
| Swarm的存储原理有几点:
一、块的分布式不可变存储;
二、内容寻址块;
三、单一拥有者块;
四、块加密;
五、复制冗余。
本文将重点讲解一、二两点。
一、块的分布式不可变存储
在本节中,我们将讨论如何使用 Kademlia 覆盖路由的网络是一个合适的基础上,实现无服务器存储解决方案,使用分布式哈希表( DHT )。然后,我们介绍了 DISC7 模型, Swarm 的狭义解释的DHT用于存储。该模型对块提出了一些要求,并要求上传协议。<br />按照 Swarm 的惯例,我们提供了一些这个缩写的解析,总结了最重要的特性:<br />• 用于存储和通信的分散式基础设施;<br />• 块的分布式不可变存储;<br />• 签名或内容地址的数据完整性;<br />• 通过智能合约激励驱动。虽然节点不需要知道网络中的节点数量。事实上,在节点停止接收新的对等地址一段时间后,该节点可以有效地估计网络的规模:网络的深度是 log2 (n + 1) + d 其中 n 是最近邻域的远程对等节点的数量 d 是该邻域的深度。然后,网络中的节点总数可以简单地通过取 2 的指数来估计。<br /> DISC 是块的分布式不可变存储。在早期的工作中,我们将这个组件称为“分布式原像存档”(DPA),但是,这个短语变得具有误导性,因为我们现在也允许不是其地址原像的块。
从DHT到光盘
Swarm 的 DISC 与更熟悉的分布式哈希表有许多相似之处。最重要的区别是,Swarm 不保留要找到文件的位置的列表,而是直接将文件本身与最近的节点一起存储。接下来,我们将回顾 DHT,并更详细地探讨与 DISC 的异同。<br /> 分布式哈希表使用覆盖网络来实现分布在节点上的键值容器(见图 1)。基本思想是将键空间映射到覆盖地址空间,容器中键的值将通过地址位于键附近的节点找到。在最简单的情况下,让我们说这是与存储值的键最接近的单个节点。在具有 Kademlia 连接的网络中,任何节点都可以路由到地址最接近键的节点,因此查找(即查找属于键的值)被简化为路由请求。<br />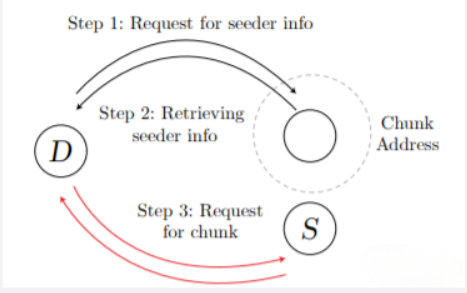<br />图1:用于存储的分布式哈希表(DHT)
节点D(下载器)使用Kademlia,在步骤1(请求播种机信息)中路由到查询块地址附近的节点,以便在步骤2(检索播种机信息块地址)中检索播种机信息。播种机信息用于直接联系节点S(播种机),请求块并在步骤3(请求块)和步骤4(交付)中传递。
用于分布式存储的DHT通常将内容标识符(作为键/广告裙子)与可为该内容服务的种子(作为值)列表相关联(IPFS 2014、Crosby和Wallach,20o7)。但是,可以直接使用相同的结构:在Swing中,存储在离地址最近的群集节点上的不是关于内容位置的信息,而是内容本身的信息(参见图2)。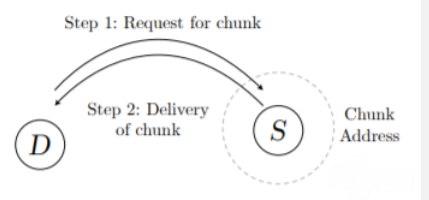
图 2 :Swarm DISC :块的分布式不可变存储。
D 使用转发 Kade mlia 路由从块地址附近的存储器节点 S 请求块。在步骤 2 中,块使用向后的转发步骤沿着相同的路线传递。
约束
DISC 存储模型对哪个节点存储什么内容有自己的看法,这意味着以下限制:
1.固定大小的块 - 节点之间需要内容的负载平衡,并且通过将内容分成大小相等的单元(称为块)来实现。
2.同步 - 必须有一个过程,使块到达它们所在的位置,无论哪个节点上传它们,都将被存储。
3.似是而非的否认 - 由于节点对其存储的内容没有发言权,因此应采取措施作为法律保护的基础,使节点运营商合理地否认知道(甚至能够知道)有关块内容的任何信息。
4.垃圾收集 - 由于节点承诺存储任何靠近它们的内容,因此需要有一个策略来选择在存在存储空间约束的情况下保留哪些块和丢弃哪些块。
块
块是 Swarm 网络层中使用的基本存储单元。它们是地址与内容的关联。由于 Swarm 中的检索假设块存储在其地址附近的节点,因此块的地址也应均匀分布在地址空间中,并且其内容有限且大小大致均匀,以实现公平和均等的负载平衡。<br /> 检索块时,下载器必须能够验证给定地址的内容的正确性。这种完整性转化为保证与地址关联的内容的唯一性。为了防止无意义的网络流量,第三方转发节点应该能够验证块的完整性,仅使用节点可用的本地信息。<br />寻址的确定性和无冲突性质意味着块作为键值关联是唯一的:如果存在具有地址的块,则没有其他有效块可以具有相同的地址;这个假设很重要,因为它使块存储不可变,即没有对块的替换/更新操作。不变性在中继块的上下文中是有益的,因为节点可以通过检查它们的地址来协商有关块拥有的信息。这在流协议中起着重要作用,并证明 DISC 解析作为块的分布式不可变存储是合理的。<br />总之,块寻址需要满足以下要求:<br />• 确定性 - 启用本地验证。<br />• 无碰撞 - 提供完整性保证。<br />• 统一分布式 - 提供负载均衡。
二、内容寻址块
内容寻址块不被认为是一个有意义的存储单元,即它们可以只是由拆分更大的数据 blob 产生的任意数据 blob,文件上传时将文件分解成块的方法然后在下载时从块重新组装在 4.1 中有详细说明。内容寻址的 Swarm 块的数据大小限制为 4 KB。使用这种小块大小的理想结果之一是,即使对于相对较小的文件,也可以进行并发检索,从而减少下载延迟。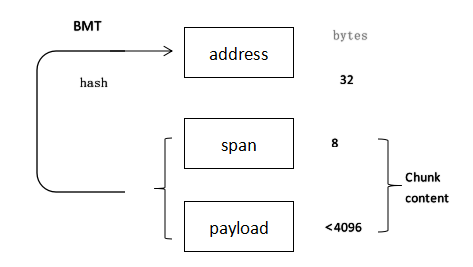
图3:: 内容寻址块。
一个最多 4KB 的有效载荷和一个 64 位小端编码的跨度预先构成块内容。负载的 BMT 哈希与 span 连接,然后产生内容地址。
二进制 Merkle 树散列
**
Swarm 中的规范内容寻址块称为二元 Merkle 树块( BMT 块)。使用二进制 Merkle 树哈希算法( BMT 哈希)计算 BMT 块的地址。BMT 中使用的基本散列是 Keccak256 ,其均匀性、不可逆性和抗冲突性等特性都继承到 BMT 散列算法中。作为均匀性的结果,一组随机的分块内容将产生均匀分布在地址空间中的地址,即施加平衡节点之间的存储需求。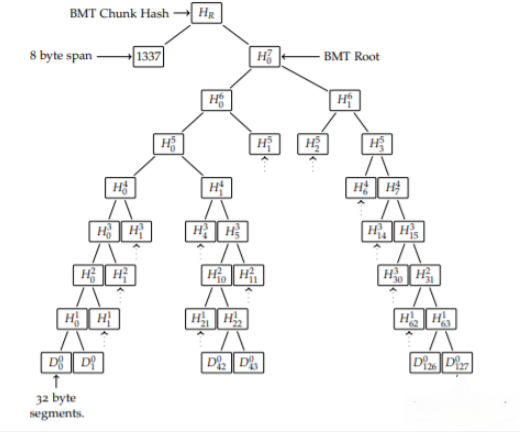
图4:Swarm 中的 BMT(Binary Merkle Tree)块哈希
1337 字节的块数据被分割成 32 字节的段。零填充用于填充最多 4 KB 的其余部分。使用 Keccak256 将成对的段散列在一起以构建二叉树。在第 8 级,二进制 Merkle 根在前面加上 8 字节的跨度并进行散列以产生 BMT 块散列。
BMT 块地址是构建在基础数据的 32 字节段上的二元 Merkle 树( BMT )的 8 字节跨度的哈希和根哈希(见图 4 )。如果块内容小于4k,则计算散列就好像块被填充了所有0到40g6字节。
这种结构允许使用 32 字节的分辨率进行紧凑的包含证明。包含性证明是一个字符串是另一字符串的子串的证明,例如,一个串包含在一个块中。包含证明是在特定索引的数据段上定义的,见图 1o 。当存储器节点提供它们拥有块的证据时,这种 Merkle 证明也被用作保管的证明。与Swarm文件散列一起,它允许文件的对数包含证明,即一个字符串被发现是一个文件的一部分。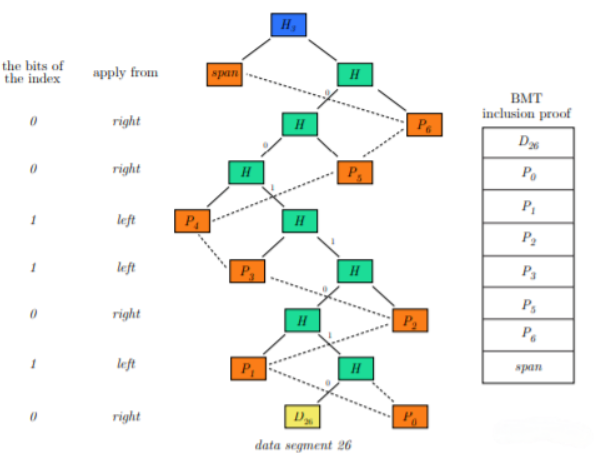
图5:块的紧凑段包含证明
块的紧凑段包含证明。假设我们需要一个块(黄色)的 segment26 的证明。BMT 的橙色散列是从数据段到根的路径上的姐妹节点,构成了证明的一部分。当这些与根哈希和段索引一起提供时,可以验证证明。需要应用证明项 i 的一侧取决于索引的二进制表示的第 i 位(从最低有效位开始)。最后,将跨度添加到前面,并且生成的散列应与块根散列匹配。
关于Swarm存储原理的“单一拥有者块”、“块加密”、“复制冗余”将在后面文章更新。

若有收获,就点个赞吧
0 人点赞
