简介
本文旨在说明通过Docker快速搭建Hadoop,Hive集群环境
所使用到的各个版本如下:
- Docker: 20.10.6
- Ubuntu image: 18.04
- Hadoop: 3.3.1
- Hive: 3.1.2
- Mysql: 5.7
- Scala:2.12.3
在搭建环境之前请保证服务器/电脑主机上安装好Docker并正常运行
获取Ubuntu镜像
拉取Ubuntu镜像并启动容器
Ubuntu的Docker镜像获取十分便利,个人建议,尽量不要使用最新版本(当前最新Ubuntu版本为20.10),一些套件版本较新,相反会造成使用过程中一些麻烦。
考虑到我使用的是mysql5.7,因此镜像版本选择18.04(从19.04开始Ubuntu默认mysql版本为8.x,当然你也可以选择19.04,20.04这样,如果选择使用mysql8的话,在配置hive时注意ConnectionDriver即可)
$ docker pull ubuntu:18.04# 创建名为hadoop虚拟网络,为hadoop集群使用$ docker network create --driver=bridge hadoop
拉取完镜像后进入镜像查看
$ docker run -it ubuntu:18.04 /bin/bash
进入镜像后退出,然后查看镜像的container id并启动container
$ docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES3725415ba07e ubuntu:18.04 "/bin/bash" 21 hours ago Exited (255) 5 hours ago youthful_boyd$ docker start 3725415ba07e3725415ba07e
所有组件都在container中进行配置,注意不要直接在image中,根据官网的定义,镜像没有状态也不会改变,因此我们的操作在实例中进行,之后可以制作我们自己的镜像。详细的可以了解一下Docker中image和container的区别
进入容器
$ docker exec -it 3725415ba07e /bin/bash
此时container是一个简洁的Ubuntu系统,我们可以选择下载一些我们需要的基本工具(如果需要更换ubuntu源的话可以自行更换)
# 若需要更换源$ cp /etc/apt/sources.list /etc/apt/sources_bak.list$ echo "deb http://mirrors.aliyun.com/ubuntu/ xenial maindeb-src http://mirrors.aliyun.com/ubuntu/ xenial maindeb http://mirrors.aliyun.com/ubuntu/ xenial-updates maindeb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates maindeb http://mirrors.aliyun.com/ubuntu/ xenial universedeb-src http://mirrors.aliyun.com/ubuntu/ xenial universedeb http://mirrors.aliyun.com/ubuntu/ xenial-updates universedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universedeb http://mirrors.aliyun.com/ubuntu/ xenial-security maindeb-src http://mirrors.aliyun.com/ubuntu/ xenial-security maindeb http://mirrors.aliyun.com/ubuntu/ xenial-security universedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe" > /etc/apt/sources.list$ apt update$ apt install wget net-tools emacs # 或vim
安装SSH并配置免密登录
$ apt install openssh-server openssh-client$ cd# 配置免密登录$ ssh-keygen -t rsa -P "" # 不用选择,一直enter$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys# 启动ssh服务$ service ssh start# 测试$ ssh localhost# 显示Welcome to Ubuntu则成功
最后需要修改.bashrc文件,以便在启动shell时自动启动ssh服务
$ emacs ~/.bashrc# 在最后一行后加入service ssh start
安装Java和Scala
由于我后期会使用spark,因此需要安装scala,若不需要则只用安装Java即可
$ apt install openjdk-8-jdk# 由于apt默认scala版本是2.11.x,使用以下方式安装2.12$ apt-get remove scala-library scala$ wget https://downloads.lightbend.com/scala/2.12.3/scala-2.12.3.deb$ dpkg -i scala-2.12.3.deb$ apt-get update$ apt-get install scala
当我在macOS的Docker环境下使用dpkg进行安装时会报错copy scala.xx.jar错误,此时可以使用apt —fix-broken install,再进行安装,正常情况下不会报错
# 查看是否安装成功$ java -version$ javac -version$ scala -version# 显示版本号则安装成功# 可使用以下命令查看java路径# 方式一$ echo $JAVA_HOME# 方式二$ update-alternatives --config java# 方式三$ ls -l /usr/bin/java
安装并配置Hadoop
下载Hadoop
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-3.3.1.tar.gz# 解压并移动至/usr/local目录,也可以选择其他目录$ tar -xvzf hadoop-3.3.1.tar.gz -C /usr/local/
配置环境变量
首先修改profile文件,配置Hadoop相关环境变量
$ emacs /etc/profile# 在最后一行后加入# javaexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH# hadoopexport HADOOP_HOME=/usr/local/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport HADOOP_CONF_DIR=$HADOOP_HOMEexport HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexecexport JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATHexport HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoopexport HDFS_DATANODE_USER=rootexport HDFS_DATANODE_SECURE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=rootexport HDFS_NAMENODE_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=root# 重新加载profile文件以便修改内容生效$ source /etc/profile
配置Hadoop
${HADOOP_HOME}/etc/hadoop/hadoop-env.sh最后一行后加入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64export HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=rootexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
${HADOOP_HOME}/etc/hadoop/core_site.xml修改为
<configuration><property><name>fs.default.name</name><value>hdfs://hadoop01:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/tmp</value></property></configuration>
${HADOOP_HOME}/etc/hadoop/hdfs-site.xml修改为
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/hadoop/hdfs/data</value>
</property>
</configuration>
${HADOOP_HOME}/etc/hadoop/mapred-site.xml修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
${HADOOP_HOME}/etc/hadoop/yarn-site.xml修改为
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
${HADOOP_HOME}/etc/hadoop/workers修改为
# 需要几个节点配几个
hadoop01
hadoop02
hadoop03
hadoop04
制作为镜像并启动集群
首先将我们上面配置好的容器制作成我们自己的镜像
# 退出容器
$ exit
$ docker commit -a "hadoop" -m "init image" 3725415ba07e datawarehouse
# 查看images
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
datawarehouse latest 05b9de12b70d 23 hours ago 2.92GB
ubuntu 18.04 7d0d8fa37224 3 weeks ago 63.1MB
打开4个终端,以hadoop01为master,其他作为worker(slaves)
# 由于hadoop01为master node,因此需要暴露端口
$ docker run -it --network hadoop -h "hadoop01" --name "hadoop01" -p 9870:9870 -p 8088:8088 datawarehouse /bin/bash
# 其余节点不需要暴露端口
$ docker run -it --network hadoop -h "hadoop02" --name "hadoop02" datawarehouse /bin/bash
$ docker run -it --network hadoop -h "hadoop03" --name "hadoop03" datawarehouse /bin/bash
$ docker run -it --network hadoop -h "hadoop04" --name "hadoop04" datawarehouse /bin/bash
# 分别显示进入终端后表示成功
进入master node启动集群
# 切换至hadoop01的终端
# 格式化namenode
$ cd /usr/local/hadoop
$ bin/hadoop namenode -format
# 启动所有job
$ sbin/start-all.sh
Starting datanodes
...
Starting nodemanagers
查看服务状态
# 分别在hadoop01-04终端查看
$ jps
打开浏览器https://localhost:9870也可查看对应datanodes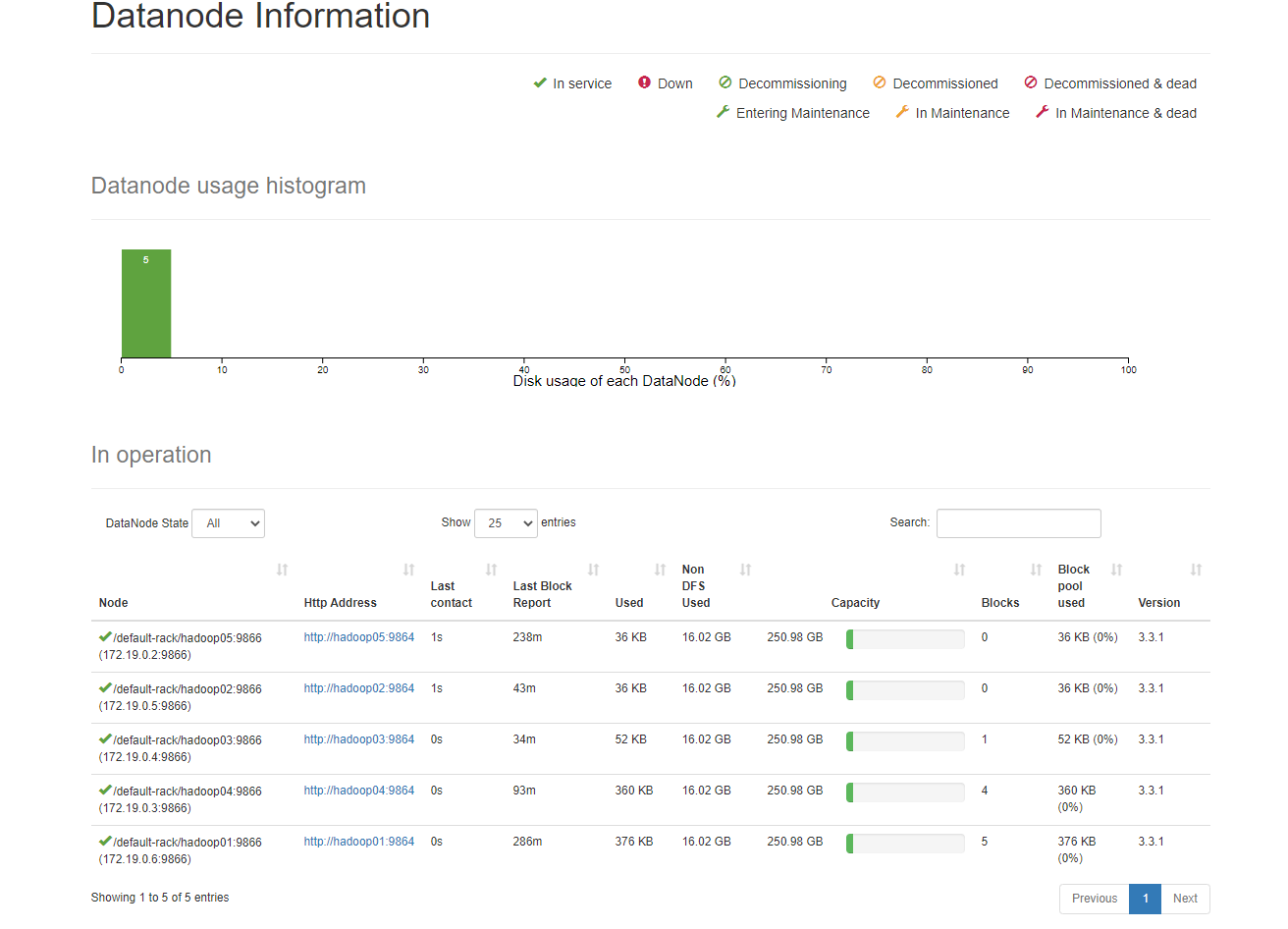
运行WordCount
$ cd /usr/local/hadoop
# 将LICENSE.txt作为需要统计的例子
$ cat LICENSE.txt > file1.txt
# 创建hdfs文件夹
$ bin/hadoop fs -mkdir /input
# 将文本上传到hdfs
$ bin/hadoop fs -put file1.txt /input
# 运行wordcount程序
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
# 查看输出文件
$ bin/hadoop fs -ls /output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2019-03-19 11:18 /output/_SUCCESS
-rw-r--r-- 2 root supergroup 35324 2019-03-19 11:18 /output/part-r-00000
# 查看输出结果
$ bin/hadoop fs -cat /output/part-r-00000
安装并配置Hive
安装并配置Mysql
Ubuntu18.04默认mysql-server为5.7版本,我们直接通过apt下载即可
$ apt install mysql-server-5.7
# 下载完成后启动mysql
$ service mysql start
默认没有密码,因此我们可以直接登录mysql,同时配置hive连接用户,生产环境中建议单独创建一个用户来进行连接,这里为了方便我直接使用root用户进行连接
通常情况下不建议数据库放到镜像中,生产环境中应单独安装在服务器上
修改root用户连接host
# 初始化没有密码,可以使用mysql直接登录
$ mysql
# 修改root密码
> use mysql;
> alter user 'root'@'localhost' identified by '123456';
> flush privileges;
# 修改root用户host
> update user set host = '%' where user='root';
> flush privileges;
创建hive库,供hive初始化schema使用
> create database hive;
同时修改mysqld.cnf,使mysql支持远程连接,通过apt安装mysql,通常路径在/etc/mysql下
$ emacs /etc/mysql/mysql.conf.d/mysqld.cnf
# 找到bind 127.0.0.1这一句,在前面加上#号注释掉
# 重启mysql服务
$ service mysql restart
下载Hive
下载hive
$ cd /home
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
解压文件
tar -xvzf apache-hive-3.1.2-bin.tar.gz -C /usr/local
mv apache-hive-3.1.2-bin hive
配置环境变量
$ emacs /etc/profile
# 在最后一行后加入
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
配置Hive
$ cd /usr/local/hive
$ cp conf/hive-default.xml.template conf/hive-site.xml
$ emacs conf/hive-site.xml
将所有system:java.io.tmpdir替换为/home/hive/tmp
将所有system:user.name替换为root
若使用vim,可在命令模式下输入 :%s#${system:java.io.tmpdir}#/data/apache-hive-3.1.2/temp#g 和 :%s#${system:user.name}#root#g进行替换
找到以下数据库连接相关property并修改如下:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true&useSSL=false&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value> <!-- 若使用mysql8.x,DriverName修改为com.mysql.cj.jdbc.Driver -->
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value> #修改为你自己的mysql密码
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
在3215行(引用的文章中是3210行),有一个特殊字符,需要删除掉,否则会报错,如果不确定,待报错后看输出究竟是多少行
Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3215,96,"file:/usr/local/hive/conf/hive-site.xml"]
修改log路径
$ cp conf/hive-log4j2.properties.template conf/hive-log4j2.properties
$ emacs conf/hive-log4j2.properties
# 找到property.hive.log.dir修改为
property.hive.log.dir = /home/hive/tmp/root
修改hive启动环境变量
$ cp conf/hive-env.sh.template conf/hive-env.sh
$ emacs conf/hive-env.sh
# 在最后一行后添加
export HADOOP_HOME=/usr/local/hadoop #hadoop 安装目录
export HIVE_CONF_DIR=/usr/local/hive/conf #hive 配置文件目录
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib #hive 依赖jar包目录
下载mysql驱动
驱动一定要放在${HIVE_HOME}/lib下
$ cd /usr/local/hive/lib
$ wget http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jar
初始化Hive并测试
初始化Hive
$ cd /usr/local/hive
$ bin/schematool -dbType mysql -initSchema
...
Initialization script completed
schemaTool completed
# 表示初始化完成
启动hive并创建测试库
$ bin/hive
> create database test;
在本机浏览器中打开http://localhost:9870,hdfs管理界面里对应的路径查看是否创建成功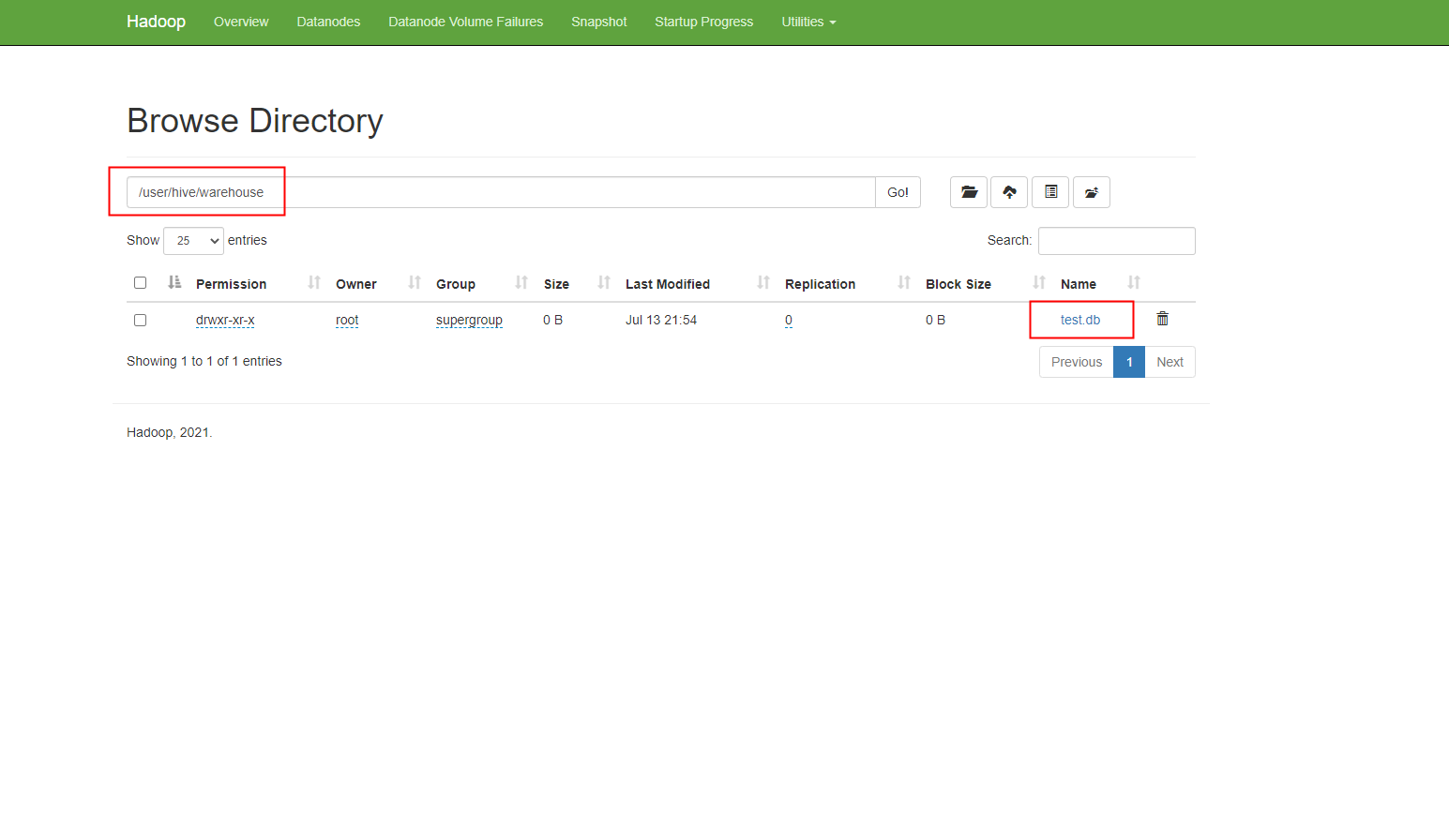
路径和名称显示正确,说明配置成功。
结语
至此基于Docker搭建的Hadoop, Hive集群开发环境完成。基本是结合两篇引用的内容,加上了在配置过程中的一些错误修复。之后内容会在此环境下扩展,目的是结合我的实际业务,尝试搭建针对自动驾驶领域的数据湖项目。
References:

若有收获,就点个赞吧
0 人点赞
