1、什么是冷热架构?(实现原理)
传统的Elasticsearch集群中所有节点均采用相同的配置,然而Elasticsearch并没有对节点的规格一致性做要求,换而言之就是每个节点可以是任意规格,当然这样做会导致集群各节点性能不一致,影响集群稳定性。但是如果有规则的将集群的节点分成不同类型,部分是高性能的节点用于存储热点数据,部分是性能相对差些的大容量节点用于存储冷数据,却可以一方面保证热数据的性能,另一方面保证冷数据的存储,降低存储成本,这也是Elasticsearch冷热分离架构的基本思想,如下图为一个3热节点,2冷节点的冷热分离Elasticsearch集群: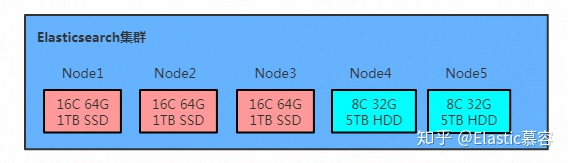
其中热节点为16核64GB 1TB SSD盘,用于满足对热数据对读写性能的要求,冷节点为8C32GB 5TB HDD在保证一定读写性能的基础之上提供了成本较低的大存储HDD盘来满足冷节点对数据存储的需求。
1.1 数据分布
集群节点异构后接着要考虑的是数据分布问题,即用户如何对冷热数据进行标识,并将冷数据移动到冷节点,热数据移动到热节点。
1.2节点指定冷热属性
仅仅将不同的节点设置为不同的规格还不够,为了能明确区分出哪些节点是热节点,哪些节点是冷节点,需要为对应节点打标签。
=======================================================================
官方叫法: 热暖架构——“Hot-Warm” Architecture。
通俗解读: 热节点存放用户最关心的热数据; 温节点或者冷节点存放用户不太关心或者关心优先级低的冷数据或者暖数据。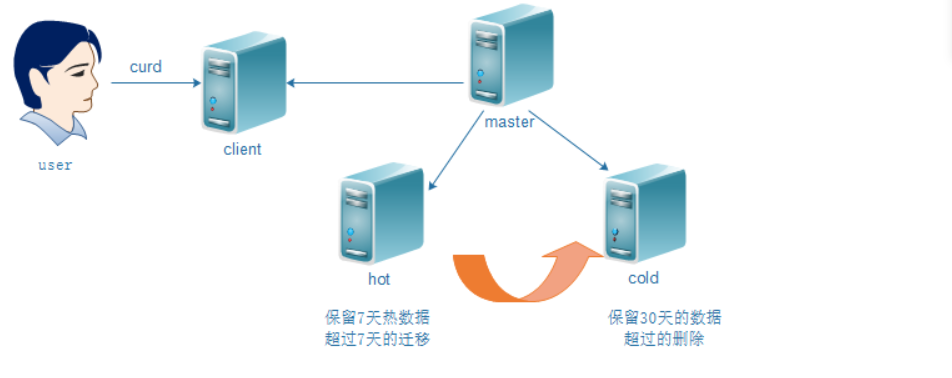
1.1 官方解读冷热架构
冷热架构是一项十分强大的功能,能够让您将 Elasticsearch 部署划分为“热”数据节点和“冷”数据节点。
- 热数据节点处理所有新输入的数据,并且存储速度也较快,以便确保快速地采集和检索数据。
- 冷节点的存储密度则较大,如需在较长保留期限内保留日志数据,不失为一种具有成本效益的方法。
将这两种类型的数据节点结合到一起后,您便能够有效地处理输入数据,并将其用于查询,同时还能在节省成本的前提下在较长时间内保留数据。
此架构对日志用例来说尤其大有帮助,因为在日志用例中,人们的大部分精力都会专注于近期的日志(例如最近两周),而较早的日志(由于合规性或者其他原因仍需要保留)则可以接受较慢的查询时间。
1.2 典型应用场景
一句话: 在成本有限的前提下,让客户关注的实时数据和历史数据硬件隔离, 最大化解决客户反应的响应时间慢的问题。
业务场景描述:
每日增量6TB日志数据,高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。

若有收获,就点个赞吧
0 人点赞
