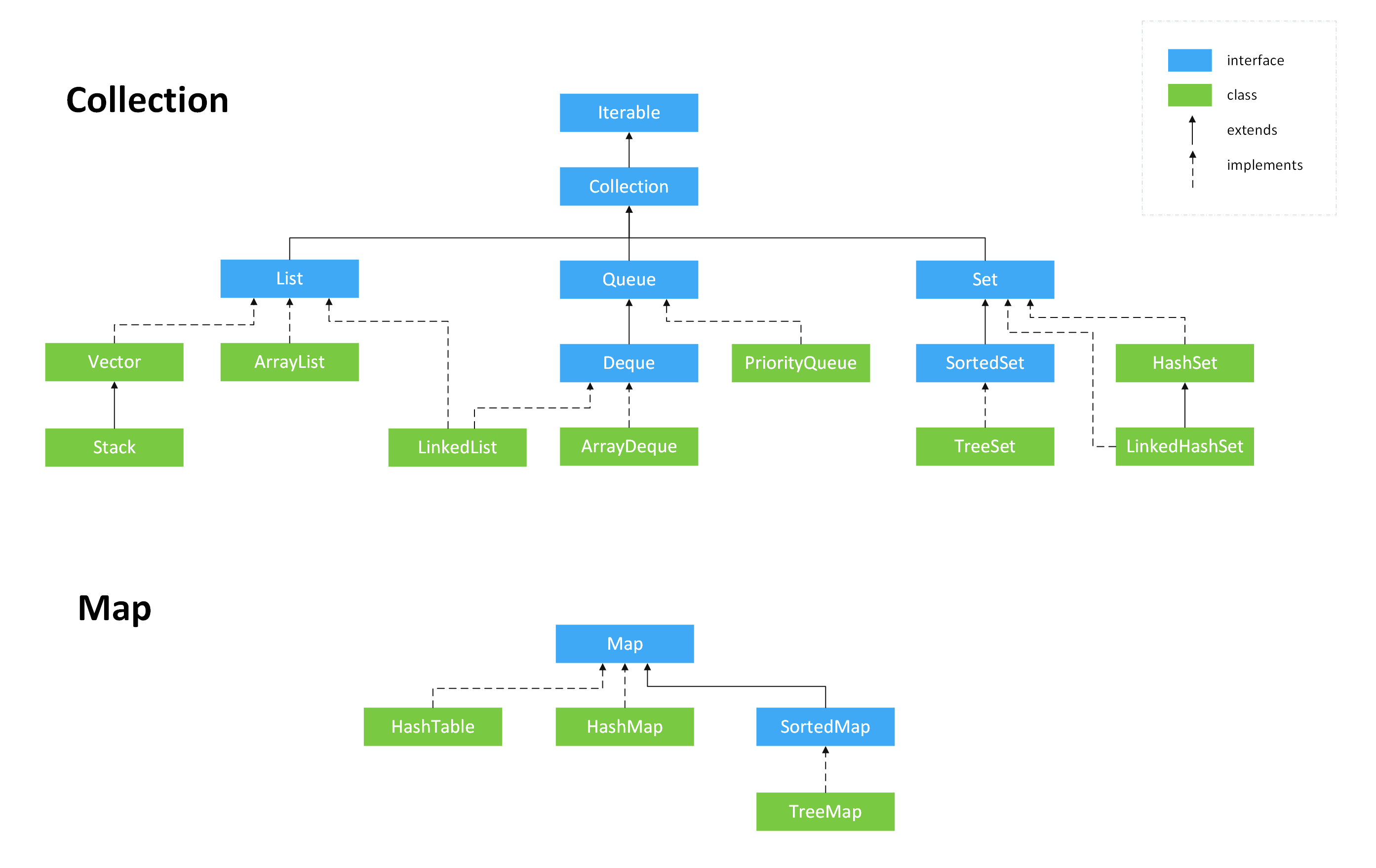
List, Set, Queue, Map 四者的区别?
- List(对付顺序的好帮手): 存储的元素是有序的、可重复的。
- Set(注重独一无二的性质): 存储的元素是无序的、不可重复的。
- Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。
- Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),”x” 代表 key,”y” 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
为什么要使用集合?
当我们需要保存一组类型相同的数据的时候,我们应该是用一个容器来保存,这个容器就是数组,但是,使用数组存储对象具有一定的弊端, 因为我们在实际开发中,存储的数据的类型是多种多样的,于是,就出现了“集合”,集合同样也是用来存储多个数据的。
数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。 但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据。
Collection 子接口之 List
Arraylist 和 Vector 的区别?
- ArrayList 是 List 的主要实现类,底层使用 Object[ ]存储,适用于频繁的查找工作,线程不安全 ;
- Vector 是 List 的古老实现类,底层使用Object[ ] 存储,线程安全的。
Arraylist 与 LinkedList 区别?
- 是否保证线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
- 底层数据结构:Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
- 插入和删除是否受元素位置的影响:
- ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
- LinkedList 采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst() 、 removeLast()),近似 O(1),如果是要在指定位置 i 插入和删除元素的话(add(int index, E element),remove(Object o)) 时间复杂度近似为 O(n) ,因为需要先移动到指定位置再插入。
- 是否支持快速随机访问:LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
- 内存空间占用: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
Collection 子接口之 Set
comparable 和 Comparator 的区别
- comparable 接口实际上是出自java.lang包 它有一个 compareTo(Object obj)方法用来排序
- comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo()方法或compare()方法,当我们需要对某一个集合实现两种排序方式,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo()方法和使用自制的Comparator方法或者以两个 Comparator 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 Collections.sort().
Comparator 定制排序
ArrayList<Integer> arrayList = new ArrayList<Integer>();arrayList.add(-1);arrayList.add(3);arrayList.add(3);arrayList.add(-5);arrayList.add(7);arrayList.add(4);arrayList.add(-9);arrayList.add(-7);System.out.println("原始数组:");System.out.println(arrayList);// void reverse(List list):反转Collections.reverse(arrayList);System.out.println("Collections.reverse(arrayList):");System.out.println(arrayList);// void sort(List list),按自然排序的升序排序Collections.sort(arrayList);System.out.println("Collections.sort(arrayList):");System.out.println(arrayList);// 定制排序的用法Collections.sort(arrayList, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2.compareTo(o1);}});System.out.println("定制排序后:");System.out.println(arrayList);-----原始数组:[-1, 3, 3, -5, 7, 4, -9, -7]Collections.reverse(arrayList):[-7, -9, 4, 7, -5, 3, 3, -1]Collections.sort(arrayList):[-9, -7, -5, -1, 3, 3, 4, 7]定制排序后:[7, 4, 3, 3, -1, -5, -7, -9]
重写 compareTo 方法实现按年龄来排序
// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了public class Person implements Comparable<Person> {private String name;private int age;public Person(String name, int age) {super();this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}/*** T重写compareTo方法实现按年龄来排序*/@Overridepublic int compareTo(Person o) {if (this.age > o.getAge()) {return 1;}if (this.age < o.getAge()) {return -1;}return 0;}}
public static void main(String[] args) {TreeMap<Person, String> pdata = new TreeMap<Person, String>();pdata.put(new Person("张三", 30), "zhangsan");pdata.put(new Person("李四", 20), "lisi");pdata.put(new Person("王五", 10), "wangwu");pdata.put(new Person("小红", 5), "xiaohong");// 得到key的值的同时得到key所对应的值Set<Person> keys = pdata.keySet();for (Person key : keys) {System.out.println(key.getAge() + "-" + key.getName());}}-----5-小红10-王五20-李四30-张三
无序性和不可重复性的含义是什么
1、什么是无序性?无序性不等于随机性 ,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。
2、什么是不可重复性?不可重复性是指添加的元素按照 equals()判断时 ,返回 false,需要同时重写 equals()方法和 HashCode()方法。
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- HashSet、LinkedHashSet 和 TreeSet 都是 Set 接口的实现类,都能保证元素唯一,并且都不是线程安全的。
- HashSet、LinkedHashSet 和 TreeSet 的主要区别在于底层数据结构不同。HashSet 的底层数据结构是哈希表(基于 HashMap 实现)。LinkedHashSet 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。
- 底层数据结构不同又导致这三者的应用场景不同。HashSet 用于不需要保证元素插入和取出顺序的场景,LinkedHashSet 用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet 用于支持对元素自定义排序规则的场景。

若有收获,就点个赞吧
0 人点赞
