一、概要
源代码作者归属判断是在软件取证、bug修复和软件质量分析等应用程序中经常遇到的一个重要问题。而源代码作者归属判断方法容易被攻击者利用对抗样本和修改编码风格破坏其准确性。为了对代码作者身份归属判断问题提供可靠的解决方案,我们提出了一个名为鲁棒编码风格模式生成(RoPGen)的创新框架。RoPGen提出了在对抗性训练阶段将数据增强和梯度增强相结合,增加了训练示例的多样性,同时对深度神经网络的梯度产生有意义的扰动。并学习编码风格的多样化表示,使攻击者很难变换或模仿作者独特的编码风格模式。RoPGen框架能显著提高基于深度学习的代码作者归属判断模型的鲁棒性,平均分别降低了靶向攻击和非靶向攻击的成功率22.8%和41.0%。
该成果“RoPGen:Towards Robust Code Authorship Attribution via Automatic Coding Style Transformation”发表在ICSE会议(International Conference on Software Engineering),ICSE是软件工程领域最高级别的学术会议。

二、背景与动机
软件取证分析旨在确定是否存在与某些给定的软件代码相关的软件知识产权侵权或盗窃行为。为此目的的一个有用的技术是源代码作者归属判断,它旨在识别给定软件程序的作者。这种技术已被用于许多应用程序,如代码剽窃检测、刑事起诉(例如,识别一段恶意代码的作者),公司诉讼(例如,确定一段代码是否由前员工违反任何竞业禁止合同条款),bug修复和软件质量分析。源代码作者归属判断有多种方法,包括统计分析、相似度度量和机器学习。
最近的研究表明,当前的源代码作者识别方法可能受到两类攻击:利用对抗样本和利用编码风格模仿/隐藏。例如,利用对抗样本可能会导致Google CodeJam比赛数据集中超过99%的软件程序的错误归属判断;而利用隐藏编码风格的方式可能会导致GitHub数据集中所有软件程序的错误归属判断。这就需要研究增强代码作者归属判断方法对攻击的鲁棒性。
传统代码作者归属判断方法大部分需要领域专家费时费力参与,并且只能针对防御领域专家定义的特征的已知攻击,同时传统方法可扩展性差,只用了单一的对抗性训练方法,不能有效地减轻上述已知和新的攻击。针对传统方法的不足方面,本文启动了增强基于深度学习的代码作者归属判断方法的稳健性鲁棒性的研究。引入了利用自动编码风格模仿和隐藏的两种新攻击,这些攻击可以同时攻击基于深度学习的代码作者归属判断和其他方法。新的攻击是黑盒攻击会模仿目标作者的编码风格或隐藏真实作者的编码风格。另一方面本文提出了一个创新的框架,称为鲁棒代码特征生成(RoPGen)。其关键思想是结合数据增强和梯度增强来学习稳健的编码风格模式,这使得攻击者难以操作或模仿。
三、两种新的攻击方式
本文研究了两种新的针对代码作者归属判断攻击,一种是编码风格模仿攻击,另一种是编码风格隐藏攻击。
编码风格模仿攻击是将作者A写的代码,经过表1编码风格变换后,被代码作者归属判断模型错误地归类为B写的代码;而编码风格隐藏攻击是,将作者A写的代码,经过编码风格变换后,代码作者归属判断模型将变换后的程序错误归属为非A的其他作者。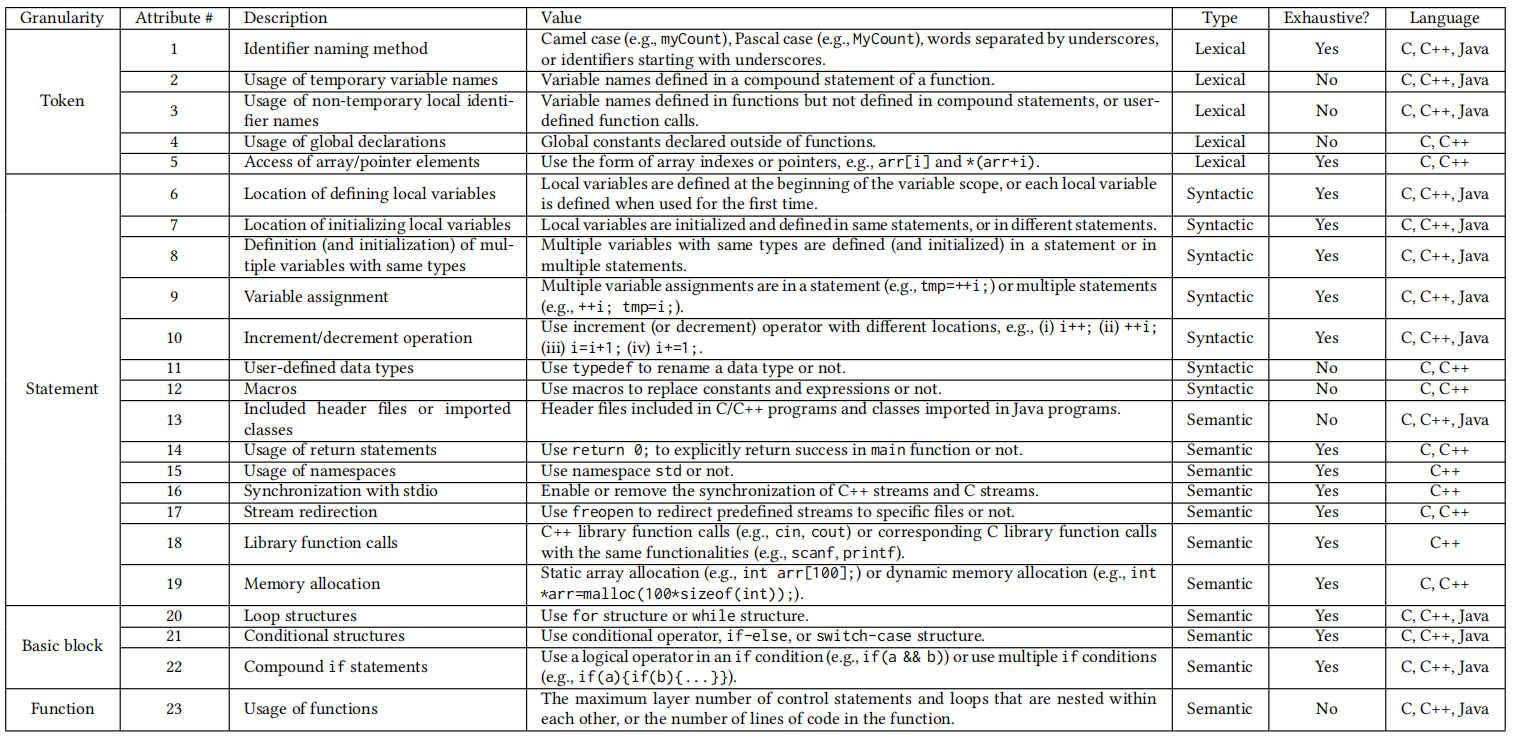
表1:23种C、C++和Java编码样式属性
编码风格模仿攻击流程:
1.从目标作者At写的程序中提取代码风格属性。
2.从要改变的程序p中提取代码风格属性。
3.对比1和2中提取出的代码风格属性,找出程序p需要变换部分的属性列表。
4.分别对属性列表中属性执行代码转换,以模仿目标作者At
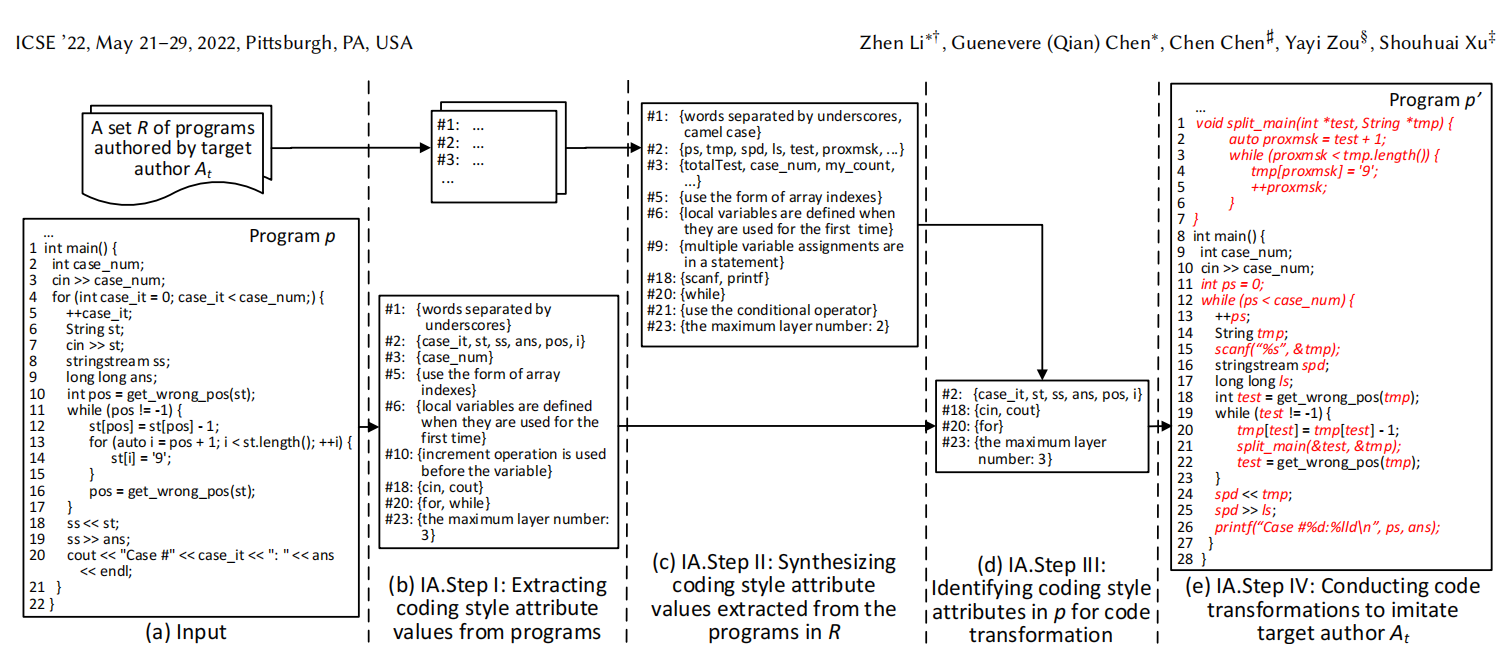
图1:一个为目标攻击生成C++程序𝑝’的例子(修改后的代码用红色和斜体突出显示)
而编码风格隐藏攻击是将作者库中作者风格以“编码风格模仿攻击流程”轮流执行一遍,最终选出错误归属判断概率最高的目标作者。
四、RoPGen设计与实现
图2是显示了RoPGen框架的训练阶段,该框架训练了𝑀的增强模型,用𝑀+表示。
RoPGen框架是一个增强的训练模型,包括数据增强(步骤1和步骤2)和梯度增强(步骤3)。由于第3步中的数据流共享③,我们使用实心蓝色箭头和红色虚线箭头来区分成熟网络和子网络的训练过程。原始的基于深度学习的训练模型(基线)用阴影框突出显示。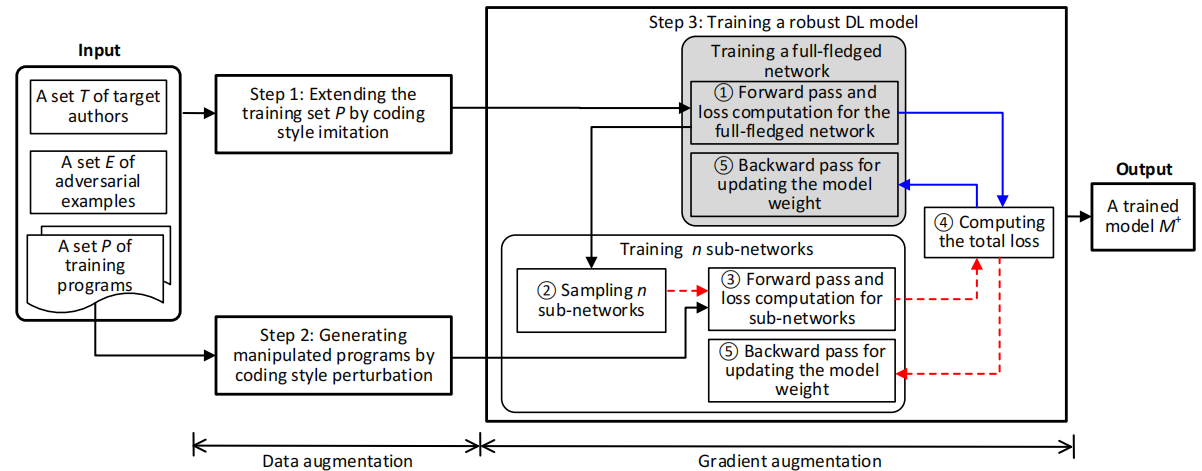
图2:RoPGen框架
1.数据增强
数据增强旨在增加训练集的数量和多样性,通过两种方式:
(i)模仿其他作者的编码风格;
step1中使用第三节中编码风格模仿攻击方式,对其他作者编码风格进行逐个模仿,生成扩展训练集。
(ii)用较小的扰动来改变程序的编码风格。
step2中,通过编码样式扰动生成变换的程序。
1.使用第三节中能成功攻击模型M的对抗样本,提取出它们的转换序列,最后我们利用转换序列来变换原数据集中的程序。
2.图1(a)中提取出原训练集代码中属性值,对属性进行逐个合理变换,生成变换程序。
2.梯度增强
梯度增强的目的是通过对梯度产生有意义的扰动来学习具有多种表示的鲁棒深度神经网络。我们通过对多个子网络进行采样来实现这一点,每个子网络涉及网络每一层的一定比例的节点。这使得一个更大的子网络在权重共享训练中包含一个更小的子网络的表示,使前者能够利用后者学习到的表示来构建具有不同表示的鲁棒网络。
3.训练流程
步骤1:通过模仿代码风格来扩展训练集
步骤2:通过代码风格属性扰动生成变换的程序
步骤3:训练一个稳健的深度学习模型𝑀+
步骤①:成熟网络的前向传递和损失计算。输入步骤1中得到的扩展数据集和原始数据集,使用标准计算成熟网络的损失。
步骤②:采样𝒏个子网络。我们对成熟网络每层的采用一定比例节点进行采样。这些子网络将用于从被变换的程序中学习不同的表示,并增强成熟网络的鲁棒性。
步骤③:子网络的正向通过和损耗计算。我们使用步骤2中获得的变换程序数据集作为每个子网络的输入,因为步骤2中的程序是通过较小的扰动生成的,因此适合于对成熟的网络进行微调。
步骤④:计算总损失。总损失𝐿𝑅𝑜𝑃𝐺𝑒𝑛是成熟网络损失和子网络损失的总和:
步骤⑤:更新模型的权重。我们进行反向传递,并利用总损失来更新模型的权值,它们由成熟的网络和𝑛子网络共享。这允许网络的不同部分学习不同的表示。迭代步骤①到⑤,直到模型收敛到𝑀+。
四、实验评估
我们在GCJ-C++数据集、GitHub-Java数据集、GitHub-C数据集、GCJ-Java数据集上进行了测试,使用RoPGen方法对比两种先进的深度学习归属判断模型DL-CAIS和PbNN(表2),实验验证我们的检测方法实现了较高的检测精度和速度。

表2:两种基于深度学习的归因方法在四个数据集上的准确性(度量单位:%)
我们的实验旨在回答三个研究问题(RQs):
RQ1:现有的基于深度学习的作者归属判断方法对已知和新的攻击鲁棒性?
Insight1:现有的基于深度学习的归因模型对已知的和新的攻击远没有鲁棒性;非目标攻击的成功率远高于目标攻击,因为攻击者在前一种情况下有更多的选择。

表3:两种基于深度学习的归属判断方法的攻击成功率,其中“-”表示该方法不能在数据集上使用(度量单位:%)。
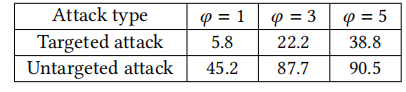
表5:DL-CAIS方法在GCJ-C++数据集上对不同𝜑-对手的攻击成功率(度量单位:%)
此表证明,应用更多的代码转换可以提高模仿或隐藏编码样式的成功率。
RQ2:使用RoPGen的作者归属判断框架对已知的和新的攻击鲁棒性?
Insight2:启用RoPGen的作者归因方法基本上比原始的基于深度学习的方法更健壮。特别是,对启用RoPGen的方法的靶向攻击和非靶向攻击的成功率平均分别降低了22.8%和41.0%。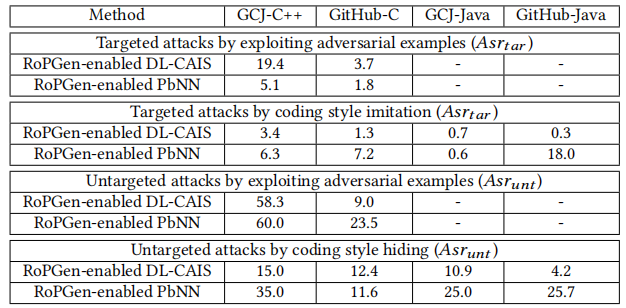
表7:启用RoPGen的归因方法的攻击成功率(指标单位:%)
RQ3:启用RoPGen的方法是否比其他对抗性训练方法更有效?
Insight3:由于数据增强和梯度增强,RoPGen在利用对抗性例子和编码风格模仿/隐藏的攻击方面明显优于其他对抗性训练方法。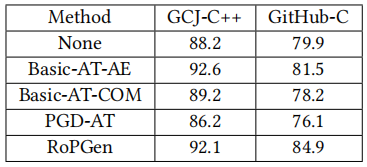
表10:在GCJ-C++和GitHub-C数据集上使用4种对抗性训练方法的DL-CAIS的准确性(度量单位:%)
Basic-AT-AE表示生成对抗样本方式;Basic-AT-COM表示生成对抗样本+模仿风格;PGD-AT表示单个编码样式属性的编码样式转换;RoPGen则表示使用RoPGen框架增强训练后的模型。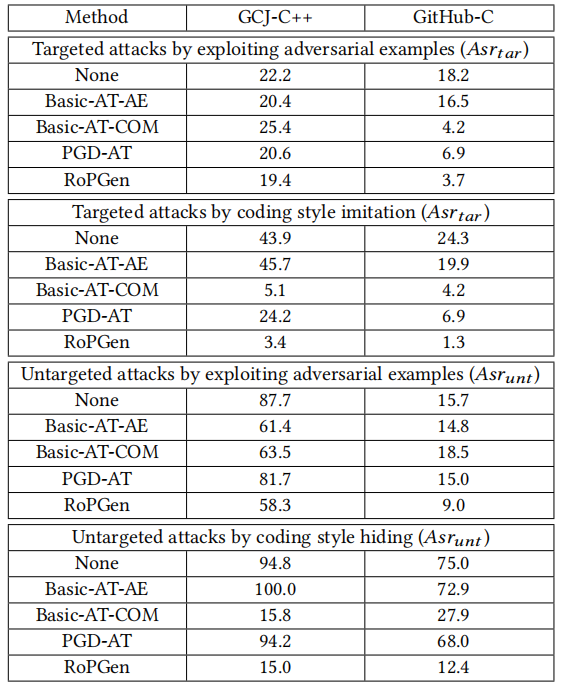
表11:DL-CAIS在GCJ-C++和GitHub-C数据集上的攻击成功率(度量单位:%)的攻击成功率
详细内容请参见:
Zhen Li, Guenevere (Qian)Chen, Chen Chen, Yayi Zou, Shouhuai Xu,RoPGen: Towards Robust Code Authorship Attribution via Automatic Coding Style Transformation,ICSE 2022,Sat, 12 Feb 2022 11:27:32 UTC,https://doi.org/10.48550/arXiv.2202.06043.

若有收获,就点个赞吧
0 人点赞
