一、相对路径
import osfrom pathlib import Path# 当前文件所在路径的上级路径base_dir = Path(__file__).resolve().parent.parentprint(base_dir) # D:\coding\spider\lutou# 获取当前文件所在的路径print(os.getcwd()) # D:\coding\spider\lutou\utils# 获取当前文件的绝对路径print(os.path.abspath(__file__)) # D:\coding\spider\lutou\utils\save.py
二、正则表达式去除特殊字符()
s = '*\/:?"<>|' # 这9个字符在Windows系统下是不可以出现在文件名中的str = '路透社:科普: “以身试毒”检验新冠疫苗效果可行吗'aa = re.findall(r'[^\*"/:?\\|<>]', str, re.S) # re.S 使 . 匹配包括换行在内的所有字符aa = "".join(aa)print(aa) # 路透社:科普 “以身试毒”检验新冠疫苗效果可行吗
三、 获取到单个字典的键(Key)和值(Value)
# 方法一d = {'name': '张三'}(key, value), = d.items()print(key) # nameprint(value) # 张三# 方法二d = {'name': '李四'}key = list(d)[0]value = list(d.values())[0]print(key, value) # name 李四# 方法三d = {'name': '王五'}key, = dvalue, = d.values()print(key, value) # name 王五
四、windows文件命名
正则去除不可作为文件命名的特殊字符,并写入csv文件
import reimport osimport csvfrom pathlib import Pathstr1 = 'asdfgh_*???<>'# 正则去除不可作为文件名的特殊字符title = re.findall(r'[^\*"/:?\\|<>]', str1, re.S)title = "".join(title)print(title) # asdfgh_# 当前文件所在路径base_dir = Path(__file__).resolve().parentprint(base_dir, type(base_dir)) # D:\coding\test_project <class 'pathlib.WindowsPath'>filename = os.path.join(str(base_dir), '%s.csv' % title)print(filename) # D:\coding\test_project\asdfgh_.csvcontent = [1,2,3]# 写入csvwith open(filename, 'a',) as f:fcsv = csv.writer(f)fcsv.writerow(content)
五、写入CSV文件,标题只写一遍,内容追加写入
import csvimport osfrom pathlib import Pathfrom spider_django import settingsbase_dir = Path(__file__).resolve().parentfilename = os.path.join(str(base_dir), 'task.csv')class SaveTask(object):"""存储任务"""def __init__(self, task_name, task_create_time, keyword, url, start_date, end_date, creator, status):self.task_name = task_nameself.task_create_time = task_create_timeself.keyword = keywordself.url = urlself.start_date = start_dateself.end_date = end_dateself.creator = creatorself.status = statusdef save_task(self):"""保存数据"""headers = ['task_name', 'task_create_time','keyword', 'url', 'start_date','end_date', 'creator', 'status']content = [self.task_name, self.task_create_time,self.keyword, self.url, self.start_date,self.end_date, self.creator, self.status]# 写入CSVwith open(filename, 'a', newline='') as file:f_csv = csv.writer(file)with open(filename, 'r') as f:# csv.reader(),返回csv阅读器(本质是一个迭代器,具有__next__()、__iter__()方法),可通过迭代读取csv文件内容reader = csv.reader(f)if not [row for row in reader]:f_csv.writerow(headers)f_csv.writerow(content)else:f_csv.writerow(content)
六、Markdown输入上下标
上标:<sup>符号</sup>下标:<sub></sub>
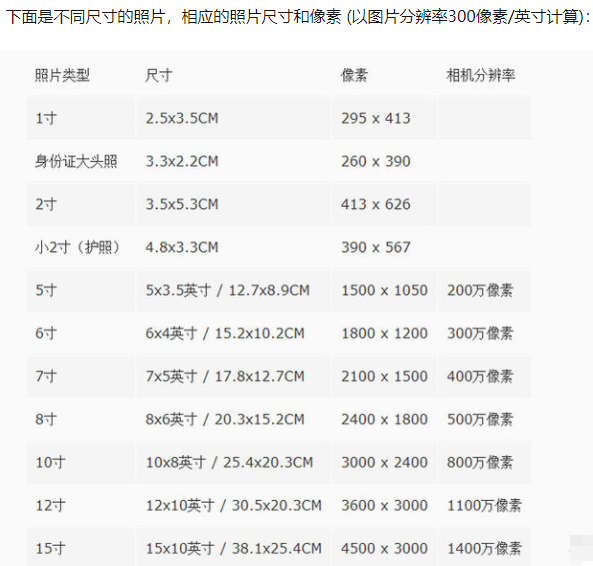
七、常用照片尺寸
八、sys.exit() 方法退出程序
官网网址:https://docs.python.org/2/library/sys.html
sys.exit(arg)
参数:
- arg:可选,默认为0。
功能: 退出 Python。这是通过引发SystemExit 异常来实现的,因此执行try 语句的 finally 子句指定的清理操作,并且可以在外部级别拦截退出尝试。 可选参数arg可以是给出退出状态的整数(默认为零)或其他类型的对象。 如果它是一个整数,零被认为是“成功终止”,任何非零值都被壳等认为是“异常终止”。大多数系统要求它在 0-127 的范围内,否则会产生未定义的结果。一些系统有为特定退出代码分配特定含义的约定,但这些通常不完善;Unix 程序通常使用 2 表示命令行语法错误,使用 1 表示所有其他类型的错误。 如果传递了另一种类型的对象,None 则等效于传递零,并且任何其他对象都被打印到stderr并导致退出代码为 1。 特别是,sys.exit(“some error message”) 是发生错误时退出程序的快捷方式。
由于exit()最终“only”引发异常,因此只有在主线程调用时才会退出进程,不会拦截异常。
示例代码:
import systry:from osgeo import ogrexcept:import ogrinshp = r'D:\Zhb\03_work\RS\abc.xxx'driver = ogr.GetDriverByName('ESRI Shapefile')datasource = driver.Open(inshp, 0)if datasource is None:print('could not open')sys.exit(1)print('done!')# 结果:"""没有 sys.exit(1),假如路径错误会打印:could not opendone!有了它:会直接退出python打印:could not open"""
九、python自省函数
dir()、help()、type()、id()、hasattr()、
getattr()、callable()、isinstance()
dir()
dir() 函数可能是 Python 自省机制中最著名的部分了。它返回传递给它的任何对象的属性名称经过排序的列表。如果不指定对象,则 dir() 返回当前作用域中的名称。
help()
用来查看很多Python自带的帮助文档信息。
type()
返回对象的类型。
id()
返回对象的“唯一序号”。对于引用对象来说,返回的是被引用对象的id()
hasattr() 和 getattr()
分别判断对象是否有某个属性及获得某个属性值。
callable()
判断对象是否可以被调用。
isinstance()
可以确认某个变量是否有某种类型。
十、python 递归
原文链接:https://blog.csdn.net/ruanxingzi123/article/details/82658669
递归函数:
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
递归函数特性:
- 必须有一个明确的结束条件;
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入)。
- 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
示例:
计算1到100之间相加之和;通过循环和递归两种方式实现。
# 循环方式def sum_cycle(n):sum = 0for i in range(1,n+1) :sum += i print(sum)# 递归方式def sum_recu(n):if n>0:return n +sum_recu(n-1)else:return 0sum_cycle(100)sum = sum_recu(100) print(sum)# 结果:50505050
十一、python字典value排序
给定一个字典,用其中的value进行排序。
可以使用:
dict.items()获取字典的元素, 返回一个 view 对象。这个视图对象包含字典的键值对,形式为列表中的元组。lambda匿名函数sorted(): sorted函数比sort函数要强大许多了,sort只能对列表进行排序,sorted可以对所有可迭代类型进行排序,并且返回新的已排序的列表。sorted(iterable, cmp=None, key=None, reverse=False) --> new sorted list
参数: 1.iterable:可迭代类型,例如字典、列表、
2.cmp:比较函数
3.key:可迭代类型中某个属性,对给定元素的每一项进行排序
4.reverse:降序或升序
dict1 = {'a': 1, 'b': 4, 'c': 2, 'f': 12, 'd': 3}a = sorted(dict1.items(), key=lambda x: x[1])print(a)b = sorted(dict1.items(), key=lambda x: x[1], reverse=True)print(b)# 结果:# [('a', 1), ('c', 2), ('d', 3), ('b', 4), ('f', 12)]# [('f', 12), ('b', 4), ('d', 3), ('c', 2), ('a', 1)]

若有收获,就点个赞吧
0 人点赞
