synchronized
synchronided是java语言级别的关键字,用来对临界区代码加锁,是一种可重入的**互斥锁。**<br /> 它由JVM层面提供实现,是java中最通用的加锁方式,它在最初的实现方式是需要OS用户态到内核态的切换,所以性能不高,一般称之为**重量级锁,**<br /> 随着JDK的不断升级,JVM对synchronized的加锁方式进行了优化,性能方面跟ReentrantLock不逞多让,这方面的优化成为**锁的升级。**
作用
在静态方式上使用synchronized,锁住的对象是当前类对象
T.class(假设当前类为T.java)public synchronized static void jump() {}
在普通方法上使用synchronized,锁住的对象是当前类的实例对象
this
public synchronized void talk() {}
synchronized代码块
通常有synchronized关键字加一个java的对象(锁)包括住临界代码块
private Object object = new Object();public void talk() {synchronized (object) {}}
对象锁
对象锁其实就是上文提到的锁住的对象中对象,java中的对象锁是通过对象头的Mark Word来实现的
对象组成
对象由三部分组成,分别是对象头,对象体,填充区三部分组成,java虚拟机规范规定了一个对象必须是8byte的整数倍,所以需要填充区补充不足的部分
对象头
对象头通常是不定长的,它通常有Mark Word和KClass Word两部分组成,如果对象是数组时,它还需要额外的空间存储数组的长度(64位JVM下占64位,当开启压缩指针-XX:+UseCompressedOops时,32位)
对象头的布局:
|--------------------------------------------------------------------------------------------------------------|| Object Header (128 bits) ||--------------------------------------------------------------------------------------------------------------|| Mark Word (64 bits) | Klass Word (64 bits) ||--------------------------------------------------------------------------------------------------------------|| unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object ||----------------------------------------------------------------------|--------|------------------------------|| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object ||----------------------------------------------------------------------|--------|------------------------------|| ptr_to_lock_record:62 | lock:2 | OOP to metadata object ||----------------------------------------------------------------------|--------|------------------------------|| ptr_to_heavyweight_monitor:62 | lock:2 | OOP to metadata object ||----------------------------------------------------------------------|--------|------------------------------|| | lock:2 | OOP to metadata object ||--------------------------------------------------------------------------------------------------------------|
lock: 2bit,锁状态标记位,该标记的值不同,代表着不同的对象锁所处的不同锁状态。
biased_lock:1bit,偏向锁标记位,为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。
--------------------------------------------------------------------------------| biased_lock(bit) | lock(bit) | 锁|-------------------------------------------------------------------------------|| 0 | 01 | 无锁|-------------------------------------------------------------------------------|| 1 | 01 | 偏向锁|-------------------------------------------------------------------------------|| | 00 | 轻量级锁|-------------------------------------------------------------------------------|| | 10 | 重量级锁|-------------------------------------------------------------------------------|| | 11 | GC|-------------------------------------------------------------------------------|
age:4bit,标识对象的分代年龄,所以分代年龄最大为15
identity_hashcode :对象标识Hash码,采用延迟加载技术。当调用 hashCode() _toString()_ System.identityHashCode() 方法 ,计算出hash后,并会将结果写到该对象头中
thread :持有偏向锁的线程ID和其他信息。这个线程ID并不是JVM分配的线程ID号,和Java Thread中的ID是两个概念
epoch :偏向时间戳
ptr_to_lock_record:指向栈中锁记录的指针
Lock Record
当线程获取到轻量级锁后,会在当前线程的栈帧中显式或隐式创建一个Lock Record数据结构,
Lock Record包含两部分数据:
- 锁对象的原始mark word
- 被锁对象的元数据引用
Lock Record作用:
- 持有displaced word(mark word)和锁住对象的元数据;
- 解释器使用lock record来检测非法的锁状态;
- 隐式地充当锁重入机制的计数器
ptr_to_heavyweight_monitor:指向管程Monitor的指针
当对象被锁时,假如此时对象hashcode已经被计算了?那么根据上面的对象头信息显示,没有存储hashcode的地方,轻量级锁中,hashcode被复制到了Lock Record中的mark word中,重量级锁hashcode被移动到了锁对象关联的monitor对象上。
monitor对象
Monitor其实是一种同步工具、同步机制,在Java中,Object 类本身就是监视者对象,Java 对于 Monitor Object 模式做了内建的支持,即每一个Java对象是天生的Monitor,每一个Java对象都有成为Monitor的潜质。
并且同时只能有**一个**线程可以获得该对象monitor的所有权。在线程进入时通过monitorenter尝试取得对象monitor所有权,退出时通过monitorexit释放对象monitor所有权。
注:通常观察synchronized byte code时都会看到一个monitorenter对应两个monitorexit,分别表示正常退出和异常退出,所以当抛异常时,也是能正常解锁的,当使用reentrantlock的时候释放锁必须放在finally代码块中
_
Monitor 是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。
每一个被锁住的对象都会和一个monitor关联(对象头的MarkWord中的LockWord(ptr_to_heavyweight_monitor)指向monitor的起始地址),同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。
monitor数据结构:
- Owner:初始时为NULL表示当前没有任何线程拥有该monitor record,当线程成功拥有该锁后保存线程唯一标识,当锁被释放时又设置为NULL;
- EntryQ:关联一个系统互斥锁(mutex),阻塞所有试图锁住monitor record失败的线程。
- RcThis:表示blocked或waiting在该monitor record上的所有线程的个数。
- Nest:用来实现重入锁的计数。
- HashCode:保存从对象头拷贝过来的HashCode值(可能还包含GC age)。
- Candidate:用来避免不必要的阻塞或等待线程唤醒,因为每一次只有一个线程能够成功拥有锁,如果每次前一个释放锁的线程唤醒所有正在阻塞或等待的线程,会引起不必要的上下文切换(从阻塞到就绪然后因为竞争锁失败又被阻塞)从而导致性能严重下降。Candidate只有两种可能的值,0表示没有需要唤醒的线程,1表示要唤醒一个继任线程来竞争锁
锁优化
jvm对锁的优化,引入了如自旋、适应性自旋、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销,使得synchronized的性能大幅提升
自旋锁
是轻量级锁,当线程在获取锁失败的情况下,通过自旋一定次数(默认10次,通过-XX:PreBlockSpin设置)等待其他线程释放锁,这样让cpu执行空指令而不是让等待锁的线程阻塞,等待其他线程释放锁后再将其唤醒。java线程是映射到OS的线程上,所以这样的操作避免用户态和内核态的来回切换(heavy weight lock),同时不会让等待线程一直占用cpu空跑。基于大多数锁生命周期内,是不存在竞争的,所以引入了自旋锁。
适应性自旋锁
是对自旋锁进一步的优化,自适应说明自旋锁的自旋次数不再是固定的,而是由前一次获取锁的自旋时间,和持有锁的线程的状态来决定,如果同一个锁对象刚刚有线程通过自旋获取到了锁,那么JVM就认为当前线程也有机会获取到锁,就允许它自旋相对更长时间等待锁,比如说100次。如果很少有线程通过自旋获得锁,那就没有必要浪费cpu资源空转了,直接使用重量级锁。
锁消除
锁消除是是虚拟机即时编译器(jit)运行过程中,基于逃逸技术,对需要加锁的代码进行锁消除。如果这段代码使用到的数据不可能被其他线程共享,它就可以被当作栈上数据对待,认为是线程私有的,所以,这部分操作就没有必要加锁,通常情况下,这种加锁操作是jdkAPI提供的,例如字符串拼接,在jdk1.5前后优化成StringBuffer,1.6后优化成StringBuilder
public String concat(String a, String b ,String c){StringBuffer sb = new StringBuffer();sb.append(a).append(b).append(c);return sb.toString();}
因为StringBuffer所有方法都是synchronized的方法,当在方法cancat中使用sb对象拼接字符串时,它的动态作用域被限定在concat()方法中,sb引用不会逃逸到方法之外被其他线程引用到,那么这段代码经过JIT编译后执行,锁就可以被安全的消除了。
注:如果这段代码是由解释器解释执行,仍然会加锁。
锁粗化
加锁操作通常都会要求被包括的代码段尽可能的短,只对需要不同的操作加锁,保证锁能尽快的被释放,减少其他线程的等待时间,这时毫无疑问的。但是有些情况比如对循环体内的某个变量操作进行加锁,那么程序就会频繁的对同一个锁对象加锁,解锁,即使没有其他线程竞争,这种频繁的加解锁同样浪费性能,所以,JVM对像这种情况的加锁,就会优化加锁操作到循环外,这样只加一次锁就可以了。
偏向锁
如果说轻量级锁是无竞争的情况下采用CAS取消除同步使用互斥量,偏向锁则更进一步,是要把无竞争情况下的同步都省略掉。它偏向与第一次使用对象锁的线程,如果一直都是这一个线程获取锁,那将直接执行同步代码,该线程将不需要再进行同步,而一旦有其他线程尝试获取偏向锁,那么锁将根据锁状态决定是否撤销偏向锁,恢复成无锁,或者升级为轻量级锁。
偏向锁可以提升带有同步,但无线程竞争程序的性能,对于经常有多个线程访问锁的程序来说,它是无用的,可以通过 -XX:-UsebiasedLocking 禁止使用偏向锁优化
注:如果一个锁对象进行过hash计算,那么它永远无法进入偏向锁状态;如果处于偏向锁状态时,同时又要求计算它的hash,那么锁将直接升级为重量级锁。
锁升级过程
可参考此图,大致流程正确,个别细节有待商榷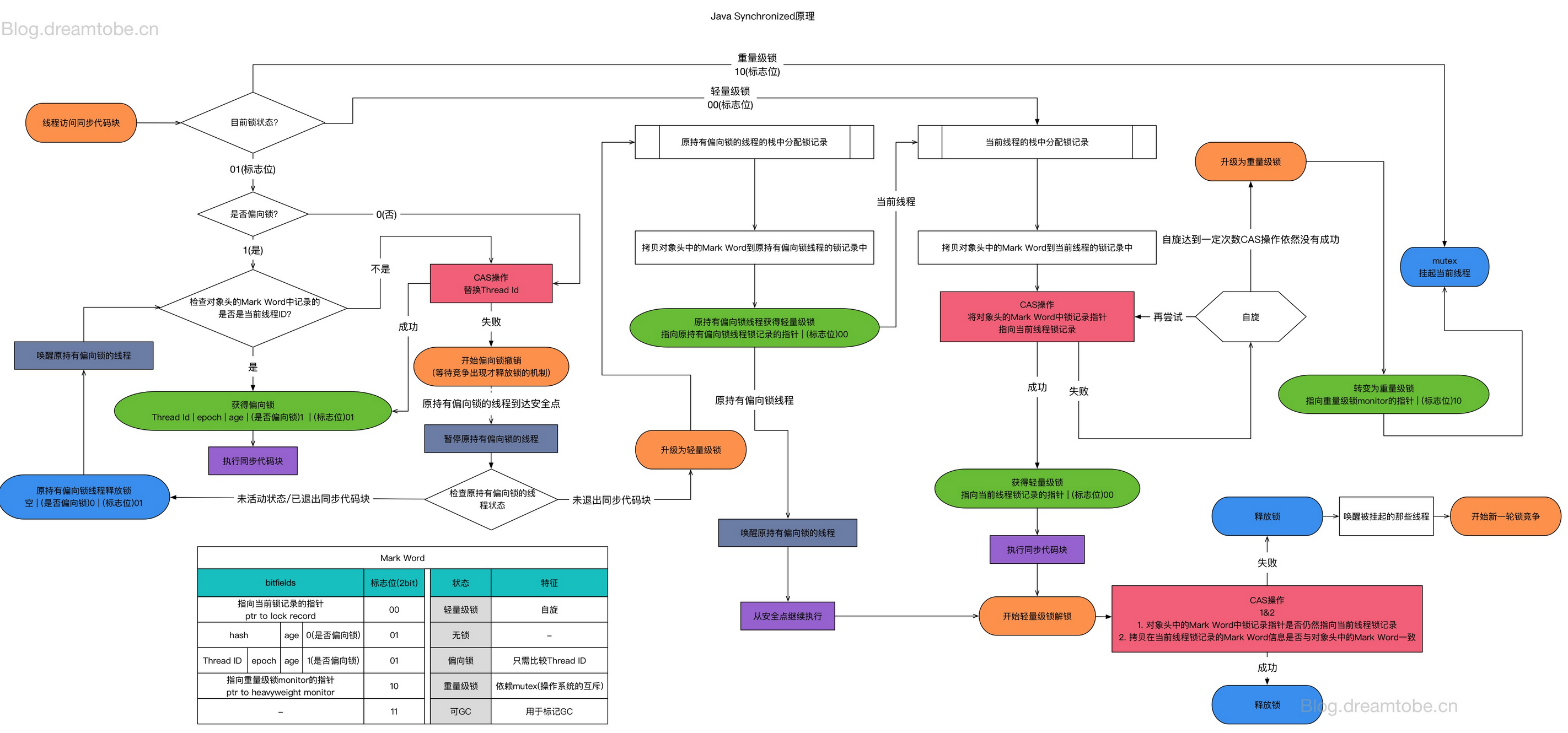
Volatile
volatile是跟synchronized一样,也是java中的关键字,不过它代表的含义跟synchronized还是有很大不同的,这单词含义是“易变的,不稳定的”,很多人认为它是synchronized的简化版,其实,不然,它并不能保证数据的原子性,它可以保证数据的可见性,以及禁止指令重排序
**
可见性
volatile声明的变量可以保证可见性,当使用volatile变量(use)时,会先从主存read变量的最新值,load到本地内存中变量副本中,当修改本地内存中值后,会先store,write到主内存中,所以其他线程都能看到最新的值。
**
缓存行:
当处理器加载主存数据到缓存时,是按块加载的,这一个“块”数据称为缓存行,他是cpu加载主存数据到缓存的最小单位,一般是64byte(intel),缓存行的大小是一个折衷值,因为缓存行越大,局部型空间效率越高,读取时间慢,缓存行越小,局部性空间效率越低,读取时间快。
当多线程修改缓存行中的变量值,缓存一致性协议(MESI,MOSI,MSI,synapse,firefly等)使得其他处理器中的同一个缓存行失效(需要重新从主存加载缓存行),即使修改的数据不是同一个数据,这种不合理的资源竞争称为伪共享
频繁的缓存行失效会导致严重性能下降,所以有种编程思想叫缓存行对齐编程(long padding)**,实现方式是在目标属性前后各填充7个long类型的属性,这样来保证一个缓存行只有这一个有用的值,对他的操作不会导致其他处理器重新从主存读取缓存
private long a1,a2,a3,a4,a5,a6,a7; //cache line paddingprivate volatile long cursor = INITTIAL_CURSOR_VALUEprivate long b1,b2,b3,b4,b5,b6,b7; //cache line padding
JDK8提供了 @Contented 注解实现缓存行对齐,需要加VM参数 XX:-RestrictContented
有序性
JVM通过内存屏障保证volatile修饰属性的操作不会被指令重排优化
指令重排序并不是任意的重排,有依赖关系的指令不能被重排序,比如
int a = 5;int c= 0;int b = a + 5;
变量b依赖与变量a,b变量的赋值操作就不能跟变量a赋值操作重排序,变量c的赋值操作就可能被处理器排序优化
StoreStoreBarrier StoreLoadBarrier 和 LoadLoadBarrier LoadStoreBarrier
从OS层面来看,volatile的内存屏障是通过lock addl $0x0 (%esp)指令完成的,这个指令是让esp寄存器的值加0,这是一个空操作,其实用到的是lock指令,它作用就是将本处理器中值刷新到主存,让其他内核使用到同一块内存的缓存失效,重新从主存读取新缓存行。这就是volatile变量与普通变量的区别,它立刻把新值同步到主存,使用前从主存取新值
在方法内部,所有依赖变量赋值操作结果的代码,jvm都能保证其能正确的执行,不被重排序,但是jvm不保证其变量赋值操作顺序跟代码一致,这就是java内存模型中描述的Within-Thread-As-If-Serial-Semantics
java中的天然有序性总结,在一个线程内部看,所有操作都是有序的(as-if-serial),在其他线程看,所有操作都是无序的(指令重排,工作内存和主存同步延迟)
修饰引用类型
volatile修饰引用类型时,当引用类型指向的对象的属性变更的时候,其他线程对此对象的变化不能够及时的观察到,所以一般用volatile修饰基础数据类型,慎用它修饰引用类型
JAVA中先行性规则
这些规则是天然发生的,无需任何同步操作
- 程序次序规则,program order rule,程序中控制流顺序,书写在前的先行发生在书写在后,控制流顺序并不是代码顺序,因为分支,循环等
- 管程锁定规则,monitor lock rule lock()先行与unlock()
- volatile规则,写操作先行于时间靠后的依赖此变量的读操作
- 线程启动规则,start()操作先行于线程中的每个动作
- 线程终止规则,线程中的所有操作先行于对此线程的终止检测,通过Thread::join()是否结束,Thread::isAlive()检测
- 线程终端规则,interrupt()方法先行于代码中检测到到终端时间发生
- 对象终结规则,对象初始化先行于finalize()方法
- 传递性规则,A先行与B,B先行于C,那么A先行与C
参考:https://www.jianshu.com/p/b516a981a1a7
深入理解JAVA虚拟机第三版

若有收获,就点个赞吧
0 人点赞
