C++源文件从文本到可执行文件的过程
预处理阶段
对源代码文件中文件包含关系(头文件)、预编译语句(宏定义)进行分析和替换,生成预编译文件。
编译阶段
将经过预处理后的预编译文件转换成特定汇编代码,生成汇编文件。
汇编阶段
将编译阶段生成的汇编文件转化成机器码,生成可重定位目标文件。
链接阶段
include头文件的顺序以及双引号“”和尖括号<>的区别
Include头文件的顺序:对于include的头文件来说,如果在文件a.h中声明一个在文件b. h中定义的变量,而不引用b.h。 那么要在a.c文件中引用b.h文件,并且要先引用b.h,后引用a.h,否则汇报变量类型未声明错误。
双引号和尖括号的区别:编译器预处理阶段查找头文件的路径不一样。
对于使用双引号包含的头文件,查找头文件路径的顺序为:
- 当前头文件目录。
- 编译器设置的头文件路径(编译器可使用-I显式指定搜索路径)。
- 系统变量CPLUS INCLUDE PATH/C INCLUDE PATH指定的头文件路径。
对于使用尖括号包含的头文件,查找头文件的路径顺序为:
- 编译器设置的头文件路径(编译器可使用-I显式指定搜索路径)。
系统变量CPLUS INCLUDE PATH/C INCLUDE PATH 指定的头文件路径。
malloc的原理,brk系统调用和mmap系统调用的作用
Malloc函数用于动态分配内存。为了减少内存碎片和系统调用的开销,malloc 其采用内存池的方式,先申请大块内存作为堆区,然后将堆区分为多个内存块,以块作为内存管理的基本单位。当用户申请内存时,直接从堆区分配-块合适的空闲块。Malloc 采用隐式链表结构将堆区分成连续的、大小不一的块,包含已分配块和未分配块;同时malloc采用显示链表结构来管理所有的空闲块,即使用一个双向链表将空闲块连接起来,每一个空闲块记录了一个连续的、未分配的地址。
当进行内存分配时,Malloc 会通过隐式链表遍历所有的空闲块,选择满足要求的块进行分配;当进行内存合并时,malloc 采用边界标记法,根据每个块的前后块是否已经分配来决定是否进行块合并。
Malloc在申请内存时,-般会通过brk或者mmap系统调用进行申请。其中当申请内存小于128K时,会使用系统函数brk在堆区中分配;而当申请内存大于128K时,会使用系统函数mmap在映射区分配。C++的内存管理
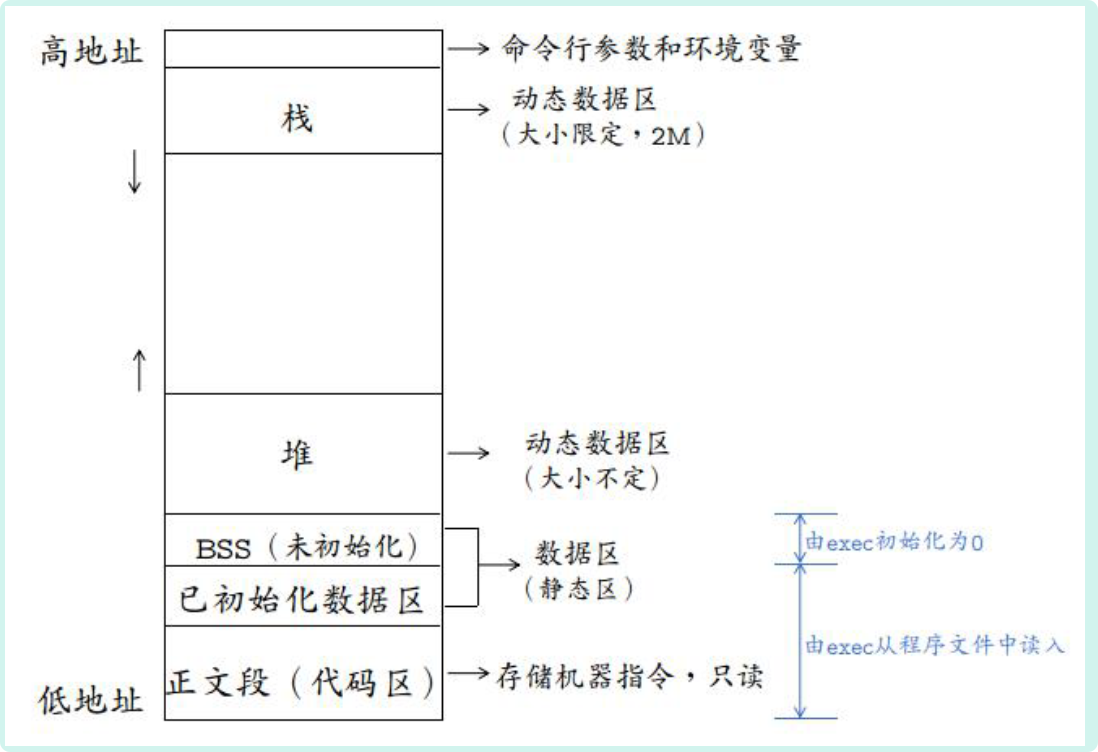
在C++中,虚拟内存分为代码段、数据段、BSS 段、堆区、文件映射区以及栈区六部分。代码段
包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机器代码。
数据段
bss段
存储未初始化的全局变量和静态变量(局部+全局),以及所有被初始化为0的全局变量和静态变量。
堆区
调用new/malloc函数时在堆区动态分配内存,同时需要调用delete/free来手动释放申请的内存。
映射区
栈
判断内存泄漏
内存泄漏通常是由于调用了malloc/new等内存申请的操作,但是缺少了对应的free/delete。为了判断内存是否泄露,我们一方面可以使用linux环境下的内存泄漏检查工具Valgrind、Mtrace,另一方面我们在写代码时可以添加内存申请和释放的统计功能,统计当前申请和释放的内存是否一致,以此来判断内存是否泄露。
内存访问段错误
段错误通常发生在访问非法内存地址的时候,具体来说分为以下几种情况:
使用野指针。
-
new和malloc的区别
new分配内存按照数据类型进行分配,malloc 分配内存按照指定的大小分配;
- new 返回的是指定对象的指针,而malloc返回的是void*,因此malloc的返回值一般都需要进行类型转化。
- new 不仅分配一段内存,而且会调用构造函数,malloc 不会。
- new分配的内存要用delete销毁,malloc要用free来销毁; delete 销毁的时候会调用对象的析构函数,而free则不会。
- new是一个操作符可以重载,malloc是一个库函数。
- malloc分配的内存不够的时候,可以用realloc扩容,new 没用这样操作。
- new如果分配失败了会抛出bad_ malloc的异常,而malloc失败了会返回NULL。
申请数组时:new[]一次分配所有内存,多次调用构造函数,搭配使用delete[],delete[]多次调用析构函数,销毁数组中的每个对象。而malloc则只能sizeof(int) * n。
reactor模型组成
reactor模型要求主线程只负责监听文件描述上是否有事件发生,有的话就立即将该事件通,知工作线程,除此之外,主线程不做任何其他实质性的工作,读写数据、接受新的连接以及处理客户请求均在工作线程中完成。其模型组成如下:
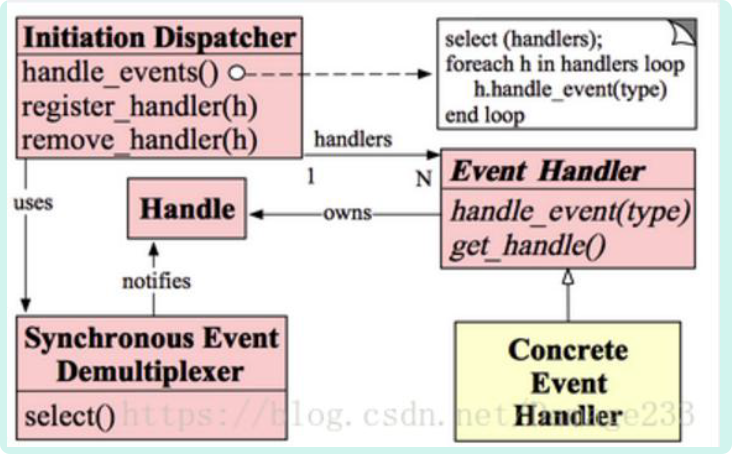
Handle
即操作系统中的句柄,是对资源在操作系统层面上的一种抽象,它可以是打开的文件、一个连接(Socket)、Timer 等。由于Reactor模式-般 使用在网络编程中, 因而这里一般指Socket Handle,即一个网络连接。
Synchronous Event Demultiplexer (同步事件复用器)
阻塞等待一-系列的Handle中的事件到来,如果阻塞等待返回,即表示在返回的Handle中可以不阻塞的执行返回的事件类型。这个模块一般使用操作系统的select来实现。
Initiation Dispatcher
用于管理Event Handler, 即EventHandler的容器,用以注册、移除EventHandler等;另外,它还作为Reactor模式的入口调用Synchronous Event Demultiplexer的select方法以阻塞等待事件返回,当阻塞等待返回时,根据事件发生的Handle
将其分发给对应的Event Handler 处理,即回调EventHandler中的handle_ event() 方法。Event Handler
定义事件处理方法: handle_ event(), 以供Initiat ionDispatcher回调使用。
Concrete Event Handler
单线程的方式处理高并发
在单线程模型中,可以采用I/0复用来提高单线程处理多个请求的能力,然后再采用事件驱动模型,基于异步回调来处理事件。
select, epoll的区别
I0多路复用
I0复用模型在阻塞I0模型上多了一个select函数,select函数有一个参数是文件描述符集合,意思就是对这些的文件描述符进行循环监听,当某个文件描述符就绪的时候,就对这个文件描述符进行处理。这种I0模型是属于阻塞的I0。但是由于它可以对多个文件描述符进行阻塞监听,所以它的效率比阻塞I0模型高效。
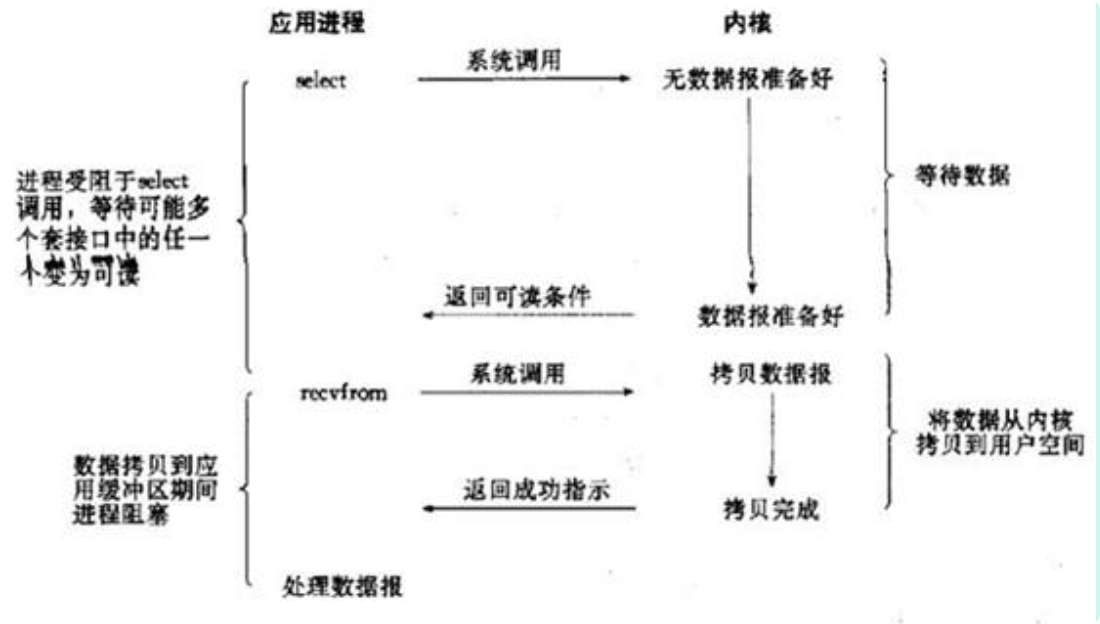
I0多路复用就是我们说的select, poll, epoll。 select/epoll的好处就在于单个process就可以同时处理多个网络连接的I0。它的基本原理就是select, poll, epoll。这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个 socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,I/O多路复用的特点是通过种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意个进入读就绪状态,select()函数就可以返回。
I/0多路复用和阻塞I/0其实并没有太大的不同,事实上,还更差一些。 因为这里需要使用两个system call (select 和recvfrom) ,而blocking I0只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
所以,如果处理的连接数不是很高的话,使用select/epoll的webserver 不一定比使用multi-threading + blocking I0 的web server 性能更好,可能延迟还更大。select/epoll 的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
在I0 multiplexing Model中,实际中,对于每一个 socket,-般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket I0给block。select
select:是最初解决I0阻塞问题的方法。用结构体fd_set来告诉内核监听多个文件描述符,该结构体被称为描述符集。由数组来维持哪些描述符被置位了。对结构体的操作封装在三个宏定义中。通过轮寻来查找是否有描述符要被处理。
存在的问题:- 内置数组的形式使得 select的最大文件数受限与 FD_SIZE。
- 每次调用select前都要重新初始化描述符集,将fd从用户态拷贝到内核态,每次调用select后,都需要将fd从内核态拷贝到用户态。
- 轮寻排查当文件描述符个数很多时,效率很低。
poll
poll:通过一个可变长度的数组解决了select 文件描述符受限的问题。数组中元素是结构体,该结构体保存描述符的信息,每增加一个文件描述符就向数组中加入一个结构体,结构体只需要拷贝一次到内核态。poll解决了select重复初始化的问题。轮寻排查的问题未解决。epoll
epoll:轮寻排查所有文件描述符的效率不高,使服务器并发能力受限。因此,epoll 采用只返回状态发生变化的文件描述符,便解决了轮寻的瓶颈。
epoll对文件描述符的操作有两种模式: LT (level trigger) 和ET (edge trigger) 。LT模式是默认模式。LT模式
LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket. 在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行I0操作。如果你不作任何操作,内核还是会继续通知你的。ET模式
ET(edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK错误)。但是请注意,如果一直不对这个fd作I0操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once)
ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。LT模式与ET模式的区别
LT模式:当epollwait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll__wait时,会再次响应应用程序并通知此事件。
ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用 epoll wait 时,不会再次响应应用程序并通知此事件。epoll原理
调用顺序:int epoll_ create(int size);int epoll_ ctl (int epfd, int op, int fd, struct epoll_ event *event) ;int epoll_ wait(int epfd, struct epoll_ event *events, int maxevents, int timeout) ;
首先创建一个epoll对象,然后使用epoll ctl 对这个对象进行操作,把需要监控的描述添加进去,这些描述如将会以epoll event 结构体的形式组成一颗红黑树 ,接着阻塞在epoll_ wait,进入大循环,当某个fd上有事件发生时,内核将会把其对应的结构体放入到一个链表中,返回有事件发生的链表。

若有收获,就点个赞吧
0 人点赞
